 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLook Further: Socially-Compliant Navigation System in Residential Buildings
May 26, 2026The distance at which a mobile robot reacts to a person strongly impacts various qualities of the human-robot interaction. In this paper, we focus on the navigation of a mobile delivery robot platform in a residential indoor hallway environment. Social navigation methods typically focus on avoiding uncomfortable human-robot interactions, such as when a robot encroaches on someone's personal space. Since personal space has been shown to be in the range of just a few meters, social navigation methods typically focus on deconflicting and resolving these short-range interactions. In this work, however, we demonstrate that by extending the reaction distance to over eight meters, far beyond the typical interaction distance, we can improve the human's perception of the robot's motion. We introduce the Proactive Lane-Changing (PLC) motion pattern and a navigation system that leverages it to react to people at an increased distance. This pattern consists of changing the robot's lateral position as it navigates down the hallway from the center to the side at an eight-meter distance from an oncoming person. We conducted a user study with 42 participants to assess their impressions of the delivery robot based on three service objectives: safety, smoothness, and politeness. In the straight hallway scenario (Frontal Approach), results showed significant improvement in each of these three objectives compared to typical motion patterns found in the literature: slowing down, stopping, and reactive collision avoidance in the proximity of a person. In contrast, in the intersection (Blind Corner) scenarios, none of the approaches performed significantly better than any other, with participants having a diverse range of preferences among robot motion patterns.
* 2025 ACM/IEEE International Conference on Human-Robot Interaction
Voxtral TTS
Mar 26, 2026We introduce Voxtral TTS, an expressive multilingual text-to-speech model that generates natural speech from as little as 3 seconds of reference audio. Voxtral TTS adopts a hybrid architecture that combines auto-regressive generation of semantic speech tokens with flow-matching for acoustic tokens. These tokens are encoded and decoded with Voxtral Codec, a speech tokenizer trained from scratch with a hybrid VQ-FSQ quantization scheme. In human evaluations conducted by native speakers, Voxtral TTS is preferred for multilingual voice cloning due to its naturalness and expressivity, achieving a 68.4\% win rate over ElevenLabs Flash v2.5. We release the model weights under a CC BY-NC license.
Voxtral Realtime
Feb 11, 2026We introduce Voxtral Realtime, a natively streaming automatic speech recognition model that matches offline transcription quality at sub-second latency. Unlike approaches that adapt offline models through chunking or sliding windows, Voxtral Realtime is trained end-to-end for streaming, with explicit alignment between audio and text streams. Our architecture builds on the Delayed Streams Modeling framework, introducing a new causal audio encoder and Ada RMS-Norm for improved delay conditioning. We scale pretraining to a large-scale dataset spanning 13 languages. At a delay of 480ms, Voxtral Realtime achieves performance on par with Whisper, the most widely deployed offline transcription system. We release the model weights under the Apache 2.0 license.
NeuroCUT: A Neural Approach for Robust Graph Partitioning
Oct 18, 2023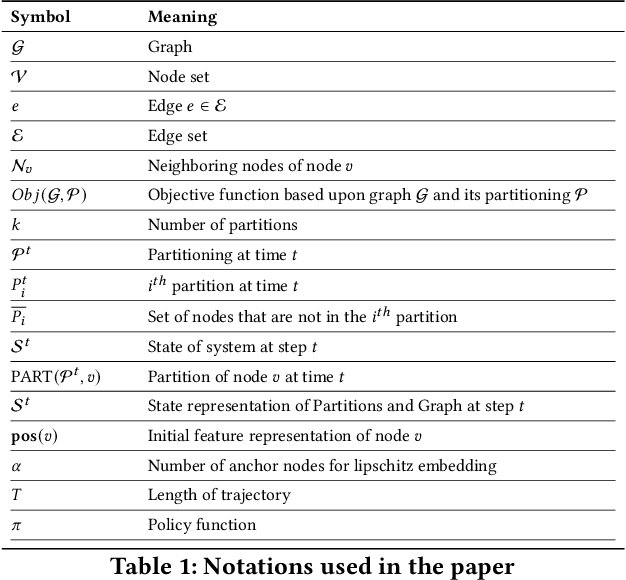
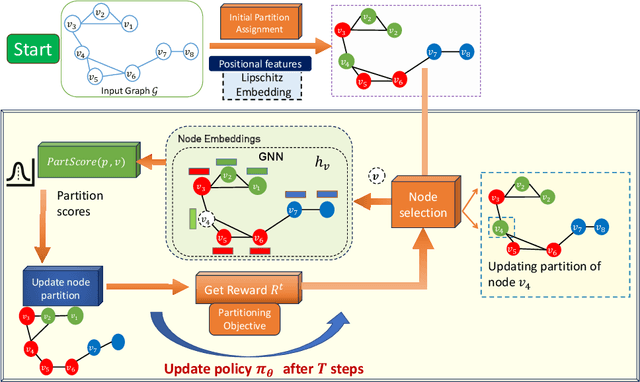
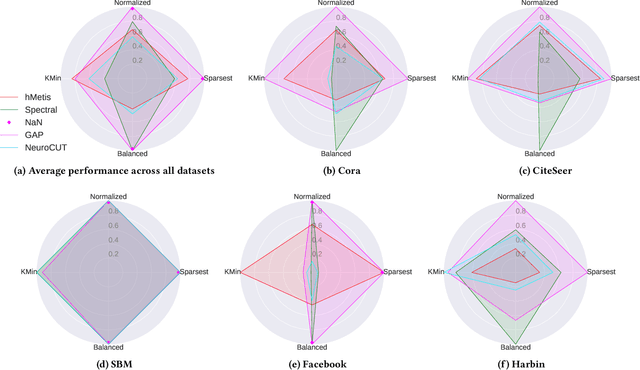
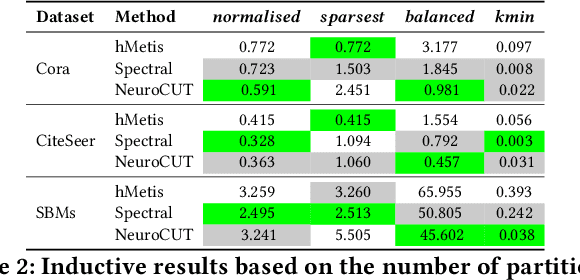
Graph partitioning aims to divide a graph into $k$ disjoint subsets while optimizing a specific partitioning objective. The majority of formulations related to graph partitioning exhibit NP-hardness due to their combinatorial nature. As a result, conventional approximation algorithms rely on heuristic methods, sometimes with approximation guarantees and sometimes without. Unfortunately, traditional approaches are tailored for specific partitioning objectives and do not generalize well across other known partitioning objectives from the literature. To overcome this limitation, and learn heuristics from the data directly, neural approaches have emerged, demonstrating promising outcomes. In this study, we extend this line of work through a novel framework, NeuroCut. NeuroCut introduces two key innovations over prevailing methodologies. First, it is inductive to both graph topology and the partition count, which is provided at query time. Second, by leveraging a reinforcement learning based framework over node representations derived from a graph neural network, NeuroCut can accommodate any optimization objective, even those encompassing non-differentiable functions. Through empirical evaluation, we demonstrate that NeuroCut excels in identifying high-quality partitions, showcases strong generalization across a wide spectrum of partitioning objectives, and exhibits resilience to topological modifications.
Temporal-Logic-Based Reward Shaping for Continuing Learning Tasks
Jul 03, 2020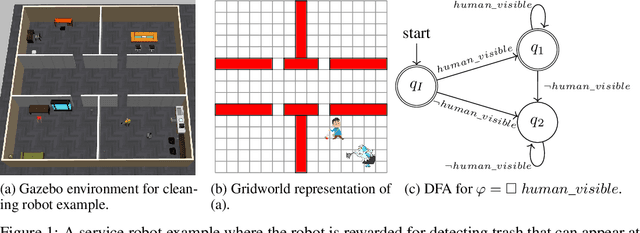
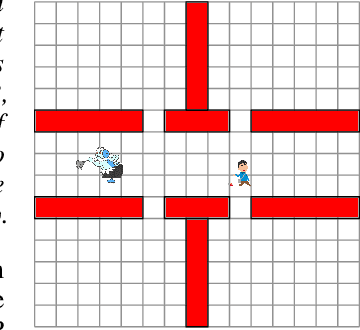
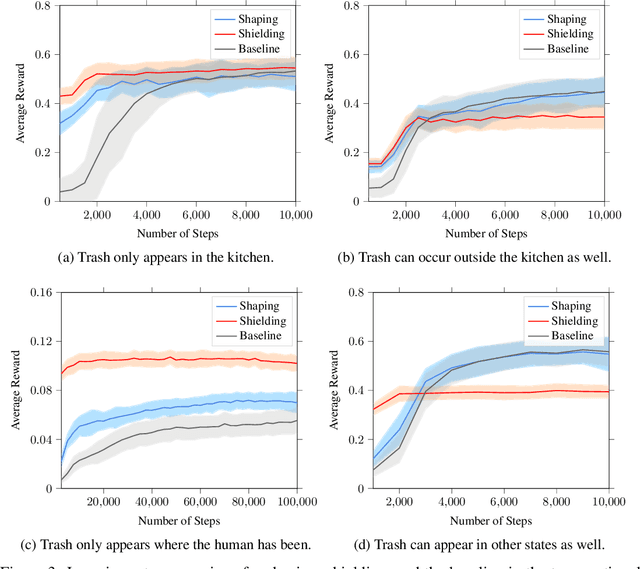
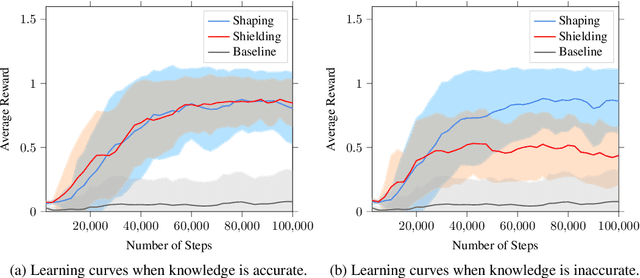
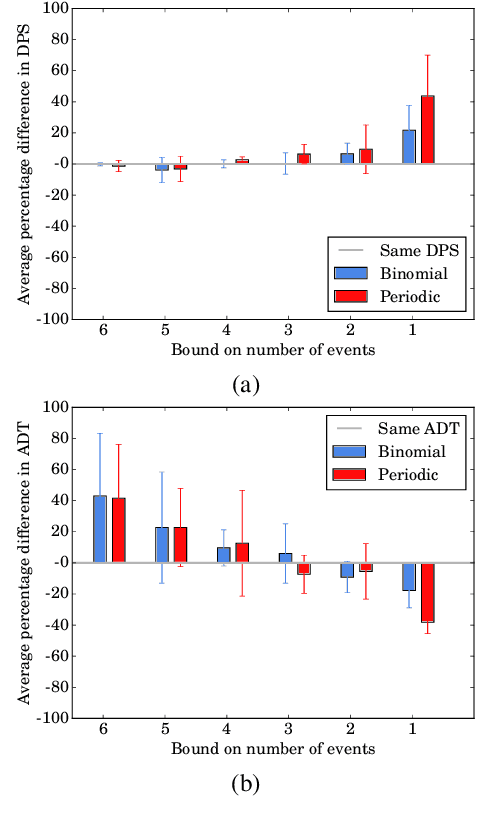
In continuing tasks, average-reward reinforcement learning may be a more appropriate problem formulation than the more common discounted reward formulation. As usual, learning an optimal policy in this setting typically requires a large amount of training experiences. Reward shaping is a common approach for incorporating domain knowledge into reinforcement learning in order to speed up convergence to an optimal policy. However, to the best of our knowledge, the theoretical properties of reward shaping have thus far only been established in the discounted setting. This paper presents the first reward shaping framework for average-reward learning and proves that, under standard assumptions, the optimal policy under the original reward function can be recovered. In order to avoid the need for manual construction of the shaping function, we introduce a method for utilizing domain knowledge expressed as a temporal logic formula. The formula is automatically translated to a shaping function that provides additional reward throughout the learning process. We evaluate the proposed method on three continuing tasks. In all cases, shaping speeds up the average-reward learning rate without any reduction in the performance of the learned policy compared to relevant baselines.
Deep R-Learning for Continual Area Sweeping
May 31, 2020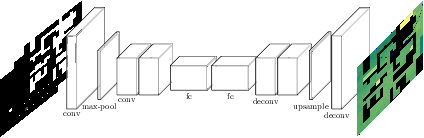


Coverage path planning is a well-studied problem in robotics in which a robot must plan a path that passes through every point in a given area repeatedly, usually with a uniform frequency. To address the scenario in which some points need to be visited more frequently than others, this problem has been extended to non-uniform coverage planning. This paper considers the variant of non-uniform coverage in which the robot does not know the distribution of relevant events beforehand and must nevertheless learn to maximize the rate of detecting events of interest. This continual area sweeping problem has been previously formalized in a way that makes strong assumptions about the environment, and to date only a greedy approach has been proposed. We generalize the continual area sweeping formulation to include fewer environmental constraints, and propose a novel approach based on reinforcement learning in a Semi-Markov Decision Process. This approach is evaluated in an abstract simulation and in a high fidelity Gazebo simulation. These evaluations show significant improvement upon the existing approach in general settings, which is especially relevant in the growing area of service robotics.
Solving Service Robot Tasks: UT Austin Villa@Home 2019 Team Report
Sep 14, 2019
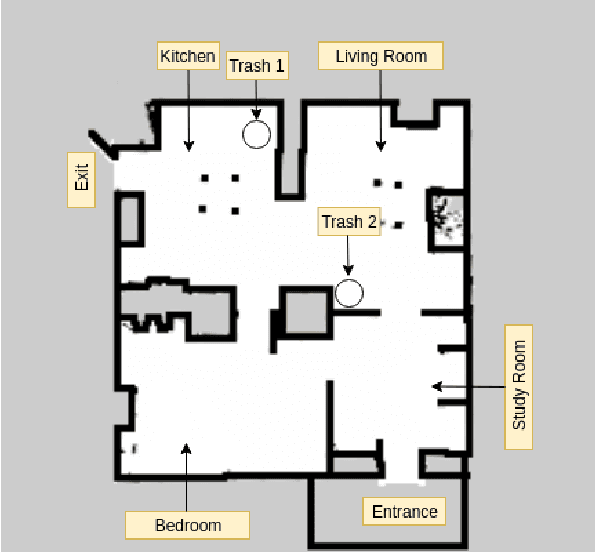
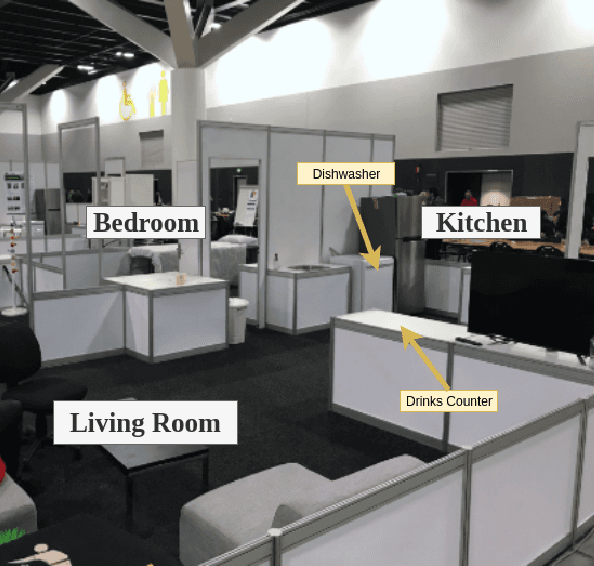

RoboCup@Home is an international robotics competition based on domestic tasks requiring autonomous capabilities pertaining to a large variety of AI technologies. Research challenges are motivated by these tasks both at the level of individual technologies and the integration of subsystems into a fully functional, robustly autonomous system. We describe the progress made by the UT Austin Villa 2019 RoboCup@Home team which represents a significant step forward in AI-based HRI due to the breadth of tasks accomplished within a unified system. Presented are the competition tasks, component technologies they rely on, our initial approaches both to the components and their integration, and directions for future research.
Interaction and Autonomy in RoboCup@Home and Building-Wide Intelligence
Oct 06, 2018



Efforts are underway at UT Austin to build autonomous robot systems that address the challenges of long-term deployments in office environments and of the more prescribed domestic service tasks of the RoboCup@Home competition. We discuss the contrasts and synergies of these efforts, highlighting how our work to build a RoboCup@Home Domestic Standard Platform League entry led us to identify an integrated software architecture that could support both projects. Further, naturalistic deployments of our office robot platform as part of the Building-Wide Intelligence project have led us to identify and research new problems in a traditional laboratory setting.