 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMixed-Initiative Dialog for Human-Robot Collaborative Manipulation
Aug 07, 2025Effective robotic systems for long-horizon human-robot collaboration must adapt to a wide range of human partners, whose physical behavior, willingness to assist, and understanding of the robot's capabilities may change over time. This demands a tightly coupled communication loop that grants both agents the flexibility to propose, accept, or decline requests as they coordinate toward completing the task effectively. We apply a Mixed-Initiative dialog paradigm to Collaborative human-roBot teaming and propose MICoBot, a system that handles the common scenario where both agents, using natural language, take initiative in formulating, accepting, or rejecting proposals on who can best complete different steps of a task. To handle diverse, task-directed dialog, and find successful collaborative strategies that minimize human effort, MICoBot makes decisions at three levels: (1) a meta-planner considers human dialog to formulate and code a high-level collaboration strategy, (2) a planner optimally allocates the remaining steps to either agent based on the robot's capabilities (measured by a simulation-pretrained affordance model) and the human's estimated availability to help, and (3) an action executor decides the low-level actions to perform or words to say to the human. Our extensive evaluations in simulation and real-world -- on a physical robot with 18 unique human participants over 27 hours -- demonstrate the ability of our method to effectively collaborate with diverse human users, yielding significantly improved task success and user experience than a pure LLM baseline and other agent allocation models. See additional videos and materials at https://robin-lab.cs.utexas.edu/MicoBot/.
CaT-BENCH: Benchmarking Language Model Understanding of Causal and Temporal Dependencies in Plans
Jun 22, 2024



Understanding the abilities of LLMs to reason about natural language plans, such as instructional text and recipes, is critical to reliably using them in decision-making systems. A fundamental aspect of plans is the temporal order in which their steps needs to be executed, which reflects the underlying causal dependencies between them. We introduce CaT-Bench, a benchmark of Step Order Prediction questions, which test whether a step must necessarily occur before or after another in cooking recipe plans. We use this to evaluate how well frontier LLMs understand causal and temporal dependencies. We find that SOTA LLMs are underwhelming (best zero-shot is only 0.59 in F1), and are biased towards predicting dependence more often, perhaps relying on temporal order of steps as a heuristic. While prompting for explanations and using few-shot examples improve performance, the best F1 result is only 0.73. Further, human evaluation of explanations along with answer correctness show that, on average, humans do not agree with model reasoning. Surprisingly, we also find that explaining after answering leads to better performance than normal chain-of-thought prompting, and LLM answers are not consistent across questions about the same step pairs. Overall, results show that LLMs' ability to detect dependence between steps has significant room for improvement.
Multimodal Contextualized Semantic Parsing from Speech
Jun 10, 2024



We introduce Semantic Parsing in Contextual Environments (SPICE), a task designed to enhance artificial agents' contextual awareness by integrating multimodal inputs with prior contexts. SPICE goes beyond traditional semantic parsing by offering a structured, interpretable framework for dynamically updating an agent's knowledge with new information, mirroring the complexity of human communication. We develop the VG-SPICE dataset, crafted to challenge agents with visual scene graph construction from spoken conversational exchanges, highlighting speech and visual data integration. We also present the Audio-Vision Dialogue Scene Parser (AViD-SP) developed for use on VG-SPICE. These innovations aim to improve multimodal information processing and integration. Both the VG-SPICE dataset and the AViD-SP model are publicly available.
A Survey of Robotic Language Grounding: Tradeoffs Between Symbols and Embeddings
May 21, 2024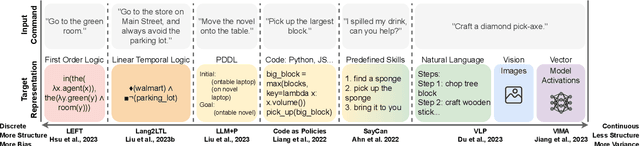

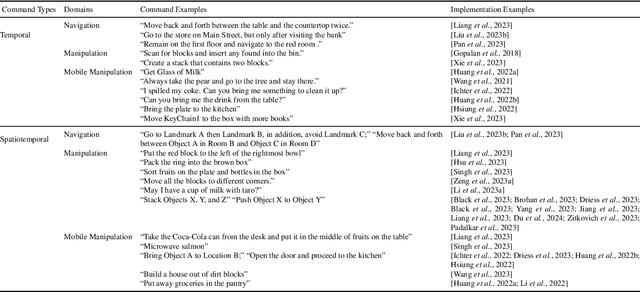
With large language models, robots can understand language more flexibly and more capable than ever before. This survey reviews recent literature and situates it into a spectrum with two poles: 1) mapping between language and some manually defined formal representation of meaning, and 2) mapping between language and high-dimensional vector spaces that translate directly to low-level robot policy. Using a formal representation allows the meaning of the language to be precisely represented, limits the size of the learning problem, and leads to a framework for interpretability and formal safety guarantees. Methods that embed language and perceptual data into high-dimensional spaces avoid this manually specified symbolic structure and thus have the potential to be more general when fed enough data but require more data and computing to train. We discuss the benefits and tradeoffs of each approach and finish by providing directions for future work that achieves the best of both worlds.
Natural Language Can Help Bridge the Sim2Real Gap
May 16, 2024



The main challenge in learning image-conditioned robotic policies is acquiring a visual representation conducive to low-level control. Due to the high dimensionality of the image space, learning a good visual representation requires a considerable amount of visual data. However, when learning in the real world, data is expensive. Sim2Real is a promising paradigm for overcoming data scarcity in the real-world target domain by using a simulator to collect large amounts of cheap data closely related to the target task. However, it is difficult to transfer an image-conditioned policy from sim to real when the domains are very visually dissimilar. To bridge the sim2real visual gap, we propose using natural language descriptions of images as a unifying signal across domains that captures the underlying task-relevant semantics. Our key insight is that if two image observations from different domains are labeled with similar language, the policy should predict similar action distributions for both images. We demonstrate that training the image encoder to predict the language description or the distance between descriptions of a sim or real image serves as a useful, data-efficient pretraining step that helps learn a domain-invariant image representation. We can then use this image encoder as the backbone of an IL policy trained simultaneously on a large amount of simulated and a handful of real demonstrations. Our approach outperforms widely used prior sim2real methods and strong vision-language pretraining baselines like CLIP and R3M by 25 to 40%.
Distilling Algorithmic Reasoning from LLMs via Explaining Solution Programs
Apr 11, 2024



Distilling explicit chain-of-thought reasoning paths has emerged as an effective method for improving the reasoning abilities of large language models (LLMs) across various tasks. However, when tackling complex tasks that pose significant challenges for state-of-the-art models, this technique often struggles to produce effective chains of thought that lead to correct answers. In this work, we propose a novel approach to distill reasoning abilities from LLMs by leveraging their capacity to explain solutions. We apply our method to solving competitive-level programming challenges. More specifically, we employ an LLM to generate explanations for a set of <problem, solution-program> pairs, then use <problem, explanation> pairs to fine-tune a smaller language model, which we refer to as the Reasoner, to learn algorithmic reasoning that can generate "how-to-solve" hints for unseen problems. Our experiments demonstrate that learning from explanations enables the Reasoner to more effectively guide program implementation by a Coder, resulting in higher solve rates than strong chain-of-thought baselines on competitive-level programming problems. It also outperforms models that learn directly from <problem, solution-program> pairs. We curated an additional test set in the CodeContests format, which includes 246 more recent problems posted after the models' knowledge cutoff.
Dialogue with Robots: Proposals for Broadening Participation and Research in the SLIVAR Community
Apr 01, 2024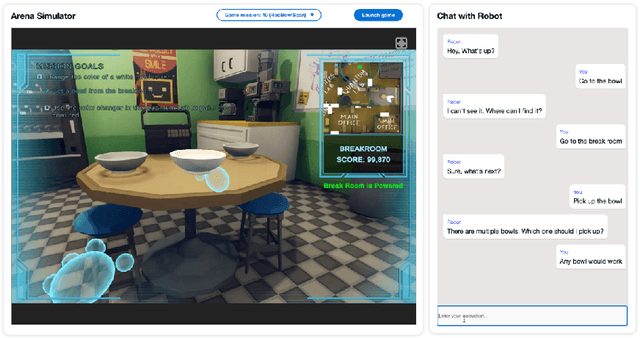
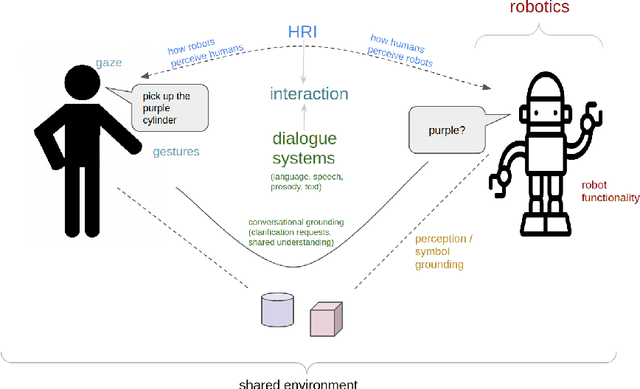
The ability to interact with machines using natural human language is becoming not just commonplace, but expected. The next step is not just text interfaces, but speech interfaces and not just with computers, but with all machines including robots. In this paper, we chronicle the recent history of this growing field of spoken dialogue with robots and offer the community three proposals, the first focused on education, the second on benchmarks, and the third on the modeling of language when it comes to spoken interaction with robots. The three proposals should act as white papers for any researcher to take and build upon.
When is Tree Search Useful for LLM Planning? It Depends on the Discriminator
Feb 16, 2024



In this paper, we examine how large language models (LLMs) solve multi-step problems under a language agent framework with three components: a generator, a discriminator, and a planning method. We investigate the practical utility of two advanced planning methods, iterative correction and tree search. We present a comprehensive analysis of how discrimination accuracy affects the overall performance of agents when using these two methods or a simpler method, re-ranking. Experiments on two tasks, text-to-SQL parsing and mathematical reasoning, show that: (1) advanced planning methods demand discriminators with at least 90% accuracy to achieve significant improvements over re-ranking; (2) current LLMs' discrimination abilities have not met the needs of advanced planning methods to achieve such improvements; (3) with LLM-based discriminators, advanced planning methods may not adequately balance accuracy and efficiency. For example, compared to the other two methods, tree search is at least 10--20 times slower but leads to negligible performance gains, which hinders its real-world applications. Code and data will be released at https://github.com/OSU-NLP-Group/llm-planning-eval.
Sparse Meets Dense: A Hybrid Approach to Enhance Scientific Document Retrieval
Jan 08, 2024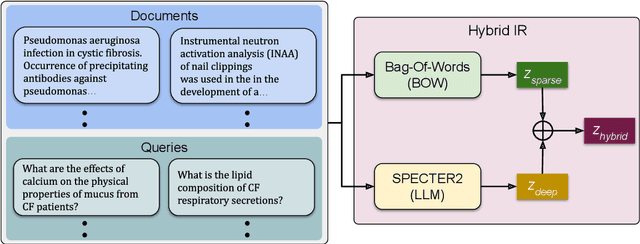
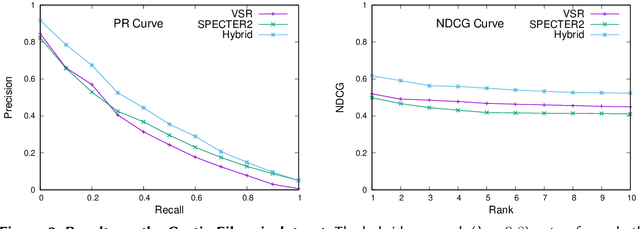
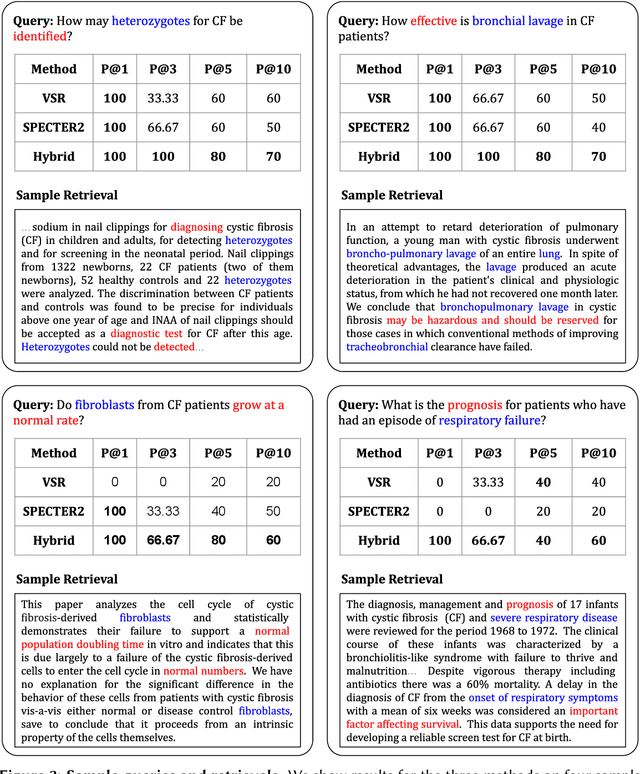
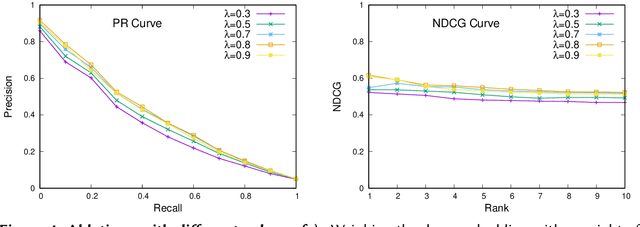
Traditional information retrieval is based on sparse bag-of-words vector representations of documents and queries. More recent deep-learning approaches have used dense embeddings learned using a transformer-based large language model. We show that on a classic benchmark on scientific document retrieval in the medical domain of cystic fibrosis, that both of these models perform roughly equivalently. Notably, dense vectors from the state-of-the-art SPECTER2 model do not significantly enhance performance. However, a hybrid model that we propose combining these methods yields significantly better results, underscoring the merits of integrating classical and contemporary deep learning techniques in information retrieval in the domain of specialized scientific documents.
What is the Best Automated Metric for Text to Motion Generation?
Sep 19, 2023



There is growing interest in generating skeleton-based human motions from natural language descriptions. While most efforts have focused on developing better neural architectures for this task, there has been no significant work on determining the proper evaluation metric. Human evaluation is the ultimate accuracy measure for this task, and automated metrics should correlate well with human quality judgments. Since descriptions are compatible with many motions, determining the right metric is critical for evaluating and designing effective generative models. This paper systematically studies which metrics best align with human evaluations and proposes new metrics that align even better. Our findings indicate that none of the metrics currently used for this task show even a moderate correlation with human judgments on a sample level. However, for assessing average model performance, commonly used metrics such as R-Precision and less-used coordinate errors show strong correlations. Additionally, several recently developed metrics are not recommended due to their low correlation compared to alternatives. We also introduce a novel metric based on a multimodal BERT-like model, MoBERT, which offers strongly human-correlated sample-level evaluations while maintaining near-perfect model-level correlation. Our results demonstrate that this new metric exhibits extensive benefits over all current alternatives.