 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBeyond Length: Context-Aware Expansion and Independence as Developmentally Sensitive Evaluation in Child Utterances
Feb 05, 2026Evaluating the quality of children's utterances in adult-child dialogue remains challenging due to insufficient context-sensitive metrics. Common proxies such as Mean Length of Utterance (MLU), lexical diversity (vocd-D), and readability indices (Flesch-Kincaid Grade Level, Gunning Fog Index) are dominated by length and ignore conversational context, missing aspects of response quality such as reasoning depth, topic maintenance, and discourse planning. We introduce an LLM-as-a-judge framework that first classifies the Previous Adult Utterance Type and then scores the child's response along two axes: Expansion (contextual elaboration and inferential depth) and Independence (the child's contribution to advancing the discourse). These axes reflect fundamental dimensions in child language development, where Expansion captures elaboration, clause combining, and causal and contrastive connectives. Independence captures initiative, topic control, decreasing reliance on adult scaffolding through growing self-regulation, and audience design. We establish developmental validity by showing age-related patterns and demonstrate predictive value by improving age estimation over common baselines. We further confirm semantic sensitivity by detecting differences tied to discourse relations. Our metrics align with human judgments, enabling large-scale evaluation. This shifts child utterance assessment from simply measuring length to evaluating how meaningfully the child's speech contributes to and advances the conversation within its context.
VISTA Score: Verification In Sequential Turn-based Assessment
Oct 30, 2025Hallucination--defined here as generating statements unsupported or contradicted by available evidence or conversational context--remains a major obstacle to deploying conversational AI systems in settings that demand factual reliability. Existing metrics either evaluate isolated responses or treat unverifiable content as errors, limiting their use for multi-turn dialogue. We introduce VISTA (Verification In Sequential Turn-based Assessment), a framework for evaluating conversational factuality through claim-level verification and sequential consistency tracking. VISTA decomposes each assistant turn into atomic factual claims, verifies them against trusted sources and dialogue history, and categorizes unverifiable statements (subjective, contradicted, lacking evidence, or abstaining). Across eight large language models and four dialogue factuality benchmarks (AIS, BEGIN, FAITHDIAL, and FADE), VISTA substantially improves hallucination detection over FACTSCORE and LLM-as-Judge baselines. Human evaluation confirms that VISTA's decomposition improves annotator agreement and reveals inconsistencies in existing benchmarks. By modeling factuality as a dynamic property of conversation, VISTA offers a more transparent, human-aligned measure of truthfulness in dialogue systems.
Winning Big with Small Models: Knowledge Distillation vs. Self-Training for Reducing Hallucination in QA Agents
Feb 26, 2025The deployment of Large Language Models (LLMs) in customer support is constrained by hallucination-generating false information-and the high cost of proprietary models. To address these challenges, we propose a retrieval-augmented question-answering (QA) pipeline and explore how to balance human input and automation. Using a dataset of questions about a Samsung Smart TV user manual, we demonstrate that synthetic data generated by LLMs outperforms crowdsourced data in reducing hallucination in finetuned models. We also compare self-training (fine-tuning models on their own outputs) and knowledge distillation (fine-tuning on stronger models' outputs, e.g., GPT-4o), and find that self-training achieves comparable hallucination reduction. We conjecture that this surprising finding can be attributed to increased exposure bias issues in the knowledge distillation case and support this conjecture with post hoc analysis. We also improve robustness to unanswerable questions and retrieval failures with contextualized "I don't know" responses. These findings show that scalable, cost-efficient QA systems can be built using synthetic data and self-training with open-source models, reducing reliance on proprietary tools or costly human annotations.
When is Tree Search Useful for LLM Planning? It Depends on the Discriminator
Feb 16, 2024



In this paper, we examine how large language models (LLMs) solve multi-step problems under a language agent framework with three components: a generator, a discriminator, and a planning method. We investigate the practical utility of two advanced planning methods, iterative correction and tree search. We present a comprehensive analysis of how discrimination accuracy affects the overall performance of agents when using these two methods or a simpler method, re-ranking. Experiments on two tasks, text-to-SQL parsing and mathematical reasoning, show that: (1) advanced planning methods demand discriminators with at least 90% accuracy to achieve significant improvements over re-ranking; (2) current LLMs' discrimination abilities have not met the needs of advanced planning methods to achieve such improvements; (3) with LLM-based discriminators, advanced planning methods may not adequately balance accuracy and efficiency. For example, compared to the other two methods, tree search is at least 10--20 times slower but leads to negligible performance gains, which hinders its real-world applications. Code and data will be released at https://github.com/OSU-NLP-Group/llm-planning-eval.
Text-to-SQL Error Correction with Language Models of Code
May 22, 2023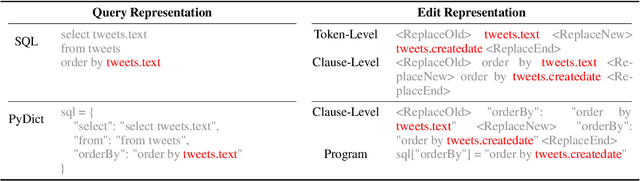
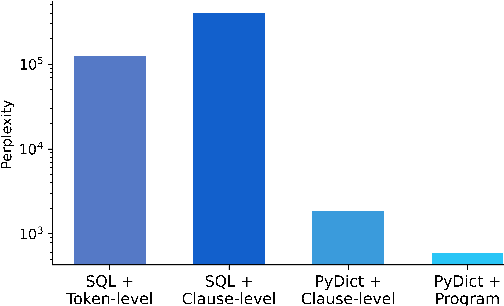
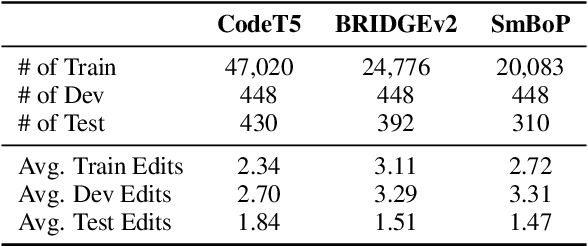
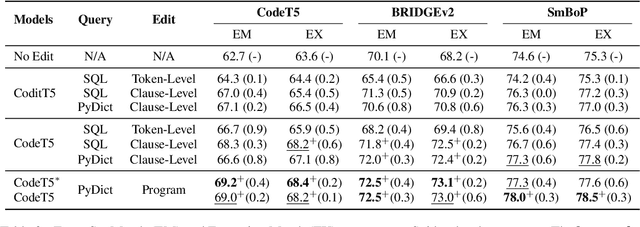
Despite recent progress in text-to-SQL parsing, current semantic parsers are still not accurate enough for practical use. In this paper, we investigate how to build automatic text-to-SQL error correction models. Noticing that token-level edits are out of context and sometimes ambiguous, we propose building clause-level edit models instead. Besides, while most language models of code are not specifically pre-trained for SQL, they know common data structures and their operations in programming languages such as Python. Thus, we propose a novel representation for SQL queries and their edits that adheres more closely to the pre-training corpora of language models of code. Our error correction model improves the exact set match accuracy of different parsers by 2.4-6.5 and obtains up to 4.3 point absolute improvement over two strong baselines. Our code and data are available at https://github.com/OSU-NLP-Group/Auto-SQL-Correction.
GEMv2: Multilingual NLG Benchmarking in a Single Line of Code
Jun 24, 2022



Evaluation in machine learning is usually informed by past choices, for example which datasets or metrics to use. This standardization enables the comparison on equal footing using leaderboards, but the evaluation choices become sub-optimal as better alternatives arise. This problem is especially pertinent in natural language generation which requires ever-improving suites of datasets, metrics, and human evaluation to make definitive claims. To make following best model evaluation practices easier, we introduce GEMv2. The new version of the Generation, Evaluation, and Metrics Benchmark introduces a modular infrastructure for dataset, model, and metric developers to benefit from each others work. GEMv2 supports 40 documented datasets in 51 languages. Models for all datasets can be evaluated online and our interactive data card creation and rendering tools make it easier to add new datasets to the living benchmark.
Towards Transparent Interactive Semantic Parsing via Step-by-Step Correction
Oct 15, 2021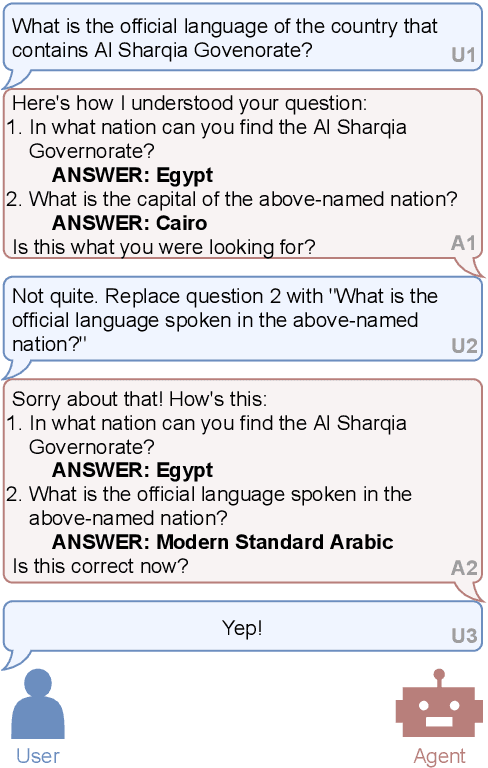

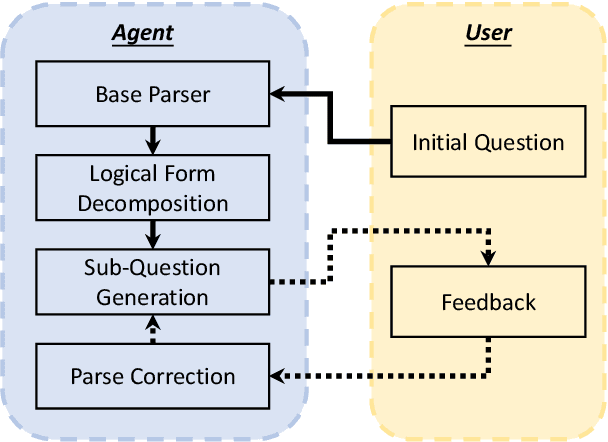
Existing studies on semantic parsing focus primarily on mapping a natural-language utterance to a corresponding logical form in one turn. However, because natural language can contain a great deal of ambiguity and variability, this is a difficult challenge. In this work, we investigate an interactive semantic parsing framework that explains the predicted logical form step by step in natural language and enables the user to make corrections through natural-language feedback for individual steps. We focus on question answering over knowledge bases (KBQA) as an instantiation of our framework, aiming to increase the transparency of the parsing process and help the user appropriately trust the final answer. To do so, we construct INSPIRED, a crowdsourced dialogue dataset derived from the ComplexWebQuestions dataset. Our experiments show that the interactive framework with human feedback has the potential to greatly improve overall parse accuracy. Furthermore, we develop a pipeline for dialogue simulation to evaluate our framework w.r.t. a variety of state-of-the-art KBQA models without involving further crowdsourcing effort. The results demonstrate that our interactive semantic parsing framework promises to be effective across such models.
Best Practices for Data-Efficient Modeling in NLG:How to Train Production-Ready Neural Models with Less Data
Nov 08, 2020Natural language generation (NLG) is a critical component in conversational systems, owing to its role of formulating a correct and natural text response. Traditionally, NLG components have been deployed using template-based solutions. Although neural network solutions recently developed in the research community have been shown to provide several benefits, deployment of such model-based solutions has been challenging due to high latency, correctness issues, and high data needs. In this paper, we present approaches that have helped us deploy data-efficient neural solutions for NLG in conversational systems to production. We describe a family of sampling and modeling techniques to attain production quality with light-weight neural network models using only a fraction of the data that would be necessary otherwise, and show a thorough comparison between each. Our results show that domain complexity dictates the appropriate approach to achieve high data efficiency. Finally, we distill the lessons from our experimental findings into a list of best practices for production-level NLG model development, and present them in a brief runbook. Importantly, the end products of all of the techniques are small sequence-to-sequence models (2Mb) that we can reliably deploy in production.
Constrained Decoding for Neural NLG from Compositional Representations in Task-Oriented Dialogue
Jun 17, 2019

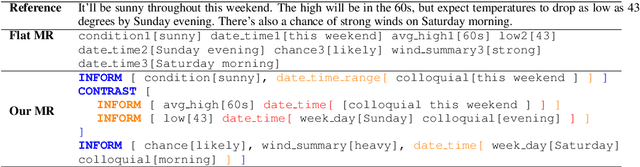
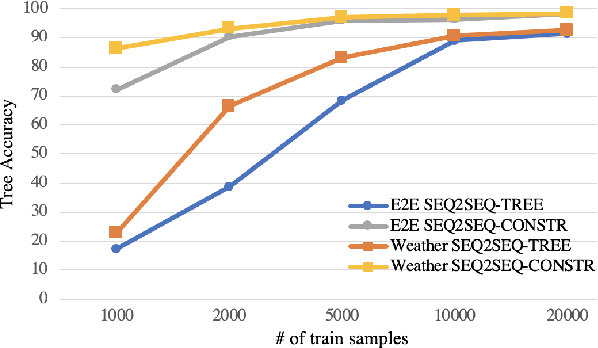
Generating fluent natural language responses from structured semantic representations is a critical step in task-oriented conversational systems. Avenues like the E2E NLG Challenge have encouraged the development of neural approaches, particularly sequence-to-sequence (Seq2Seq) models for this problem. The semantic representations used, however, are often underspecified, which places a higher burden on the generation model for sentence planning, and also limits the extent to which generated responses can be controlled in a live system. In this paper, we (1) propose using tree-structured semantic representations, like those used in traditional rule-based NLG systems, for better discourse-level structuring and sentence-level planning; (2) introduce a challenging dataset using this representation for the weather domain; (3) introduce a constrained decoding approach for Seq2Seq models that leverages this representation to improve semantic correctness; and (4) demonstrate promising results on our dataset and the E2E dataset.
A Computational Approach to Aspectual Composition
Jul 01, 1995In this paper, I argue, contrary to the prevailing opinion in the linguistics and philosophy literature, that a sortal approach to aspectual composition can indeed be explanatory. In support of this view, I develop a synthesis of competing proposals by Hinrichs, Krifka and Jackendoff which takes Jackendoff's cross-cutting sortal distinctions as its point of departure. To show that the account is well-suited for computational purposes, I also sketch an implemented calculus of eventualities which yields many of the desired inferences. Further details on both the model-theoretic semantics and the implementation can be found in (White, 1994).
* 15 pages