 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Whole Truth and Nothing But the Truth: Faithful and Controllable Dialogue Response Generation with Dataflow Transduction and Constrained Decoding
Sep 16, 2022
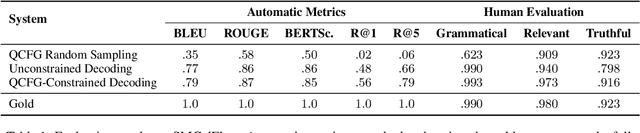
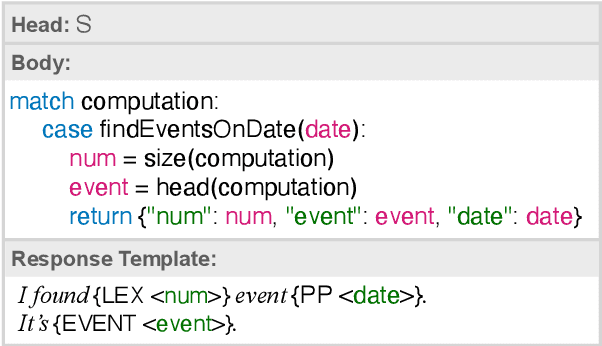
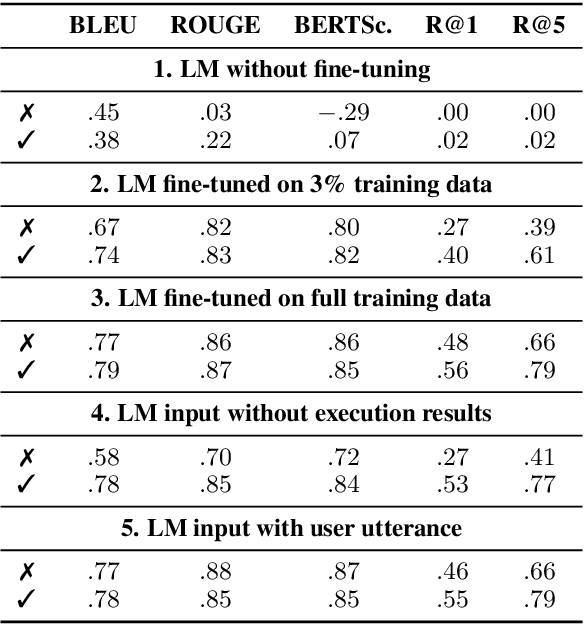
In a real-world dialogue system, generated responses must satisfy several interlocking constraints: being informative, truthful, and easy to control. The two predominant paradigms in language generation -- neural language modeling and rule-based generation -- both struggle to satisfy these constraints. Even the best neural models are prone to hallucination and omission of information, while existing formalisms for rule-based generation make it difficult to write grammars that are both flexible and fluent. We describe a hybrid architecture for dialogue response generation that combines the strengths of both approaches. This architecture has two components. First, a rule-based content selection model defined using a new formal framework called dataflow transduction, which uses declarative rules to transduce a dialogue agent's computations (represented as dataflow graphs) into context-free grammars representing the space of contextually acceptable responses. Second, a constrained decoding procedure that uses these grammars to constrain the output of a neural language model, which selects fluent utterances. The resulting system outperforms both rule-based and learned approaches in human evaluations of fluency, relevance, and truthfulness.
Recommendation as a Communication Game: Self-Supervised Bot-Play for Goal-oriented Dialogue
Sep 09, 2019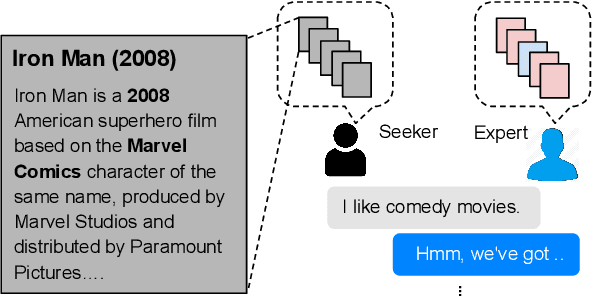
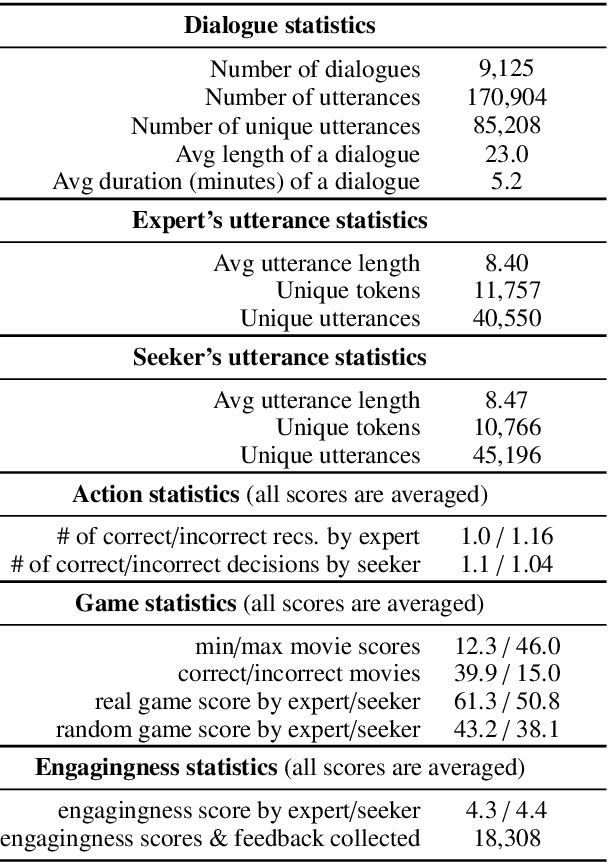
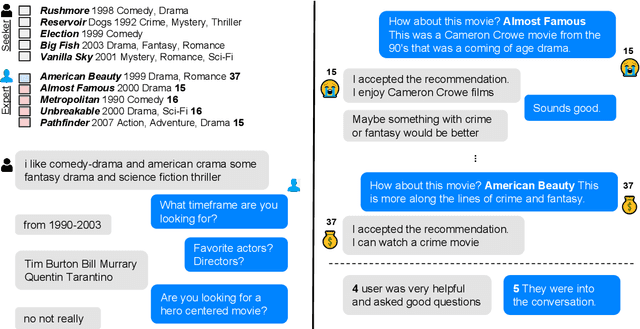
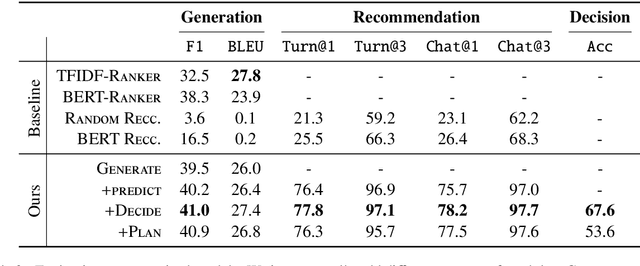
Traditional recommendation systems produce static rather than interactive recommendations invariant to a user's specific requests, clarifications, or current mood, and can suffer from the cold-start problem if their tastes are unknown. These issues can be alleviated by treating recommendation as an interactive dialogue task instead, where an expert recommender can sequentially ask about someone's preferences, react to their requests, and recommend more appropriate items. In this work, we collect a goal-driven recommendation dialogue dataset (GoRecDial), which consists of 9,125 dialogue games and 81,260 conversation turns between pairs of human workers recommending movies to each other. The task is specifically designed as a cooperative game between two players working towards a quantifiable common goal. We leverage the dataset to develop an end-to-end dialogue system that can simultaneously converse and recommend. Models are first trained to imitate the behavior of human players without considering the task goal itself (supervised training). We then finetune our models on simulated bot-bot conversations between two paired pre-trained models (bot-play), in order to achieve the dialogue goal. Our experiments show that models finetuned with bot-play learn improved dialogue strategies, reach the dialogue goal more often when paired with a human, and are rated as more consistent by humans compared to models trained without bot-play. The dataset and code are publicly available through the ParlAI framework.
Constrained Decoding for Neural NLG from Compositional Representations in Task-Oriented Dialogue
Jun 17, 2019

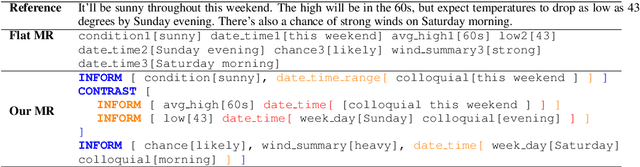
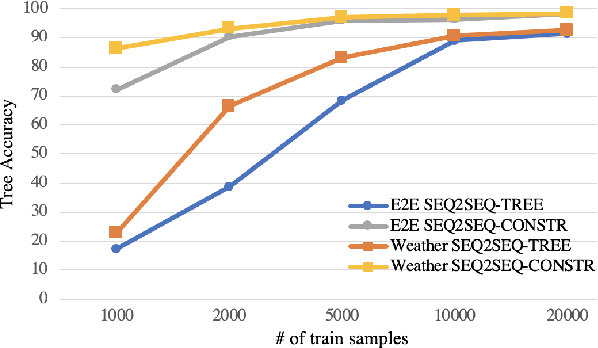
Generating fluent natural language responses from structured semantic representations is a critical step in task-oriented conversational systems. Avenues like the E2E NLG Challenge have encouraged the development of neural approaches, particularly sequence-to-sequence (Seq2Seq) models for this problem. The semantic representations used, however, are often underspecified, which places a higher burden on the generation model for sentence planning, and also limits the extent to which generated responses can be controlled in a live system. In this paper, we (1) propose using tree-structured semantic representations, like those used in traditional rule-based NLG systems, for better discourse-level structuring and sentence-level planning; (2) introduce a challenging dataset using this representation for the weather domain; (3) introduce a constrained decoding approach for Seq2Seq models that leverages this representation to improve semantic correctness; and (4) demonstrate promising results on our dataset and the E2E dataset.
Generate, Filter, and Rank: Grammaticality Classification for Production-Ready NLG Systems
Apr 09, 2019
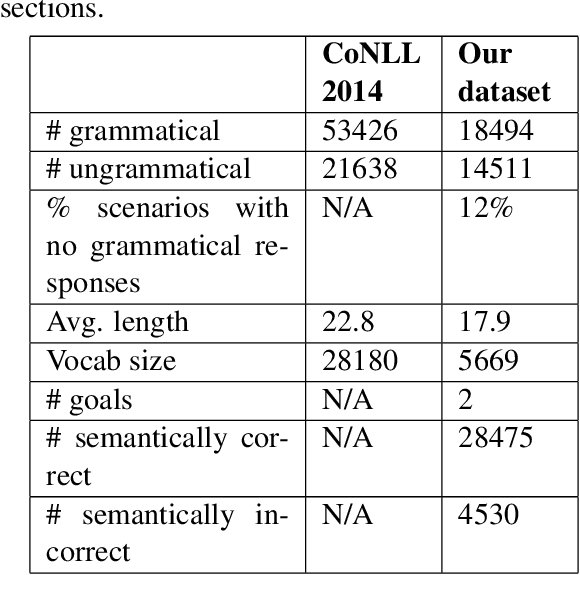
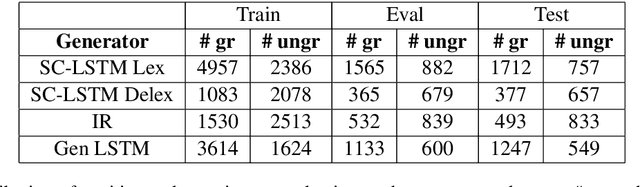

Neural approaches to Natural Language Generation (NLG) have been promising for goal-oriented dialogue. One of the challenges of productionizing these approaches, however, is the ability to control response quality, and ensure that generated responses are acceptable. We propose the use of a generate, filter, and rank framework, in which candidate responses are first filtered to eliminate unacceptable responses, and then ranked to select the best response. While acceptability includes grammatical correctness and semantic correctness, we focus only on grammaticality classification in this paper, and show that existing datasets for grammatical error correction don't correctly capture the distribution of errors that data-driven generators are likely to make. We release a grammatical classification and semantic correctness classification dataset for the weather domain that consists of responses generated by 3 data-driven NLG systems. We then explore two supervised learning approaches (CNNs and GBDTs) for classifying grammaticality. Our experiments show that grammaticality classification is very sensitive to the distribution of errors in the data, and that these distributions vary significantly with both the source of the response as well as the domain. We show that it's possible to achieve high precision with reasonable recall on our dataset.
Decoupling Strategy and Generation in Negotiation Dialogues
Aug 29, 2018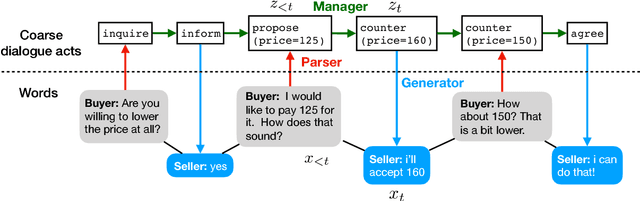


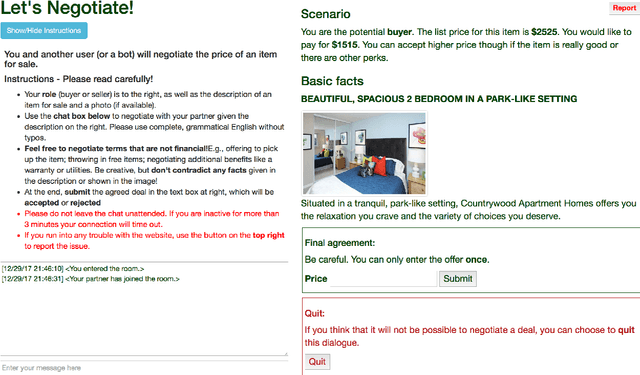
We consider negotiation settings in which two agents use natural language to bargain on goods. Agents need to decide on both high-level strategy (e.g., proposing \$50) and the execution of that strategy (e.g., generating "The bike is brand new. Selling for just \$50."). Recent work on negotiation trains neural models, but their end-to-end nature makes it hard to control their strategy, and reinforcement learning tends to lead to degenerate solutions. In this paper, we propose a modular approach based on coarse di- alogue acts (e.g., propose(price=50)) that decouples strategy and generation. We show that we can flexibly set the strategy using supervised learning, reinforcement learning, or domain-specific knowledge without degeneracy, while our retrieval-based generation can maintain context-awareness and produce diverse utterances. We test our approach on the recently proposed DEALORNODEAL game, and we also collect a richer dataset based on real items on Craigslist. Human evaluation shows that our systems achieve higher task success rate and more human-like negotiation behavior than previous approaches.
Malaria Likelihood Prediction By Effectively Surveying Households Using Deep Reinforcement Learning
Nov 25, 2017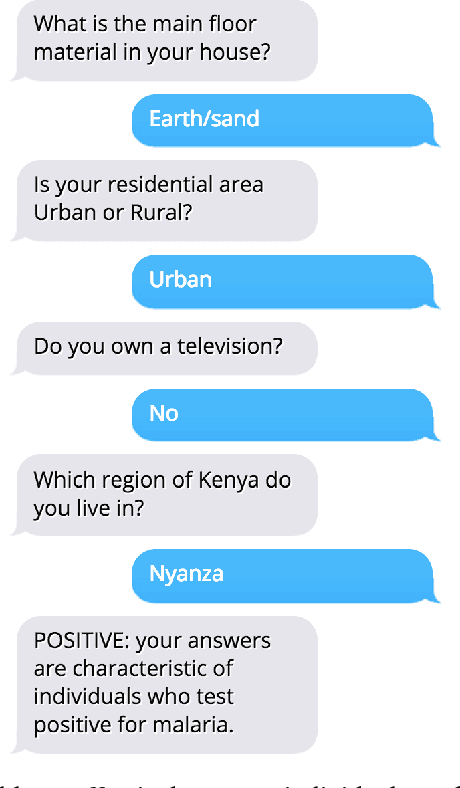
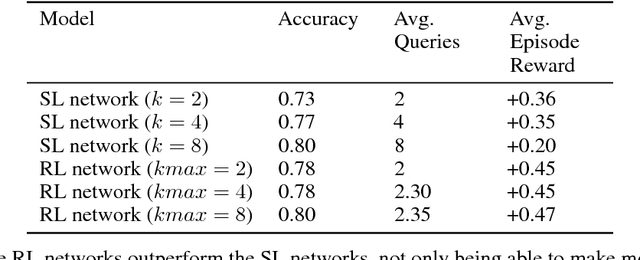
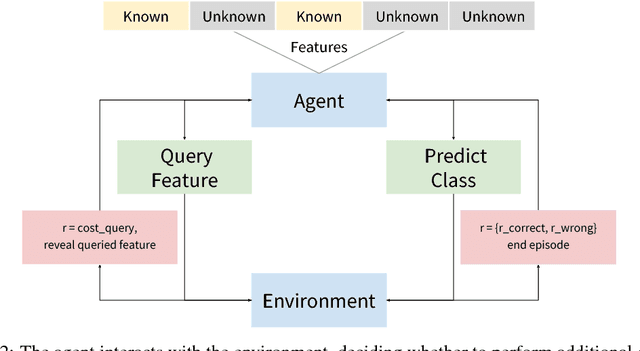

We build a deep reinforcement learning (RL) agent that can predict the likelihood of an individual testing positive for malaria by asking questions about their household. The RL agent learns to determine which survey question to ask next and when to stop to make a prediction about their likelihood of malaria based on their responses hitherto. The agent incurs a small penalty for each question asked, and a large reward/penalty for making the correct/wrong prediction; it thus has to learn to balance the length of the survey with the accuracy of its final predictions. Our RL agent is a Deep Q-network that learns a policy directly from the responses to the questions, with an action defined for each possible survey question and for each possible prediction class. We focus on Kenya, where malaria is a massive health burden, and train the RL agent on a dataset of 6481 households from the Kenya Malaria Indicator Survey 2015. To investigate the importance of having survey questions be adaptive to responses, we compare our RL agent to a supervised learning (SL) baseline that fixes its set of survey questions a priori. We evaluate on prediction accuracy and on the number of survey questions asked on a holdout set and find that the RL agent is able to predict with 80% accuracy, using only 2.5 questions on average. In addition, the RL agent learns to survey adaptively to responses and is able to match the SL baseline in prediction accuracy while significantly reducing survey length.
Learning Symmetric Collaborative Dialogue Agents with Dynamic Knowledge Graph Embeddings
Apr 24, 2017

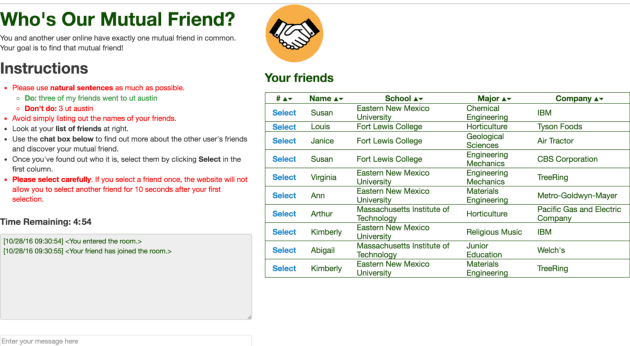

We study a symmetric collaborative dialogue setting in which two agents, each with private knowledge, must strategically communicate to achieve a common goal. The open-ended dialogue state in this setting poses new challenges for existing dialogue systems. We collected a dataset of 11K human-human dialogues, which exhibits interesting lexical, semantic, and strategic elements. To model both structured knowledge and unstructured language, we propose a neural model with dynamic knowledge graph embeddings that evolve as the dialogue progresses. Automatic and human evaluations show that our model is both more effective at achieving the goal and more human-like than baseline neural and rule-based models.