 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeZero-Shot Dialogue State Tracking via Cross-Task Transfer
Sep 10, 2021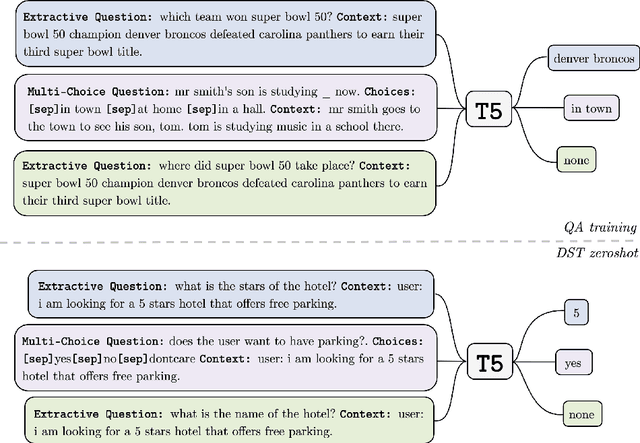
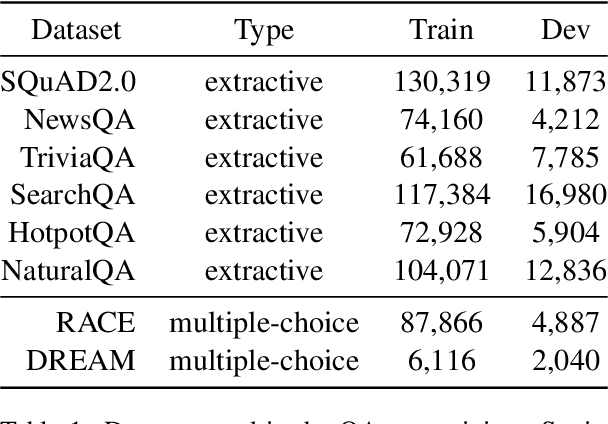
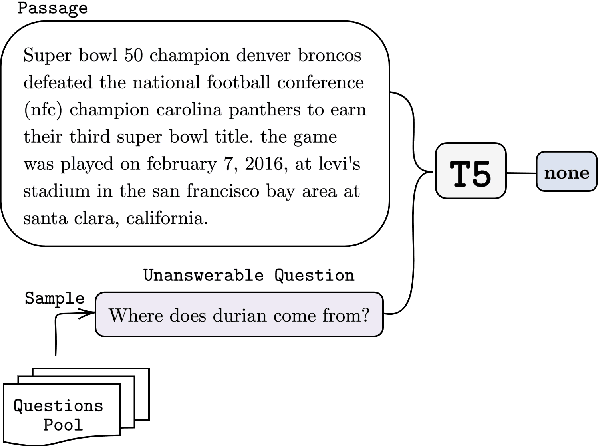
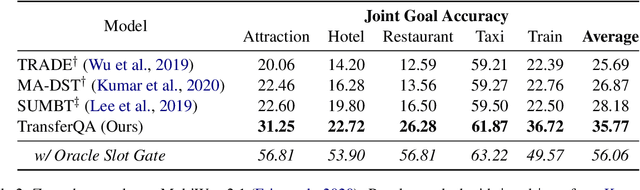
Zero-shot transfer learning for dialogue state tracking (DST) enables us to handle a variety of task-oriented dialogue domains without the expense of collecting in-domain data. In this work, we propose to transfer the \textit{cross-task} knowledge from general question answering (QA) corpora for the zero-shot DST task. Specifically, we propose TransferQA, a transferable generative QA model that seamlessly combines extractive QA and multi-choice QA via a text-to-text transformer framework, and tracks both categorical slots and non-categorical slots in DST. In addition, we introduce two effective ways to construct unanswerable questions, namely, negative question sampling and context truncation, which enable our model to handle "none" value slots in the zero-shot DST setting. The extensive experiments show that our approaches substantially improve the existing zero-shot and few-shot results on MultiWoz. Moreover, compared to the fully trained baseline on the Schema-Guided Dialogue dataset, our approach shows better generalization ability in unseen domains.
Leveraging Slot Descriptions for Zero-Shot Cross-Domain Dialogue State Tracking
May 10, 2021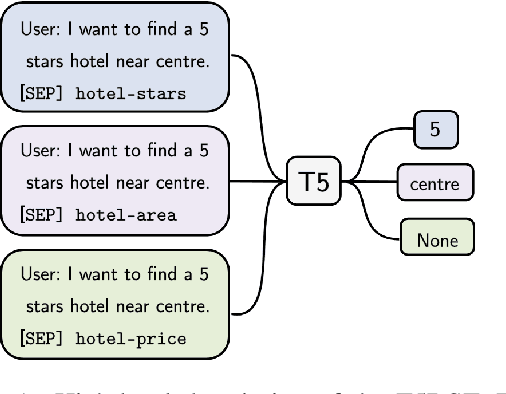

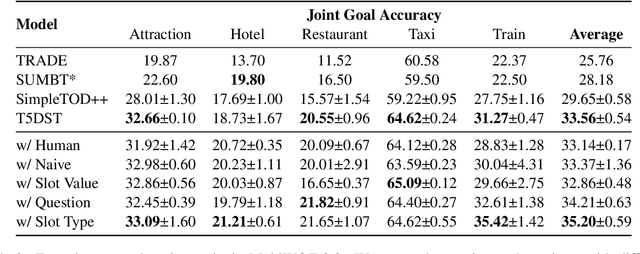
Zero-shot cross-domain dialogue state tracking (DST) enables us to handle task-oriented dialogue in unseen domains without the expense of collecting in-domain data. In this paper, we propose a slot description enhanced generative approach for zero-shot cross-domain DST. Specifically, our model first encodes dialogue context and slots with a pre-trained self-attentive encoder, and generates slot values in an auto-regressive manner. In addition, we incorporate Slot Type Informed Descriptions that capture the shared information across slots to facilitate cross-domain knowledge transfer. Experimental results on the MultiWOZ dataset show that our proposed method significantly improves existing state-of-the-art results in the zero-shot cross-domain setting.
Overview of the Ninth Dialog System Technology Challenge: DSTC9
Nov 12, 2020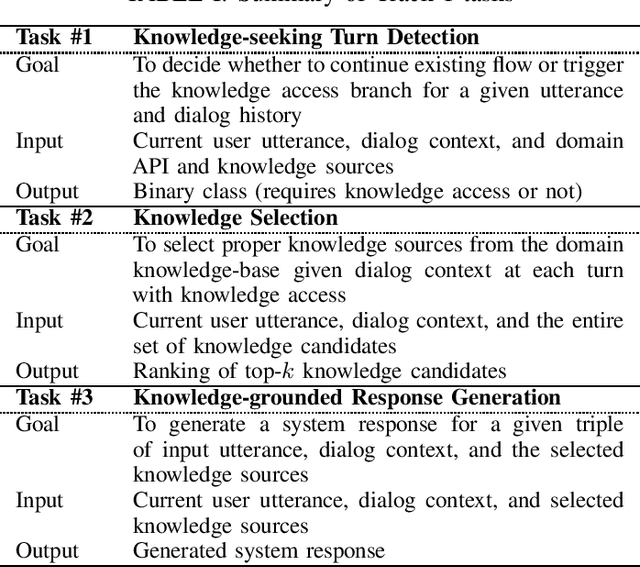
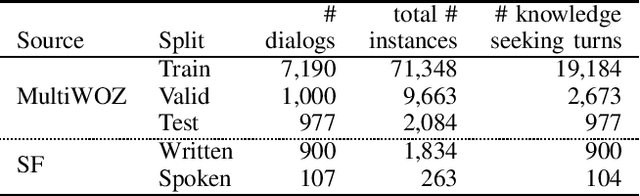

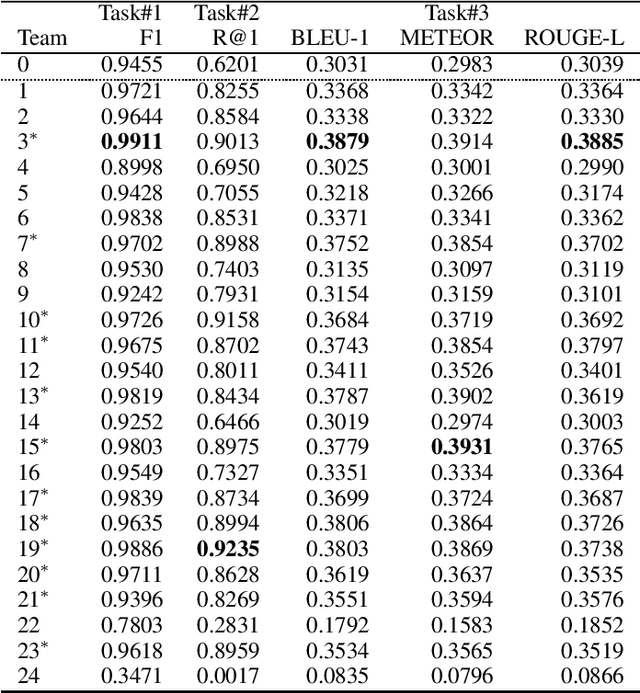
This paper introduces the Ninth Dialog System Technology Challenge (DSTC-9). This edition of the DSTC focuses on applying end-to-end dialog technologies for four distinct tasks in dialog systems, namely, 1. Task-oriented dialog Modeling with unstructured knowledge access, 2. Multi-domain task-oriented dialog, 3. Interactive evaluation of dialog, and 4. Situated interactive multi-modal dialog. This paper describes the task definition, provided datasets, baselines and evaluation set-up for each track. We also summarize the results of the submitted systems to highlight the overall trends of the state-of-the-art technologies for the tasks.
Resource Constrained Dialog Policy Learning via Differentiable Inductive Logic Programming
Nov 10, 2020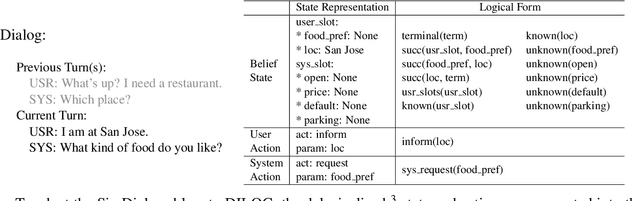
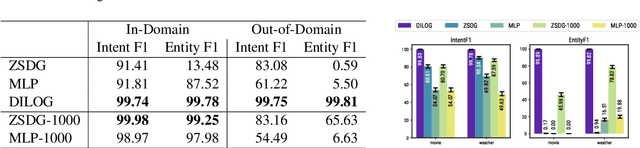

Motivated by the needs of resource constrained dialog policy learning, we introduce dialog policy via differentiable inductive logic (DILOG). We explore the tasks of one-shot learning and zero-shot domain transfer with DILOG on SimDial and MultiWoZ. Using a single representative dialog from the restaurant domain, we train DILOG on the SimDial dataset and obtain 99+% in-domain test accuracy. We also show that the trained DILOG zero-shot transfers to all other domains with 99+% accuracy, proving the suitability of DILOG to slot-filling dialogs. We further extend our study to the MultiWoZ dataset achieving 90+% inform and success metrics. We also observe that these metrics are not capturing some of the shortcomings of DILOG in terms of false positives, prompting us to measure an auxiliary Action F1 score. We show that DILOG is 100x more data efficient than state-of-the-art neural approaches on MultiWoZ while achieving similar performance metrics. We conclude with a discussion on the strengths and weaknesses of DILOG.
Situated and Interactive Multimodal Conversations
Jun 02, 2020
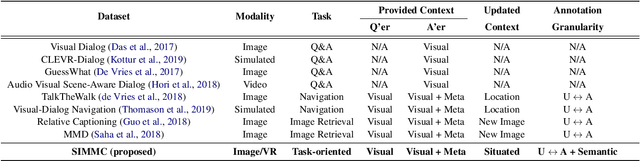
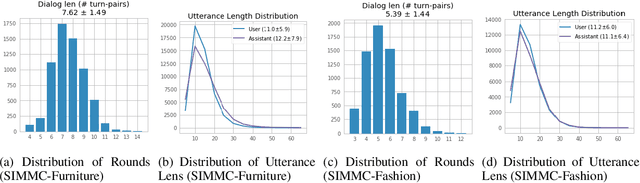
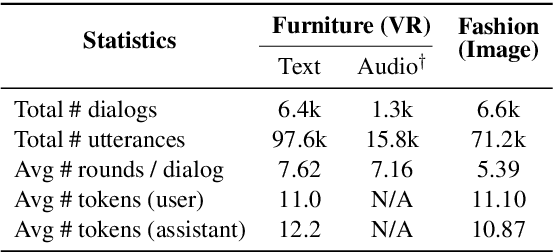
Next generation virtual assistants are envisioned to handle multimodal inputs (e.g., vision, memories of previous interactions, etc., in addition to the user's utterances), and perform multimodal actions (e.g., displaying a route in addition to generating the system's utterance). We introduce Situated Interactive MultiModal Conversations (SIMMC) as a new direction aimed at training agents that take multimodal actions grounded in a co-evolving multimodal input context in addition to the dialog history. We provide two SIMMC datasets totalling ~13K human-human dialogs (~169K utterances) using a multimodal Wizard-of-Oz (WoZ) setup, on two shopping domains: (a) furniture (grounded in a shared virtual environment) and, (b) fashion (grounded in an evolving set of images). We also provide logs of the items appearing in each scene, and contextual NLU and coreference annotations, using a novel and unified framework of SIMMC conversational acts for both user and assistant utterances. Finally, we present several tasks within SIMMC as objective evaluation protocols, such as Structural API Prediction and Response Generation. We benchmark a collection of existing models on these SIMMC tasks as strong baselines, and demonstrate rich multimodal conversational interactions. Our data, annotations, code, and models will be made publicly available.
SIMMC: Situated Interactive Multi-Modal Conversational Data Collection And Evaluation Platform
Nov 07, 2019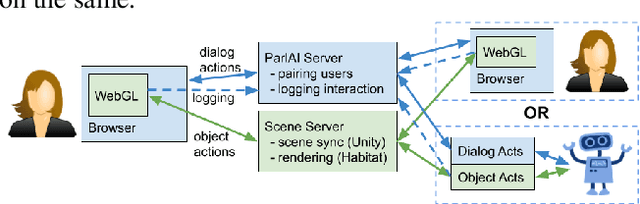
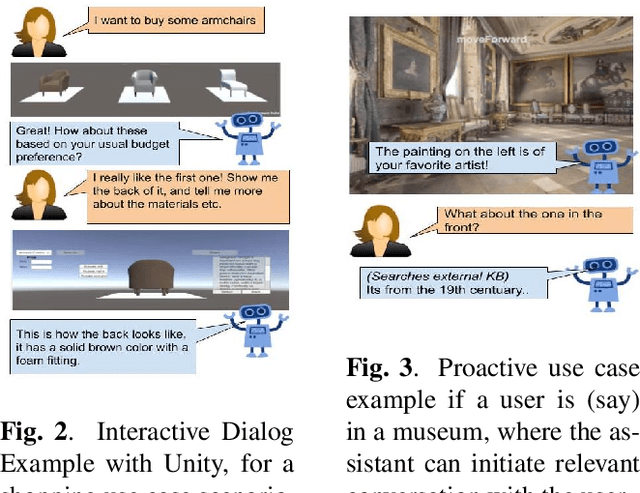
As digital virtual assistants become ubiquitous, it becomes increasingly important to understand the situated behaviour of users as they interact with these assistants. To this end, we introduce SIMMC, an extension to ParlAI for multi-modal conversational data collection and system evaluation. SIMMC simulates an immersive setup, where crowd workers are able to interact with environments constructed in AI Habitat or Unity while engaging in a conversation. The assistant in SIMMC can be a crowd worker or Artificial Intelligent (AI) agent. This enables both (i) a multi-player / Wizard of Oz setting for data collection, or (ii) a single player mode for model / system evaluation. We plan to open-source a situated conversational data-set collected on this platform for the Conversational AI research community.
Constrained Decoding for Neural NLG from Compositional Representations in Task-Oriented Dialogue
Jun 17, 2019

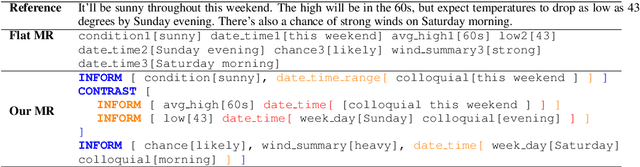
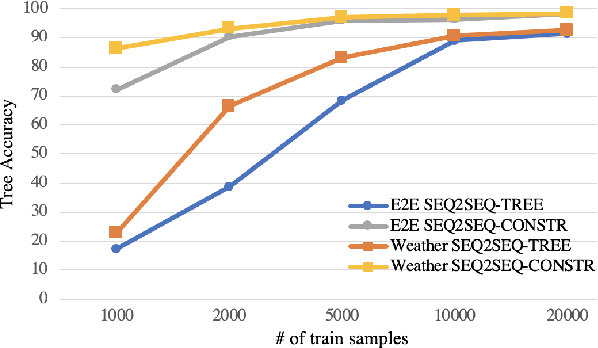
Generating fluent natural language responses from structured semantic representations is a critical step in task-oriented conversational systems. Avenues like the E2E NLG Challenge have encouraged the development of neural approaches, particularly sequence-to-sequence (Seq2Seq) models for this problem. The semantic representations used, however, are often underspecified, which places a higher burden on the generation model for sentence planning, and also limits the extent to which generated responses can be controlled in a live system. In this paper, we (1) propose using tree-structured semantic representations, like those used in traditional rule-based NLG systems, for better discourse-level structuring and sentence-level planning; (2) introduce a challenging dataset using this representation for the weather domain; (3) introduce a constrained decoding approach for Seq2Seq models that leverages this representation to improve semantic correctness; and (4) demonstrate promising results on our dataset and the E2E dataset.
Generate, Filter, and Rank: Grammaticality Classification for Production-Ready NLG Systems
Apr 09, 2019
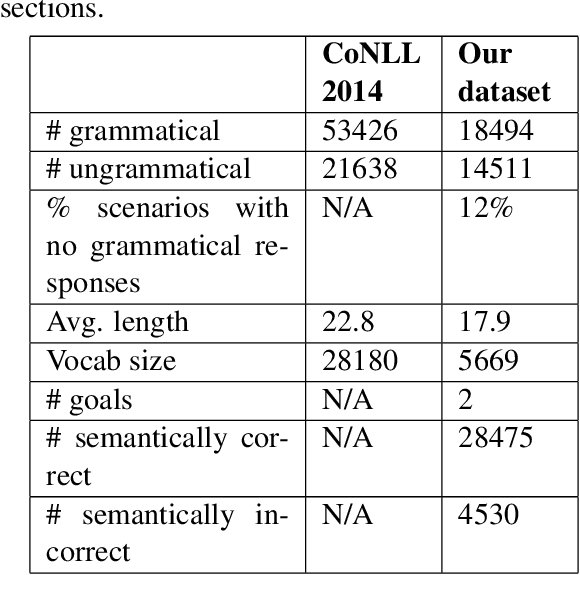
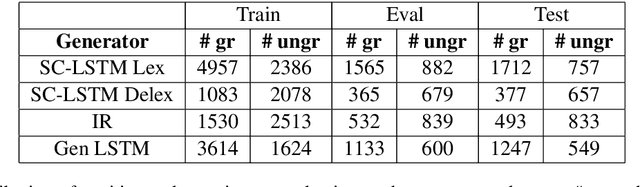

Neural approaches to Natural Language Generation (NLG) have been promising for goal-oriented dialogue. One of the challenges of productionizing these approaches, however, is the ability to control response quality, and ensure that generated responses are acceptable. We propose the use of a generate, filter, and rank framework, in which candidate responses are first filtered to eliminate unacceptable responses, and then ranked to select the best response. While acceptability includes grammatical correctness and semantic correctness, we focus only on grammaticality classification in this paper, and show that existing datasets for grammatical error correction don't correctly capture the distribution of errors that data-driven generators are likely to make. We release a grammatical classification and semantic correctness classification dataset for the weather domain that consists of responses generated by 3 data-driven NLG systems. We then explore two supervised learning approaches (CNNs and GBDTs) for classifying grammaticality. Our experiments show that grammaticality classification is very sensitive to the distribution of errors in the data, and that these distributions vary significantly with both the source of the response as well as the domain. We show that it's possible to achieve high precision with reasonable recall on our dataset.