 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSituated and Interactive Multimodal Conversations
Paper and Code

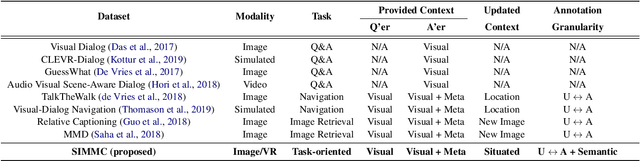
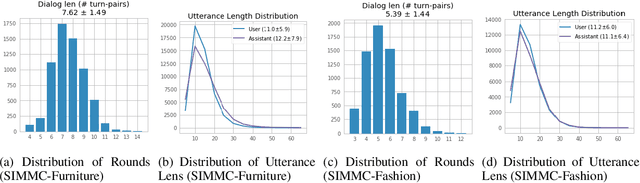
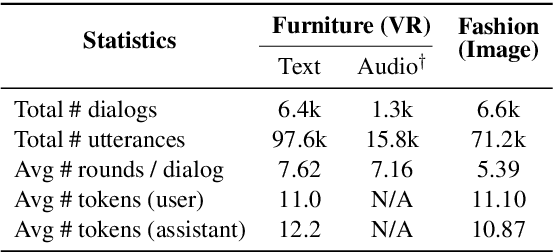
Next generation virtual assistants are envisioned to handle multimodal inputs (e.g., vision, memories of previous interactions, etc., in addition to the user's utterances), and perform multimodal actions (e.g., displaying a route in addition to generating the system's utterance). We introduce Situated Interactive MultiModal Conversations (SIMMC) as a new direction aimed at training agents that take multimodal actions grounded in a co-evolving multimodal input context in addition to the dialog history. We provide two SIMMC datasets totalling ~13K human-human dialogs (~169K utterances) using a multimodal Wizard-of-Oz (WoZ) setup, on two shopping domains: (a) furniture (grounded in a shared virtual environment) and, (b) fashion (grounded in an evolving set of images). We also provide logs of the items appearing in each scene, and contextual NLU and coreference annotations, using a novel and unified framework of SIMMC conversational acts for both user and assistant utterances. Finally, we present several tasks within SIMMC as objective evaluation protocols, such as Structural API Prediction and Response Generation. We benchmark a collection of existing models on these SIMMC tasks as strong baselines, and demonstrate rich multimodal conversational interactions. Our data, annotations, code, and models will be made publicly available.