 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVEATIC: Video-based Emotion and Affect Tracking in Context Dataset
Sep 15, 2023



Human affect recognition has been a significant topic in psychophysics and computer vision. However, the currently published datasets have many limitations. For example, most datasets contain frames that contain only information about facial expressions. Due to the limitations of previous datasets, it is very hard to either understand the mechanisms for affect recognition of humans or generalize well on common cases for computer vision models trained on those datasets. In this work, we introduce a brand new large dataset, the Video-based Emotion and Affect Tracking in Context Dataset (VEATIC), that can conquer the limitations of the previous datasets. VEATIC has 124 video clips from Hollywood movies, documentaries, and home videos with continuous valence and arousal ratings of each frame via real-time annotation. Along with the dataset, we propose a new computer vision task to infer the affect of the selected character via both context and character information in each video frame. Additionally, we propose a simple model to benchmark this new computer vision task. We also compare the performance of the pretrained model using our dataset with other similar datasets. Experiments show the competing results of our pretrained model via VEATIC, indicating the generalizability of VEATIC. Our dataset is available at https://veatic.github.io.
Situated and Interactive Multimodal Conversations
Jun 02, 2020
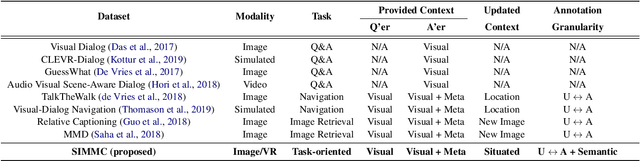
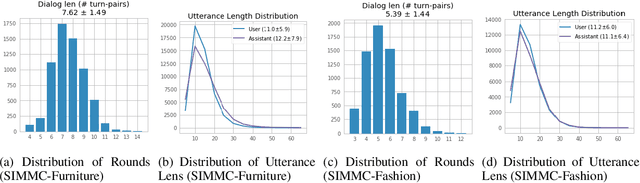
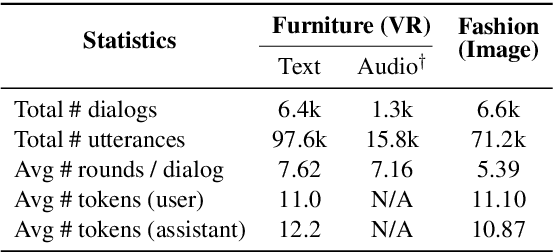
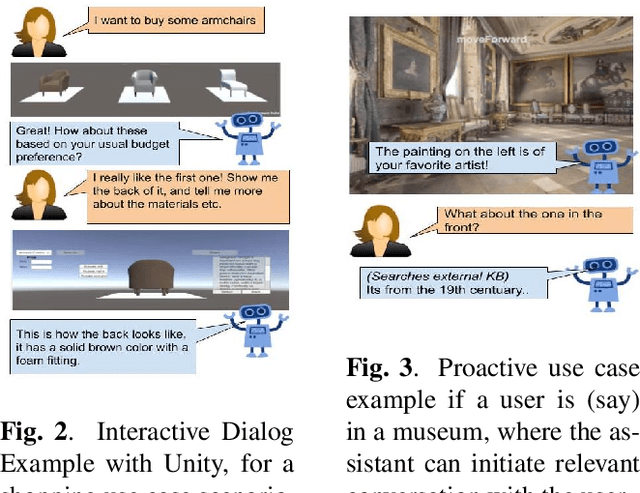
Next generation virtual assistants are envisioned to handle multimodal inputs (e.g., vision, memories of previous interactions, etc., in addition to the user's utterances), and perform multimodal actions (e.g., displaying a route in addition to generating the system's utterance). We introduce Situated Interactive MultiModal Conversations (SIMMC) as a new direction aimed at training agents that take multimodal actions grounded in a co-evolving multimodal input context in addition to the dialog history. We provide two SIMMC datasets totalling ~13K human-human dialogs (~169K utterances) using a multimodal Wizard-of-Oz (WoZ) setup, on two shopping domains: (a) furniture (grounded in a shared virtual environment) and, (b) fashion (grounded in an evolving set of images). We also provide logs of the items appearing in each scene, and contextual NLU and coreference annotations, using a novel and unified framework of SIMMC conversational acts for both user and assistant utterances. Finally, we present several tasks within SIMMC as objective evaluation protocols, such as Structural API Prediction and Response Generation. We benchmark a collection of existing models on these SIMMC tasks as strong baselines, and demonstrate rich multimodal conversational interactions. Our data, annotations, code, and models will be made publicly available.
SIMMC: Situated Interactive Multi-Modal Conversational Data Collection And Evaluation Platform
Nov 07, 2019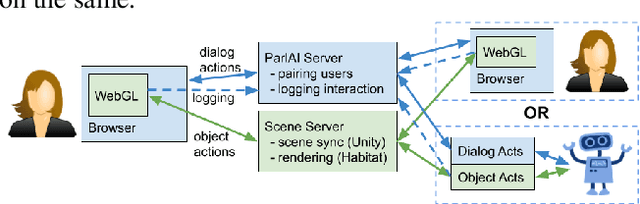
As digital virtual assistants become ubiquitous, it becomes increasingly important to understand the situated behaviour of users as they interact with these assistants. To this end, we introduce SIMMC, an extension to ParlAI for multi-modal conversational data collection and system evaluation. SIMMC simulates an immersive setup, where crowd workers are able to interact with environments constructed in AI Habitat or Unity while engaging in a conversation. The assistant in SIMMC can be a crowd worker or Artificial Intelligent (AI) agent. This enables both (i) a multi-player / Wizard of Oz setting for data collection, or (ii) a single player mode for model / system evaluation. We plan to open-source a situated conversational data-set collected on this platform for the Conversational AI research community.
Periphery-Fovea Multi-Resolution Driving Model guided by Human Attention
Mar 24, 2019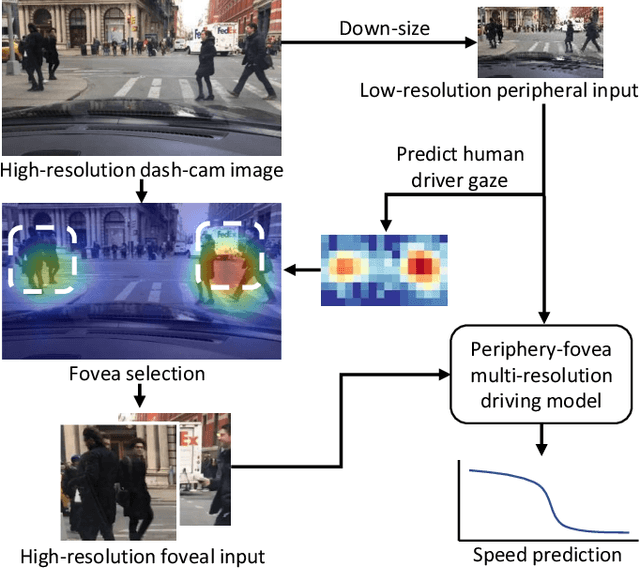

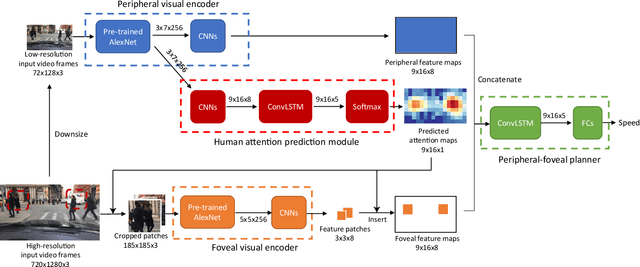
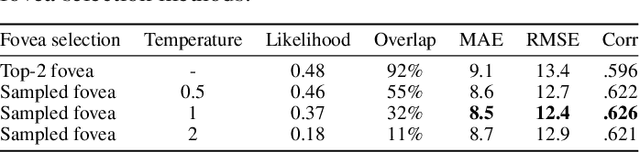
Inspired by human vision, we propose a new periphery-fovea multi-resolution driving model that predicts vehicle speed from dash camera videos. The peripheral vision module of the model processes the full video frames in low resolution. Its foveal vision module selects sub-regions and uses high-resolution input from those regions to improve its driving performance. We train the fovea selection module with supervision from driver gaze. We show that adding high-resolution input from predicted human driver gaze locations significantly improves the driving accuracy of the model. Our periphery-fovea multi-resolution model outperforms a uni-resolution periphery-only model that has the same amount of floating-point operations. More importantly, we demonstrate that our driving model achieves a significantly higher performance gain in pedestrian-involved critical situations than in other non-critical situations.
Predicting Driver Attention in Critical Situations
Aug 16, 2018



Robust driver attention prediction for critical situations is a challenging computer vision problem, yet essential for autonomous driving. Because critical driving moments are so rare, collecting enough data for these situations is difficult with the conventional in-car data collection protocol---tracking eye movements during driving. Here, we first propose a new in-lab driver attention collection protocol and introduce a new driver attention dataset built upon braking event videos selected from a large-scale, crowd-sourced driving video dataset. We further propose Human Weighted Sampling (HWS) method, which uses human gaze behavior to identify crucial frames of a driving dataset and weights them heavily during model training. With our dataset and HWS, we built a driver attention prediction model that outperforms the state-of-the-art and demonstrates sophisticated behaviors, like attending to crossing pedestrians but not giving false alarms to pedestrians safely walking on the sidewalk. Its prediction results are nearly indistinguishable from ground-truth to humans. Although only being trained with our in-lab attention data, the model also predicts in-car driver attention data of routine driving with state-of-the-art accuracy. This result not only demonstrates the performance of our model but also proves the validity and usefulness of our dataset and data collection protocol.
Learning Robust Dialog Policies in Noisy Environments
Dec 11, 2017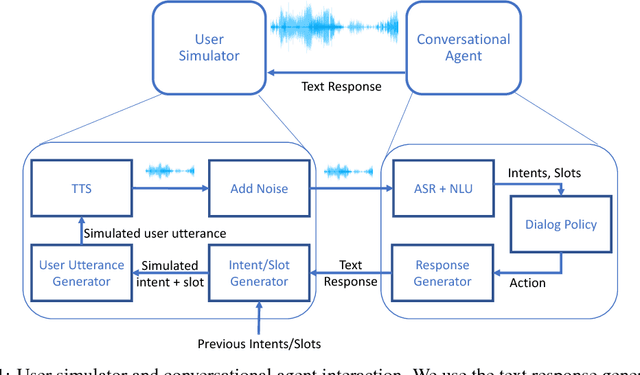

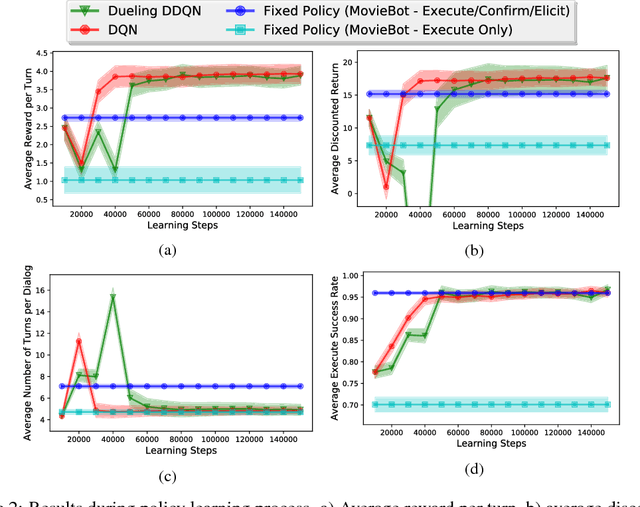
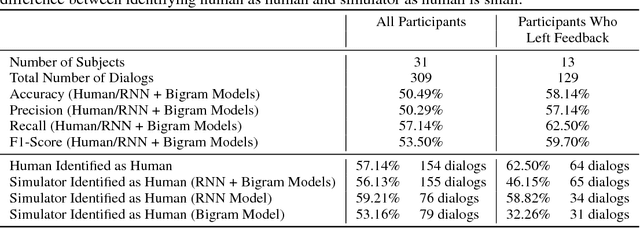
Modern virtual personal assistants provide a convenient interface for completing daily tasks via voice commands. An important consideration for these assistants is the ability to recover from automatic speech recognition (ASR) and natural language understanding (NLU) errors. In this paper, we focus on learning robust dialog policies to recover from these errors. To this end, we develop a user simulator which interacts with the assistant through voice commands in realistic scenarios with noisy audio, and use it to learn dialog policies through deep reinforcement learning. We show that dialogs generated by our simulator are indistinguishable from human generated dialogs, as determined by human evaluators. Furthermore, preliminary experimental results show that the learned policies in noisy environments achieve the same execution success rate with fewer dialog turns compared to fixed rule-based policies.
Communicating Robot Arm Motion Intent Through Mixed Reality Head-mounted Displays
Aug 11, 2017
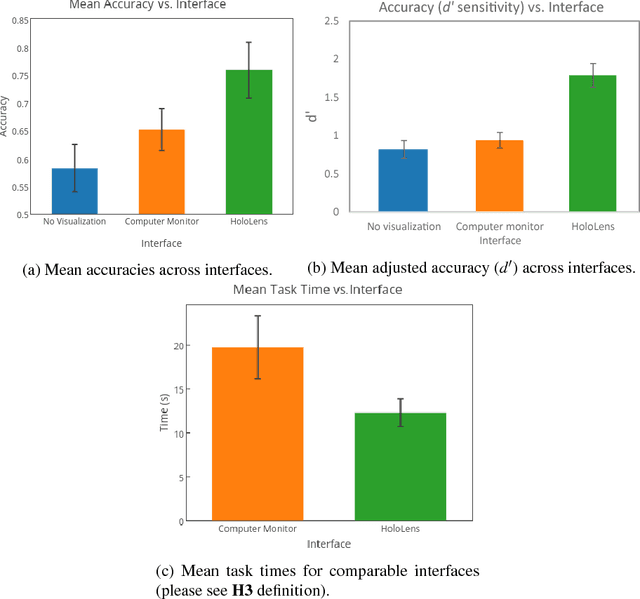
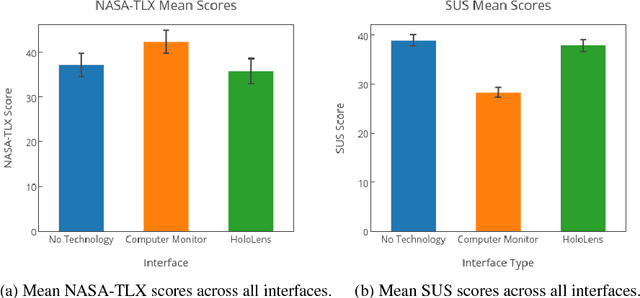
Efficient motion intent communication is necessary for safe and collaborative work environments with collocated humans and robots. Humans efficiently communicate their motion intent to other humans through gestures, gaze, and social cues. However, robots often have difficulty efficiently communicating their motion intent to humans via these methods. Many existing methods for robot motion intent communication rely on 2D displays, which require the human to continually pause their work and check a visualization. We propose a mixed reality head-mounted display visualization of the proposed robot motion over the wearer's real-world view of the robot and its environment. To evaluate the effectiveness of this system against a 2D display visualization and against no visualization, we asked 32 participants to labeled different robot arm motions as either colliding or non-colliding with blocks on a table. We found a 16% increase in accuracy with a 62% decrease in the time it took to complete the task compared to the next best system. This demonstrates that a mixed-reality HMD allows a human to more quickly and accurately tell where the robot is going to move than the compared baselines.
Curiosity Based Exploration for Learning Terrain Models
Oct 24, 2013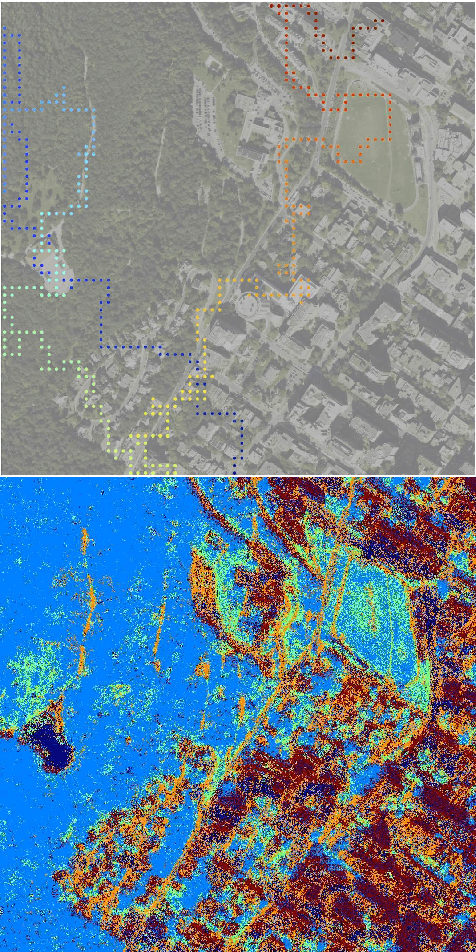
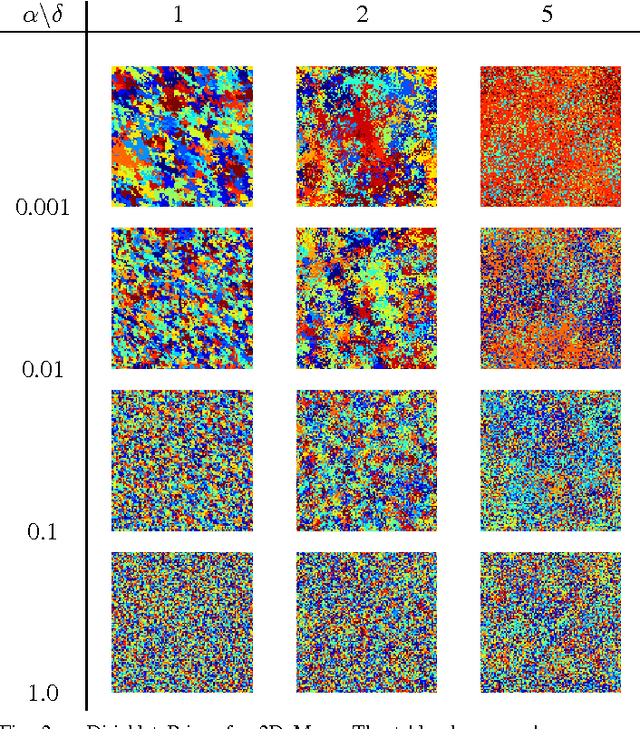
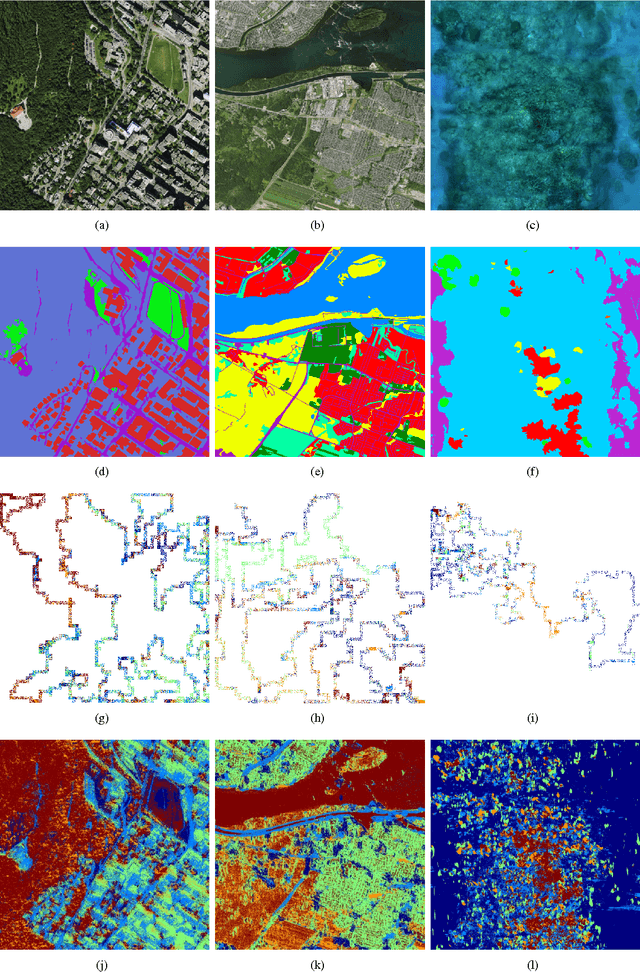
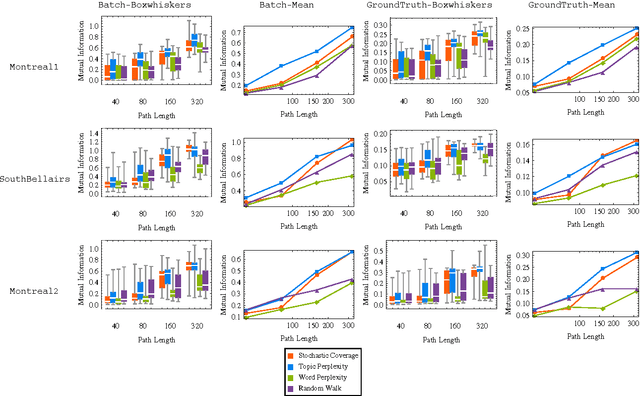
We present a robotic exploration technique in which the goal is to learn to a visual model and be able to distinguish between different terrains and other visual components in an unknown environment. We use ROST, a realtime online spatiotemporal topic modeling framework to model these terrains using the observations made by the robot, and then use an information theoretic path planning technique to define the exploration path. We conduct experiments with aerial view and underwater datasets with millions of observations and varying path lengths, and find that paths that are biased towards locations with high topic perplexity produce better terrain models with high discriminative power, especially with paths of length close to the diameter of the world.