 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePeriphery-Fovea Multi-Resolution Driving Model guided by Human Attention
Mar 24, 2019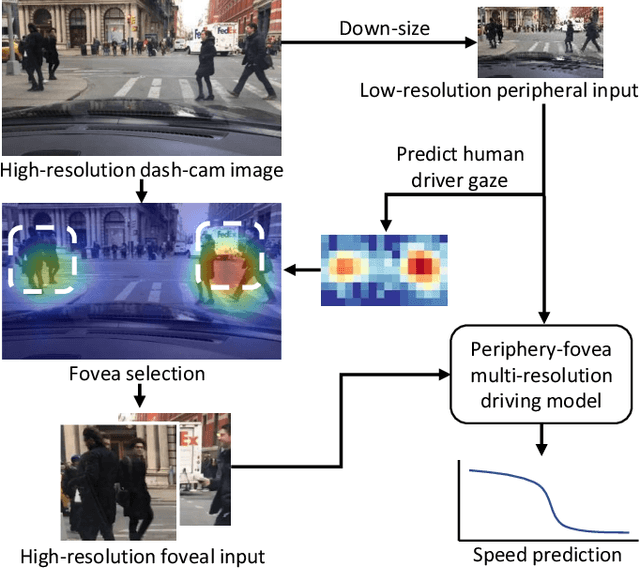

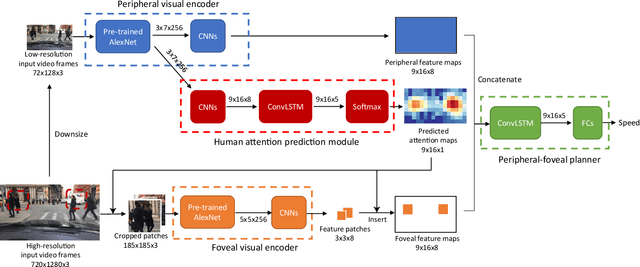
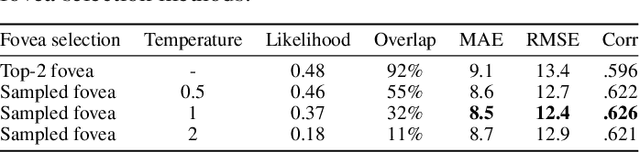
Inspired by human vision, we propose a new periphery-fovea multi-resolution driving model that predicts vehicle speed from dash camera videos. The peripheral vision module of the model processes the full video frames in low resolution. Its foveal vision module selects sub-regions and uses high-resolution input from those regions to improve its driving performance. We train the fovea selection module with supervision from driver gaze. We show that adding high-resolution input from predicted human driver gaze locations significantly improves the driving accuracy of the model. Our periphery-fovea multi-resolution model outperforms a uni-resolution periphery-only model that has the same amount of floating-point operations. More importantly, we demonstrate that our driving model achieves a significantly higher performance gain in pedestrian-involved critical situations than in other non-critical situations.
MultiNet: Multi-Modal Multi-Task Learning for Autonomous Driving
Jan 14, 2019

Autonomous driving requires operation in different behavioral modes ranging from lane following and intersection crossing to turning and stopping. However, most existing deep learning approaches to autonomous driving do not consider the behavioral mode in the training strategy. This paper describes a technique for learning multiple distinct behavioral modes in a single deep neural network through the use of multi-modal multi-task learning. We study the effectiveness of this approach, denoted MultiNet, using self-driving model cars for driving in unstructured environments such as sidewalks and unpaved roads. Using labeled data from over one hundred hours of driving our fleet of 1/10th scale model cars, we trained different neural networks to predict the steering angle and driving speed of the vehicle in different behavioral modes. We show that in each case, MultiNet networks outperform networks trained on individual modes while using a fraction of the total number of parameters.
Predicting Driver Attention in Critical Situations
Aug 16, 2018



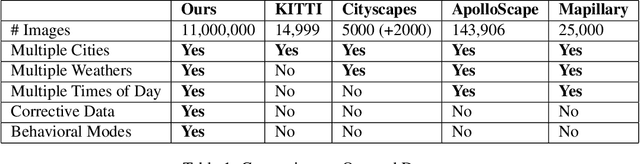
Robust driver attention prediction for critical situations is a challenging computer vision problem, yet essential for autonomous driving. Because critical driving moments are so rare, collecting enough data for these situations is difficult with the conventional in-car data collection protocol---tracking eye movements during driving. Here, we first propose a new in-lab driver attention collection protocol and introduce a new driver attention dataset built upon braking event videos selected from a large-scale, crowd-sourced driving video dataset. We further propose Human Weighted Sampling (HWS) method, which uses human gaze behavior to identify crucial frames of a driving dataset and weights them heavily during model training. With our dataset and HWS, we built a driver attention prediction model that outperforms the state-of-the-art and demonstrates sophisticated behaviors, like attending to crossing pedestrians but not giving false alarms to pedestrians safely walking on the sidewalk. Its prediction results are nearly indistinguishable from ground-truth to humans. Although only being trained with our in-lab attention data, the model also predicts in-car driver attention data of routine driving with state-of-the-art accuracy. This result not only demonstrates the performance of our model but also proves the validity and usefulness of our dataset and data collection protocol.
Learning to Roam Free from Small-Space Autonomous Driving with A Path Planner
Mar 17, 2018



Modern autonomous driving algorithms often rely on learning the mapping from visual inputs to steering actions from human driving data in a variety of scenarios and visual scenes. The required data collection is not only labor intensive, but such data are often noisy, inconsistent, and inflexible, as there is no differentiation between good and bad drivers, or between different driving intentions. We propose a new autonomous driving approach that learns roaming skills from an optimal path planner. Our model car practices reaching random target locations in a small room with obstacles, by following the optimal trajectory and executing the steering actions decided by a planner. We learn the associations of driving behaviours with depth images, instead of raw color images of the visual scene. This more universal spatial representation allows the learned driving skills to transfer immediately to novel environments with different visual appearances. Our model car trained in a simple room, void of many visual features, demonstrates surprisingly good driving performance in a cluttered office environment, avoiding collisions with novel obstacles and unseen layouts of drive-able space. Its performance on outdoor curbside driving is also on par with human driving.
Fast Recurrent Fully Convolutional Networks for Direct Perception in Autonomous Driving
Nov 20, 2017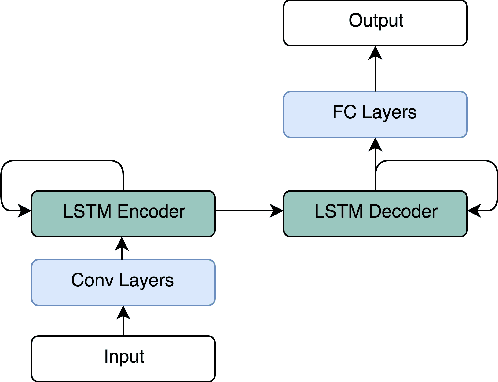

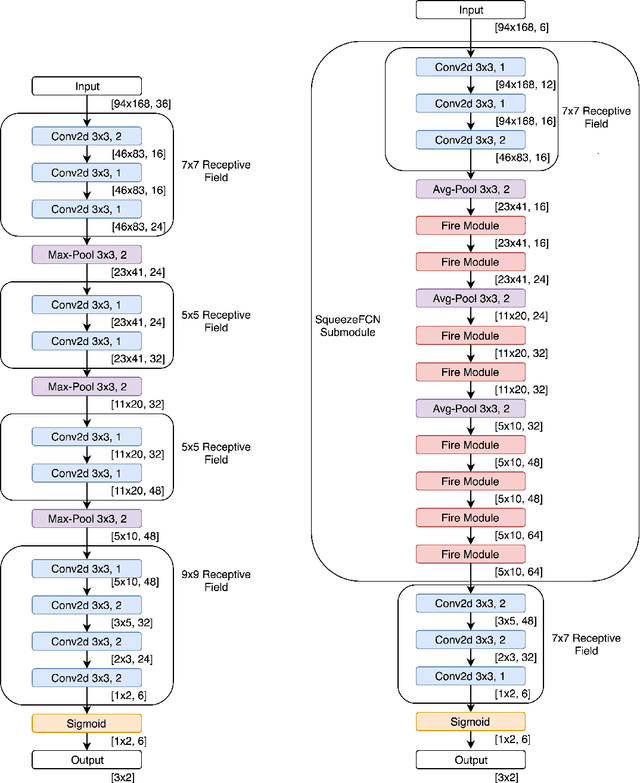
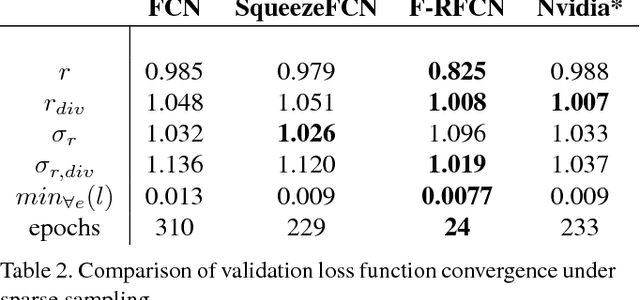
Deep convolutional neural networks (CNNs) have been shown to perform extremely well at a variety of tasks including subtasks of autonomous driving such as image segmentation and object classification. However, networks designed for these tasks typically require vast quantities of training data and long training periods to converge. We investigate the design rationale behind end-to-end driving network designs by proposing and comparing three small and computationally inexpensive deep end-to-end neural network models that generate driving control signals directly from input images. In contrast to prior work that segments the autonomous driving task, our models take on a novel approach to the autonomous driving problem by utilizing deep and thin Fully Convolutional Nets (FCNs) with recurrent neural nets and low parameter counts to tackle a complex end-to-end regression task predicting both steering and acceleration commands. In addition, we include layers optimized for classification to allow the networks to implicitly learn image semantics. We show that the resulting networks use 3x fewer parameters than the most recent comparable end-to-end driving network and 500x fewer parameters than the AlexNet variations and converge both faster and to lower losses while maintaining robustness against overfitting.
Node Specificity in Convolutional Deep Nets Depends on Receptive Field Position and Size
Nov 23, 2015

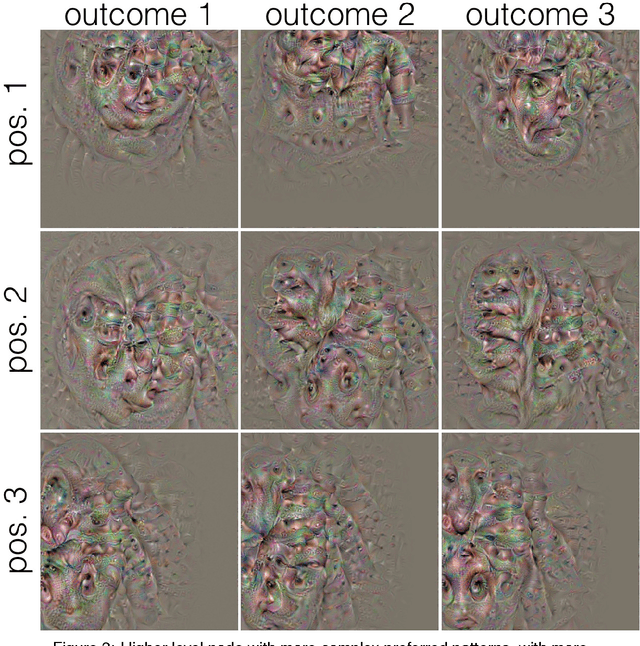

In convolutional deep neural networks, receptive field (RF) size increases with hierarchical depth. When RF size approaches full coverage of the input image, different RF positions result in RFs with different specificity, as portions of the RF fall out of the input space. This leads to a departure from the convolutional concept of positional invariance and opens the possibility for complex forms of context specificity.