Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNode Specificity in Convolutional Deep Nets Depends on Receptive Field Position and Size
Paper and Code


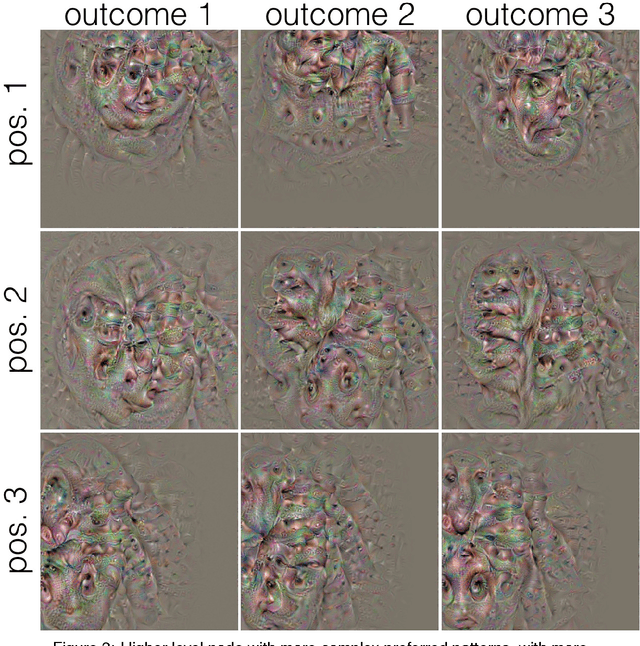

In convolutional deep neural networks, receptive field (RF) size increases with hierarchical depth. When RF size approaches full coverage of the input image, different RF positions result in RFs with different specificity, as portions of the RF fall out of the input space. This leads to a departure from the convolutional concept of positional invariance and opens the possibility for complex forms of context specificity.
View paper on