 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAnnotation Inconsistency and Entity Bias in MultiWOZ
May 29, 2021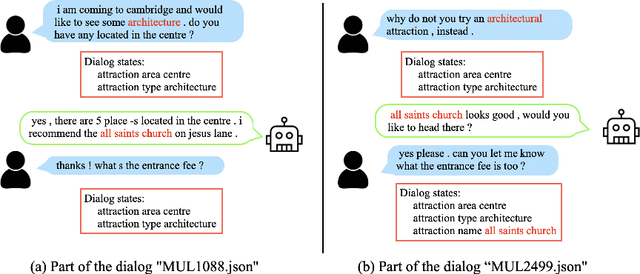
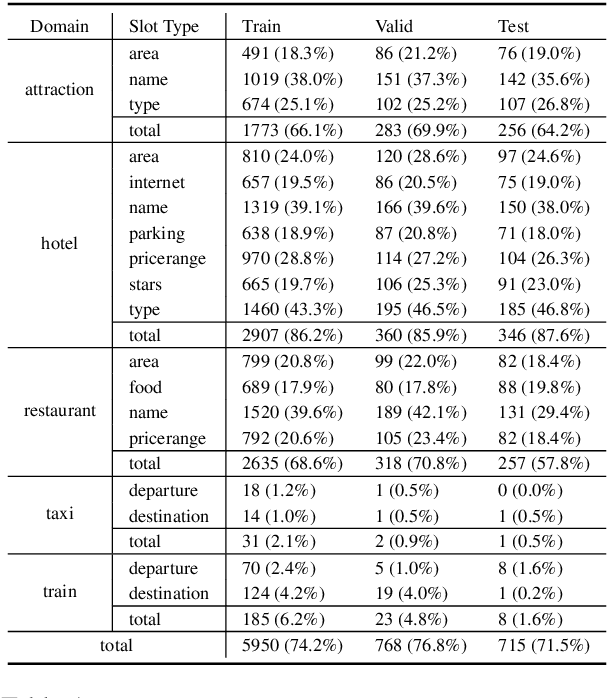
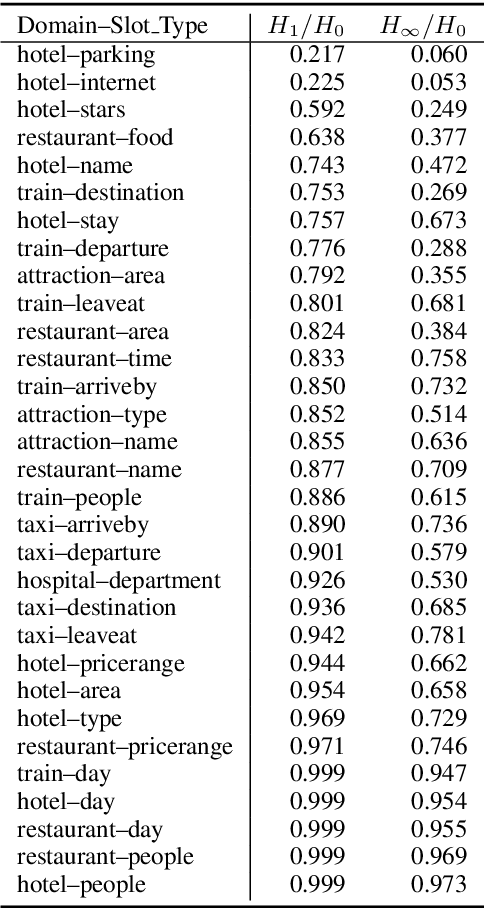
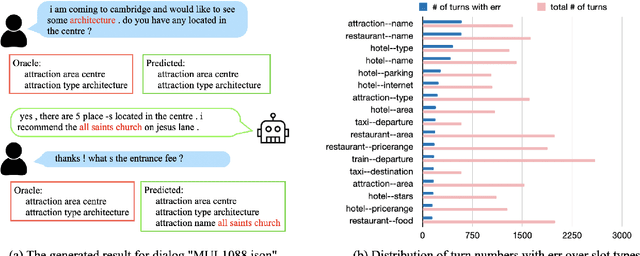
MultiWOZ is one of the most popular multi-domain task-oriented dialog datasets, containing 10K+ annotated dialogs covering eight domains. It has been widely accepted as a benchmark for various dialog tasks, e.g., dialog state tracking (DST), natural language generation (NLG), and end-to-end (E2E) dialog modeling. In this work, we identify an overlooked issue with dialog state annotation inconsistencies in the dataset, where a slot type is tagged inconsistently across similar dialogs leading to confusion for DST modeling. We propose an automated correction for this issue, which is present in a whopping 70% of the dialogs. Additionally, we notice that there is significant entity bias in the dataset (e.g., "cambridge" appears in 50% of the destination cities in the train domain). The entity bias can potentially lead to named entity memorization in generative models, which may go unnoticed as the test set suffers from a similar entity bias as well. We release a new test set with all entities replaced with unseen entities. Finally, we benchmark joint goal accuracy (JGA) of the state-of-the-art DST baselines on these modified versions of the data. Our experiments show that the annotation inconsistency corrections lead to 7-10% improvement in JGA. On the other hand, we observe a 29% drop in JGA when models are evaluated on the new test set with unseen entities.
Overview of the Ninth Dialog System Technology Challenge: DSTC9
Nov 12, 2020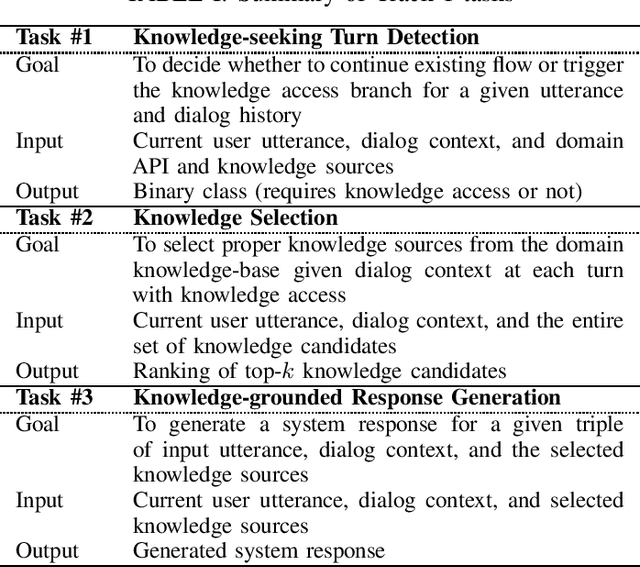
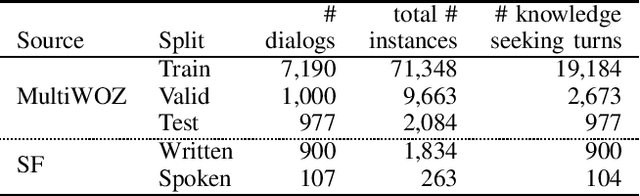

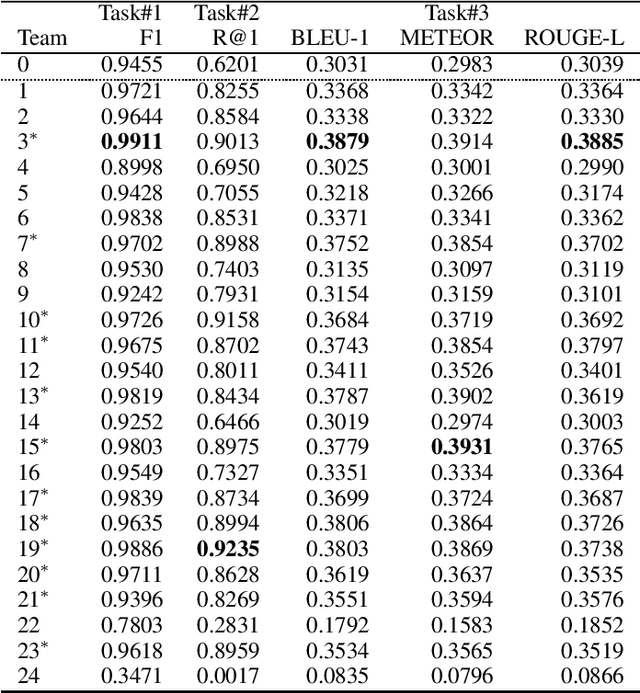
This paper introduces the Ninth Dialog System Technology Challenge (DSTC-9). This edition of the DSTC focuses on applying end-to-end dialog technologies for four distinct tasks in dialog systems, namely, 1. Task-oriented dialog Modeling with unstructured knowledge access, 2. Multi-domain task-oriented dialog, 3. Interactive evaluation of dialog, and 4. Situated interactive multi-modal dialog. This paper describes the task definition, provided datasets, baselines and evaluation set-up for each track. We also summarize the results of the submitted systems to highlight the overall trends of the state-of-the-art technologies for the tasks.
Situated and Interactive Multimodal Conversations
Jun 02, 2020
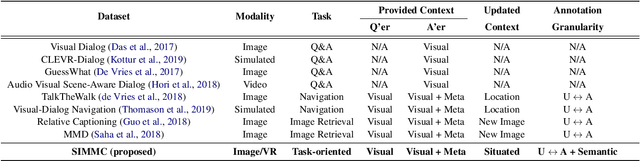
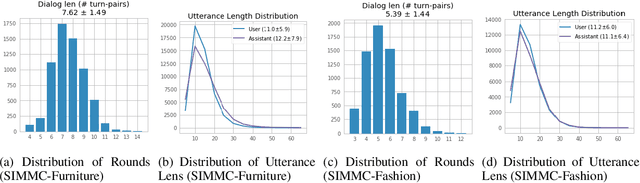
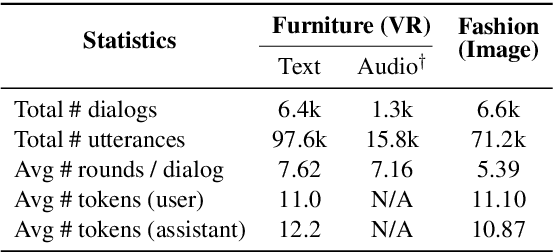
Next generation virtual assistants are envisioned to handle multimodal inputs (e.g., vision, memories of previous interactions, etc., in addition to the user's utterances), and perform multimodal actions (e.g., displaying a route in addition to generating the system's utterance). We introduce Situated Interactive MultiModal Conversations (SIMMC) as a new direction aimed at training agents that take multimodal actions grounded in a co-evolving multimodal input context in addition to the dialog history. We provide two SIMMC datasets totalling ~13K human-human dialogs (~169K utterances) using a multimodal Wizard-of-Oz (WoZ) setup, on two shopping domains: (a) furniture (grounded in a shared virtual environment) and, (b) fashion (grounded in an evolving set of images). We also provide logs of the items appearing in each scene, and contextual NLU and coreference annotations, using a novel and unified framework of SIMMC conversational acts for both user and assistant utterances. Finally, we present several tasks within SIMMC as objective evaluation protocols, such as Structural API Prediction and Response Generation. We benchmark a collection of existing models on these SIMMC tasks as strong baselines, and demonstrate rich multimodal conversational interactions. Our data, annotations, code, and models will be made publicly available.
SIMMC: Situated Interactive Multi-Modal Conversational Data Collection And Evaluation Platform
Nov 07, 2019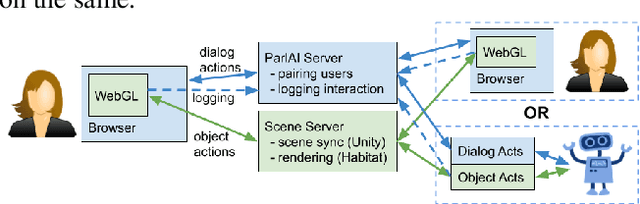
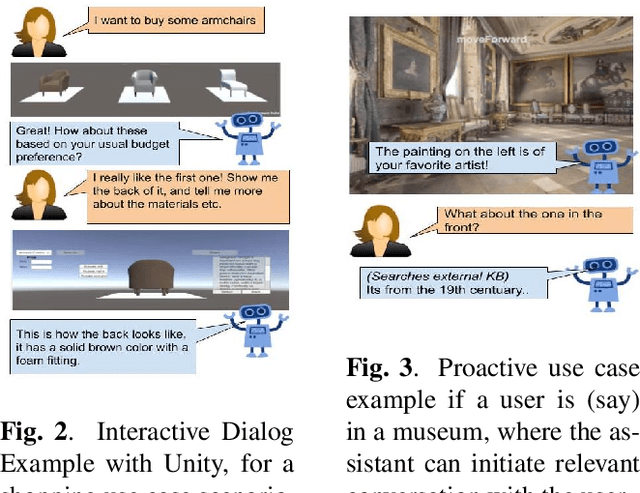
As digital virtual assistants become ubiquitous, it becomes increasingly important to understand the situated behaviour of users as they interact with these assistants. To this end, we introduce SIMMC, an extension to ParlAI for multi-modal conversational data collection and system evaluation. SIMMC simulates an immersive setup, where crowd workers are able to interact with environments constructed in AI Habitat or Unity while engaging in a conversation. The assistant in SIMMC can be a crowd worker or Artificial Intelligent (AI) agent. This enables both (i) a multi-player / Wizard of Oz setting for data collection, or (ii) a single player mode for model / system evaluation. We plan to open-source a situated conversational data-set collected on this platform for the Conversational AI research community.