 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeActivated LoRA: Fine-tuned LLMs for Intrinsics
Apr 16, 2025Low-Rank Adaptation (LoRA) has emerged as a highly efficient framework for finetuning the weights of large foundation models, and has become the go-to method for data-driven customization of LLMs. Despite the promise of highly customized behaviors and capabilities, switching between relevant LoRAs in a multiturn setting is highly inefficient, as the key-value (KV) cache of the entire turn history must be recomputed with the LoRA weights before generation can begin. To address this problem, we propose Activated LoRA (aLoRA), which modifies the LoRA framework to only adapt weights for the tokens in the sequence \emph{after} the aLoRA is invoked. This change crucially allows aLoRA to accept the base model's KV cache of the input string, meaning that aLoRA can be instantly activated whenever needed in a chain without recomputing the cache. This enables building what we call \emph{intrinsics}, i.e. highly specialized models invoked to perform well-defined operations on portions of an input chain or conversation that otherwise uses the base model by default. We use aLoRA to train a set of intrinsics models, demonstrating competitive accuracy with standard LoRA while achieving significant inference benefits.
A Library of LLM Intrinsics for Retrieval-Augmented Generation
Apr 16, 2025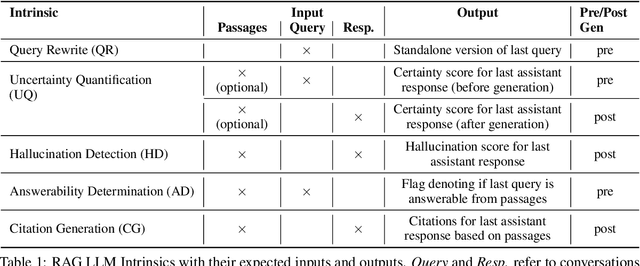
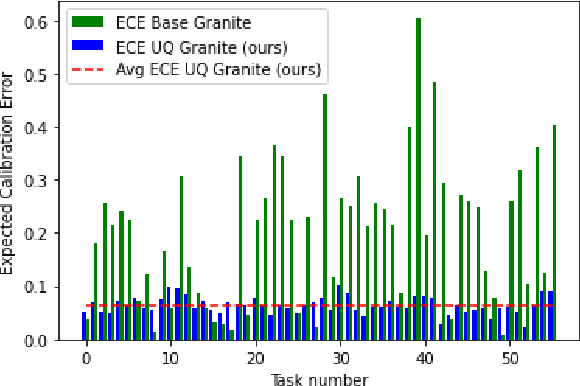

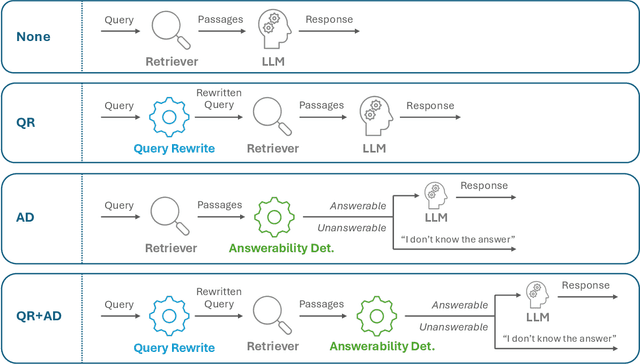
In the developer community for large language models (LLMs), there is not yet a clean pattern analogous to a software library, to support very large scale collaboration. Even for the commonplace use case of Retrieval-Augmented Generation (RAG), it is not currently possible to write a RAG application against a well-defined set of APIs that are agreed upon by different LLM providers. Inspired by the idea of compiler intrinsics, we propose some elements of such a concept through introducing a library of LLM Intrinsics for RAG. An LLM intrinsic is defined as a capability that can be invoked through a well-defined API that is reasonably stable and independent of how the LLM intrinsic itself is implemented. The intrinsics in our library are released as LoRA adapters on HuggingFace, and through a software interface with clear structured input/output characteristics on top of vLLM as an inference platform, accompanied in both places with documentation and code. This article describes the intended usage, training details, and evaluations for each intrinsic, as well as compositions of multiple intrinsics.
MTRAG: A Multi-Turn Conversational Benchmark for Evaluating Retrieval-Augmented Generation Systems
Jan 07, 2025



Retrieval-augmented generation (RAG) has recently become a very popular task for Large Language Models (LLMs). Evaluating them on multi-turn RAG conversations, where the system is asked to generate a response to a question in the context of a preceding conversation is an important and often overlooked task with several additional challenges. We present MTRAG: an end-to-end human-generated multi-turn RAG benchmark that reflects several real-world properties across diverse dimensions for evaluating the full RAG pipeline. MTRAG contains 110 conversations averaging 7.7 turns each across four domains for a total of 842 tasks. We also explore automation paths via synthetic data and LLM-as-a-Judge evaluation. Our human and automatic evaluations show that even state-of-the-art LLM RAG systems struggle on MTRAG. We demonstrate the need for strong retrieval and generation systems that can handle later turns, unanswerable questions, non-standalone questions, and multiple domains. MTRAG is available at https://github.com/ibm/mt-rag-benchmark.
Reducing the Scope of Language Models with Circuit Breakers
Oct 28, 2024Language models are now deployed in a wide variety of user-facing applications, often for specific purposes like answering questions about documentation or acting as coding assistants. As these models are intended for particular purposes, they should not be able to answer irrelevant queries like requests for poetry or questions about physics, or even worse, queries that can only be answered by humans like sensitive company policies. Instead we would like them to only answer queries corresponding to desired behavior and refuse all other requests, which we refer to as scoping. We find that, despite the use of system prompts, two representative language models can be poorly scoped and respond to queries they should not be addressing. We then conduct a comprehensive empirical evaluation of methods which could be used for scoping the behavior of language models. Among many other results, we show that a recently-proposed method for general alignment, Circuit Breakers (CB), can be adapted to scope language models to very specific tasks like sentiment analysis or summarization or even tasks with finer-grained scoping (e.g. summarizing only news articles). When compared to standard methods like fine-tuning or preference learning, CB is more robust both for out of distribution tasks, and to adversarial prompting techniques. We also show that layering SFT and CB together often results in the best of both worlds: improved performance only on relevant queries, while rejecting irrelevant ones.
Multi-Document Grounded Multi-Turn Synthetic Dialog Generation
Sep 17, 2024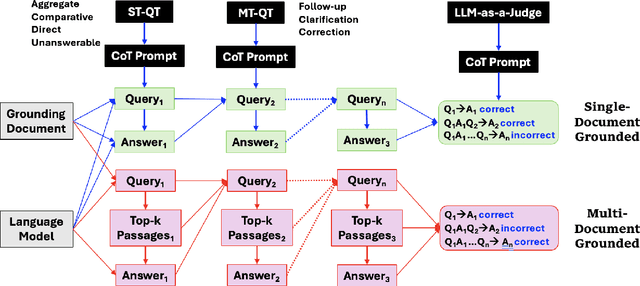
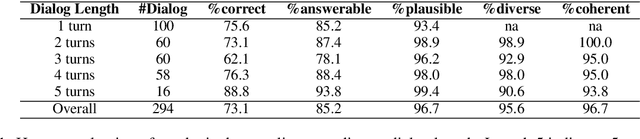
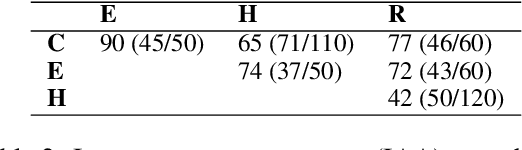
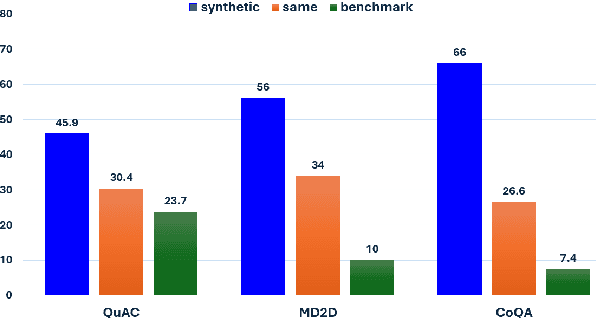
We introduce a technique for multi-document grounded multi-turn synthetic dialog generation that incorporates three main ideas. First, we control the overall dialog flow using taxonomy-driven user queries that are generated with Chain-of-Thought (CoT) prompting. Second, we support the generation of multi-document grounded dialogs by mimicking real-world use of retrievers to update the grounding documents after every user-turn in the dialog. Third, we apply LLM-as-a-Judge to filter out queries with incorrect answers. Human evaluation of the synthetic dialog data suggests that the data is diverse, coherent, and includes mostly correct answers. Both human and automatic evaluations of answerable queries indicate that models fine-tuned on synthetic dialogs consistently out-perform those fine-tuned on existing human generated training data across four publicly available multi-turn document grounded benchmark test sets.
Granite-Function Calling Model: Introducing Function Calling Abilities via Multi-task Learning of Granular Tasks
Jun 27, 2024



Large language models (LLMs) have recently shown tremendous promise in serving as the backbone to agentic systems, as demonstrated by their performance in multi-faceted, challenging benchmarks like SWE-Bench and Agent-Bench. However, to realize the true potential of LLMs as autonomous agents, they must learn to identify, call, and interact with external tools and application program interfaces (APIs) to complete complex tasks. These tasks together are termed function calling. Endowing LLMs with function calling abilities leads to a myriad of advantages, such as access to current and domain-specific information in databases and knowledge sources, and the ability to outsource tasks that can be reliably performed by tools, e.g., a Python interpreter or calculator. While there has been significant progress in function calling with LLMs, there is still a dearth of open models that perform on par with proprietary LLMs like GPT, Claude, and Gemini. Therefore, in this work, we introduce the GRANITE-20B-FUNCTIONCALLING model under an Apache 2.0 license. The model is trained using a multi-task training approach on seven fundamental tasks encompassed in function calling, those being Nested Function Calling, Function Chaining, Parallel Functions, Function Name Detection, Parameter-Value Pair Detection, Next-Best Function, and Response Generation. We present a comprehensive evaluation on multiple out-of-domain datasets comparing GRANITE-20B-FUNCTIONCALLING to more than 15 other best proprietary and open models. GRANITE-20B-FUNCTIONCALLING provides the best performance among all open models on the Berkeley Function Calling Leaderboard and fourth overall. As a result of the diverse tasks and datasets used for training our model, we show that GRANITE-20B-FUNCTIONCALLING has better generalizability on multiple tasks in seven different evaluation datasets.
Evaluating Robustness of Dialogue Summarization Models in the Presence of Naturally Occurring Variations
Nov 15, 2023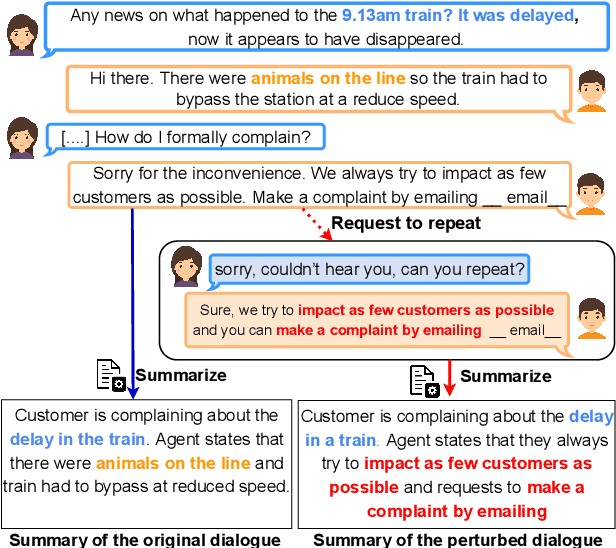
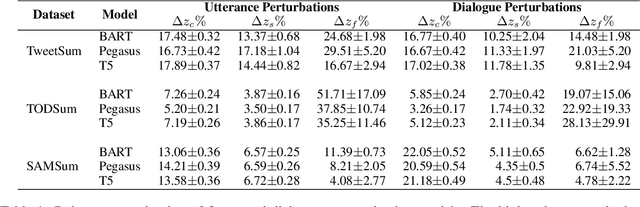
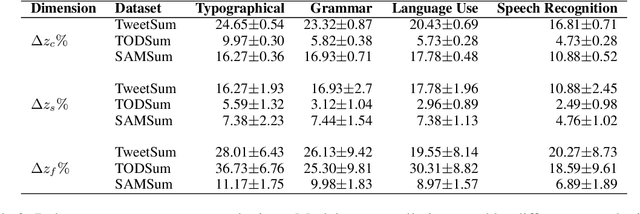
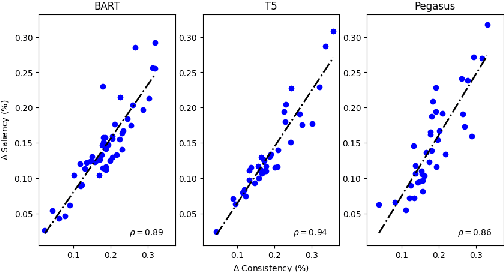
Dialogue summarization task involves summarizing long conversations while preserving the most salient information. Real-life dialogues often involve naturally occurring variations (e.g., repetitions, hesitations) and existing dialogue summarization models suffer from performance drop on such conversations. In this study, we systematically investigate the impact of such variations on state-of-the-art dialogue summarization models using publicly available datasets. To simulate real-life variations, we introduce two types of perturbations: utterance-level perturbations that modify individual utterances with errors and language variations, and dialogue-level perturbations that add non-informative exchanges (e.g., repetitions, greetings). We conduct our analysis along three dimensions of robustness: consistency, saliency, and faithfulness, which capture different aspects of the summarization model's performance. We find that both fine-tuned and instruction-tuned models are affected by input variations, with the latter being more susceptible, particularly to dialogue-level perturbations. We also validate our findings via human evaluation. Finally, we investigate if the robustness of fine-tuned models can be improved by training them with a fraction of perturbed data and observe that this approach is insufficient to address robustness challenges with current models and thus warrants a more thorough investigation to identify better solutions. Overall, our work highlights robustness challenges in dialogue summarization and provides insights for future research.
MISMATCH: Fine-grained Evaluation of Machine-generated Text with Mismatch Error Types
Jun 18, 2023



With the growing interest in large language models, the need for evaluating the quality of machine text compared to reference (typically human-generated) text has become focal attention. Most recent works focus either on task-specific evaluation metrics or study the properties of machine-generated text captured by the existing metrics. In this work, we propose a new evaluation scheme to model human judgments in 7 NLP tasks, based on the fine-grained mismatches between a pair of texts. Inspired by the recent efforts in several NLP tasks for fine-grained evaluation, we introduce a set of 13 mismatch error types such as spatial/geographic errors, entity errors, etc, to guide the model for better prediction of human judgments. We propose a neural framework for evaluating machine texts that uses these mismatch error types as auxiliary tasks and re-purposes the existing single-number evaluation metrics as additional scalar features, in addition to textual features extracted from the machine and reference texts. Our experiments reveal key insights about the existing metrics via the mismatch errors. We show that the mismatch errors between the sentence pairs on the held-out datasets from 7 NLP tasks align well with the human evaluation.
The Benefits of Bad Advice: Autocontrastive Decoding across Model Layers
May 02, 2023



Applying language models to natural language processing tasks typically relies on the representations in the final model layer, as intermediate hidden layer representations are presumed to be less informative. In this work, we argue that due to the gradual improvement across model layers, additional information can be gleaned from the contrast between higher and lower layers during inference. Specifically, in choosing between the probable next token predictions of a generative model, the predictions of lower layers can be used to highlight which candidates are best avoided. We propose a novel approach that utilizes the contrast between layers to improve text generation outputs, and show that it mitigates degenerative behaviors of the model in open-ended generation, significantly improving the quality of generated texts. Furthermore, our results indicate that contrasting between model layers at inference time can yield substantial benefits to certain aspects of general language model capabilities, more effectively extracting knowledge during inference from a given set of model parameters.
Semi-Structured Object Sequence Encoders
Jan 10, 2023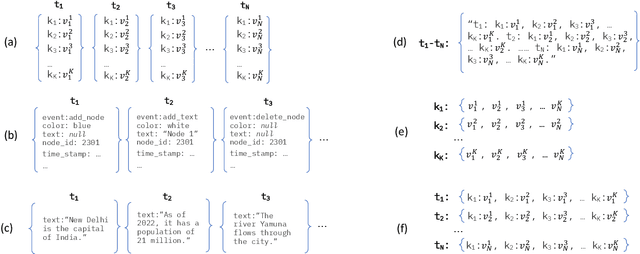

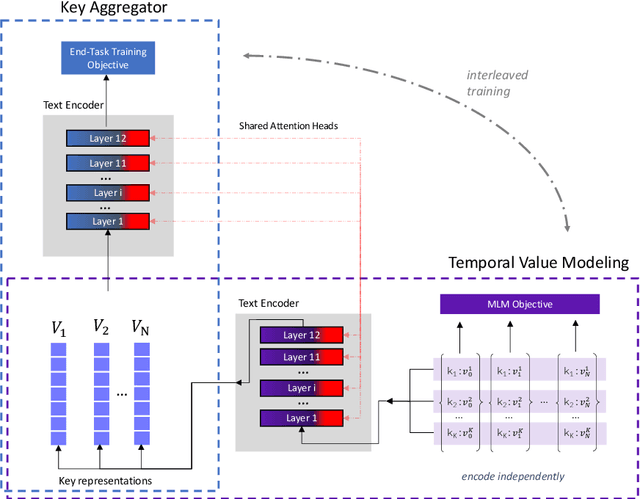
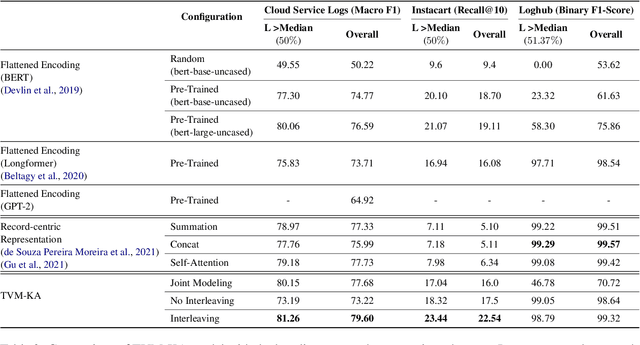
In this paper we explore the task of modeling (semi) structured object sequences; in particular we focus our attention on the problem of developing a structure-aware input representation for such sequences. In such sequences, we assume that each structured object is represented by a set of key-value pairs which encode the attributes of the structured object. Given a universe of keys, a sequence of structured objects can then be viewed as an evolution of the values for each key, over time. We encode and construct a sequential representation using the values for a particular key (Temporal Value Modeling - TVM) and then self-attend over the set of key-conditioned value sequences to a create a representation of the structured object sequence (Key Aggregation - KA). We pre-train and fine-tune the two components independently and present an innovative training schedule that interleaves the training of both modules with shared attention heads. We find that this iterative two part-training results in better performance than a unified network with hierarchical encoding as well as over, other methods that use a {\em record-view} representation of the sequence \cite{de2021transformers4rec} or a simple {\em flattened} representation of the sequence. We conduct experiments using real-world data to demonstrate the advantage of interleaving TVM-KA on multiple tasks and detailed ablation studies motivating our modeling choices. We find that our approach performs better than flattening sequence objects and also allows us to operate on significantly larger sequences than existing methods.