 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn Analysis of Hyper-Parameter Optimization Methods for Retrieval Augmented Generation
May 06, 2025Finding the optimal Retrieval-Augmented Generation (RAG) configuration for a given use case can be complex and expensive. Motivated by this challenge, frameworks for RAG hyper-parameter optimization (HPO) have recently emerged, yet their effectiveness has not been rigorously benchmarked. To address this gap, we present a comprehensive study involving 5 HPO algorithms over 5 datasets from diverse domains, including a new one collected for this work on real-world product documentation. Our study explores the largest HPO search space considered to date, with two optimized evaluation metrics. Analysis of the results shows that RAG HPO can be done efficiently, either greedily or with iterative random search, and that it significantly boosts RAG performance for all datasets. For greedy HPO approaches, we show that optimizing models first is preferable to the prevalent practice of optimizing sequentially according to the RAG pipeline order.
Label-Efficient Model Selection for Text Generation
Feb 12, 2024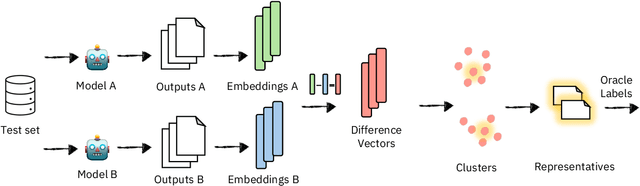

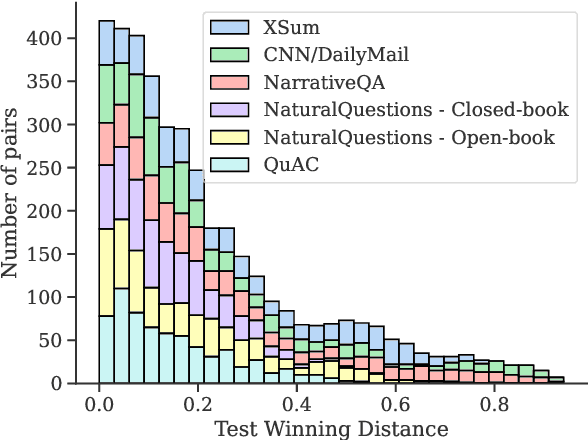
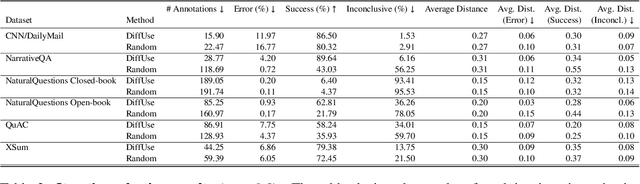
Model selection for a given target task can be costly, as it may entail extensive annotation of the quality of outputs of different models. We introduce DiffUse, an efficient method to make an informed decision between candidate text generation models. DiffUse reduces the required amount of preference annotations, thus saving valuable time and resources in performing evaluation. DiffUse intelligently selects instances by clustering embeddings that represent the semantic differences between model outputs. Thus, it is able to identify a subset of examples that are more informative for preference decisions. Our method is model-agnostic, and can be applied to any text generation model. Moreover, we propose a practical iterative approach for dynamically determining how many instances to annotate. In a series of experiments over hundreds of model pairs, we demonstrate that DiffUse can dramatically reduce the required number of annotations -- by up to 75% -- while maintaining high evaluation reliability.
The Benefits of Bad Advice: Autocontrastive Decoding across Model Layers
May 02, 2023



Applying language models to natural language processing tasks typically relies on the representations in the final model layer, as intermediate hidden layer representations are presumed to be less informative. In this work, we argue that due to the gradual improvement across model layers, additional information can be gleaned from the contrast between higher and lower layers during inference. Specifically, in choosing between the probable next token predictions of a generative model, the predictions of lower layers can be used to highlight which candidates are best avoided. We propose a novel approach that utilizes the contrast between layers to improve text generation outputs, and show that it mitigates degenerative behaviors of the model in open-ended generation, significantly improving the quality of generated texts. Furthermore, our results indicate that contrasting between model layers at inference time can yield substantial benefits to certain aspects of general language model capabilities, more effectively extracting knowledge during inference from a given set of model parameters.
Heuristic-based Inter-training to Improve Few-shot Multi-perspective Dialog Summarization
Mar 30, 2022
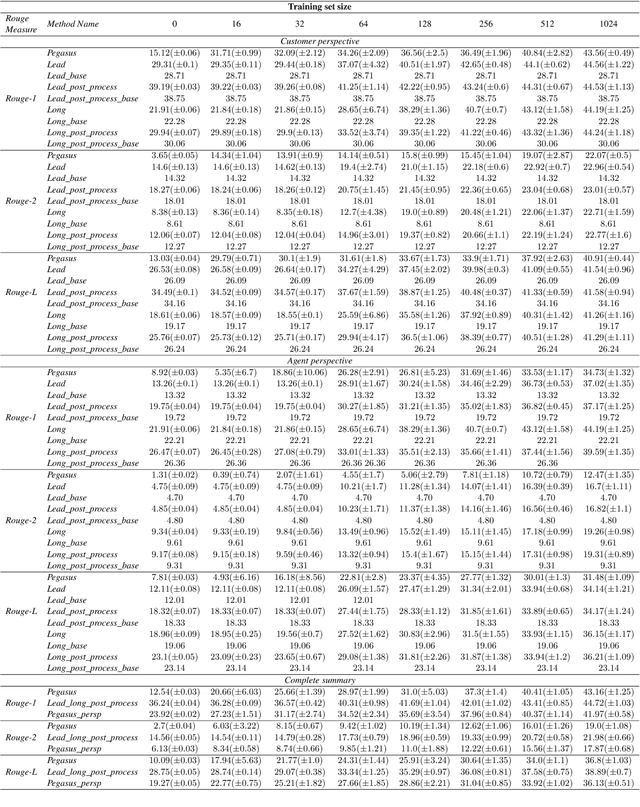
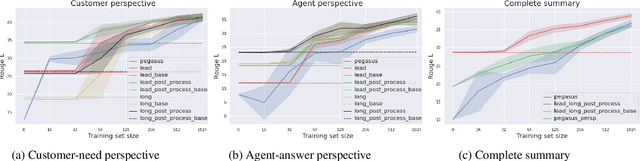
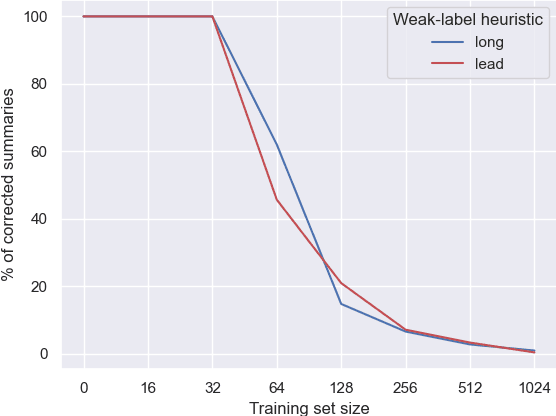
Many organizations require their customer-care agents to manually summarize their conversations with customers. These summaries are vital for decision making purposes of the organizations. The perspective of the summary that is required to be created depends on the application of the summaries. With this work, we study the multi-perspective summarization of customer-care conversations between support agents and customers. We observe that there are different heuristics that are associated with summaries of different perspectives, and explore these heuristics to create weak-labeled data for intermediate training of the models before fine-tuning with scarce human annotated summaries. Most importantly, we show that our approach supports models to generate multi-perspective summaries with a very small amount of annotated data. For example, our approach achieves 94\% of the performance (Rouge-2) of a model trained with the original data, by training only with 7\% of the original data.
TWEETSUMM -- A Dialog Summarization Dataset for Customer Service
Nov 23, 2021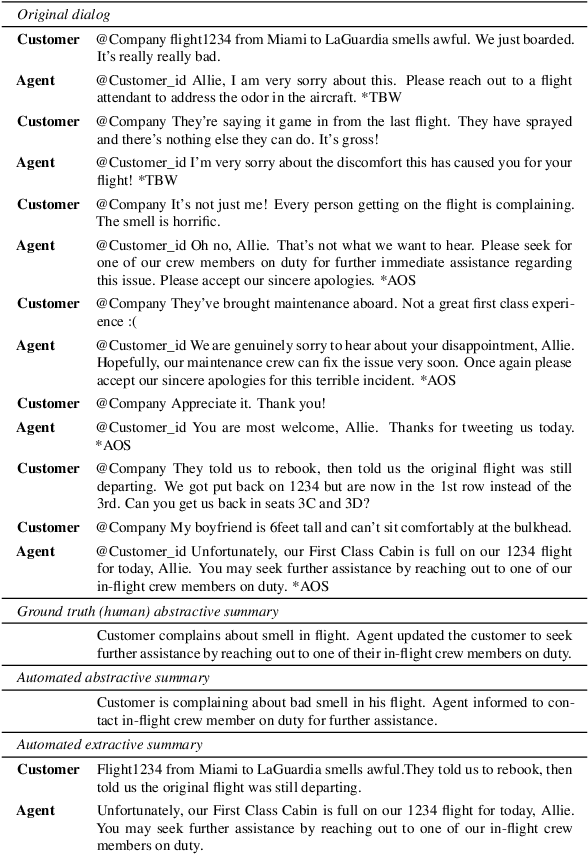
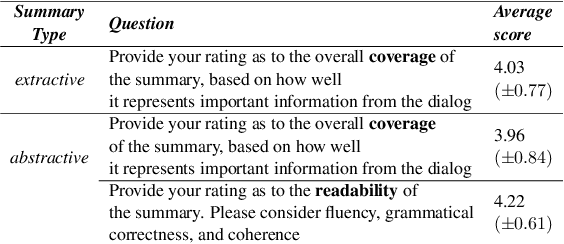


In a typical customer service chat scenario, customers contact a support center to ask for help or raise complaints, and human agents try to solve the issues. In most cases, at the end of the conversation, agents are asked to write a short summary emphasizing the problem and the proposed solution, usually for the benefit of other agents that may have to deal with the same customer or issue. The goal of the present article is advancing the automation of this task. We introduce the first large scale, high quality, customer care dialog summarization dataset with close to 6500 human annotated summaries. The data is based on real-world customer support dialogs and includes both extractive and abstractive summaries. We also introduce a new unsupervised, extractive summarization method specific to dialogs.
HowSumm: A Multi-Document Summarization Dataset Derived from WikiHow Articles
Oct 08, 2021



We present HowSumm, a novel large-scale dataset for the task of query-focused multi-document summarization (qMDS), which targets the use-case of generating actionable instructions from a set of sources. This use-case is different from the use-cases covered in existing multi-document summarization (MDS) datasets and is applicable to educational and industrial scenarios. We employed automatic methods, and leveraged statistics from existing human-crafted qMDS datasets, to create HowSumm from wikiHow website articles and the sources they cite. We describe the creation of the dataset and discuss the unique features that distinguish it from other summarization corpora. Automatic and human evaluations of both extractive and abstractive summarization models on the dataset reveal that there is room for improvement.
Summary Grounded Conversation Generation
Jun 07, 2021


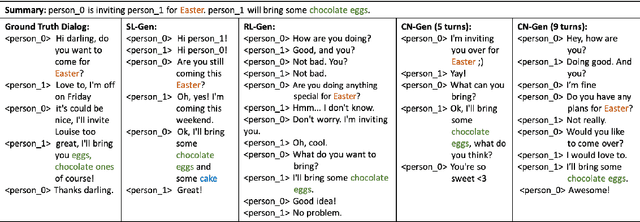
Many conversation datasets have been constructed in the recent years using crowdsourcing. However, the data collection process can be time consuming and presents many challenges to ensure data quality. Since language generation has improved immensely in recent years with the advancement of pre-trained language models, we investigate how such models can be utilized to generate entire conversations, given only a summary of a conversation as the input. We explore three approaches to generate summary grounded conversations, and evaluate the generated conversations using automatic measures and human judgements. We also show that the accuracy of conversation summarization can be improved by augmenting a conversation summarization dataset with generated conversations.
Financial Event Extraction Using Wikipedia-Based Weak Supervision
Nov 25, 2019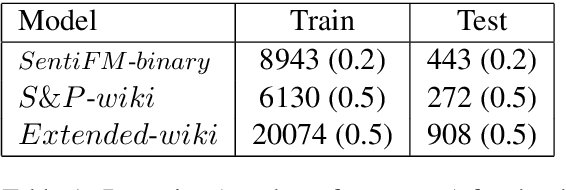
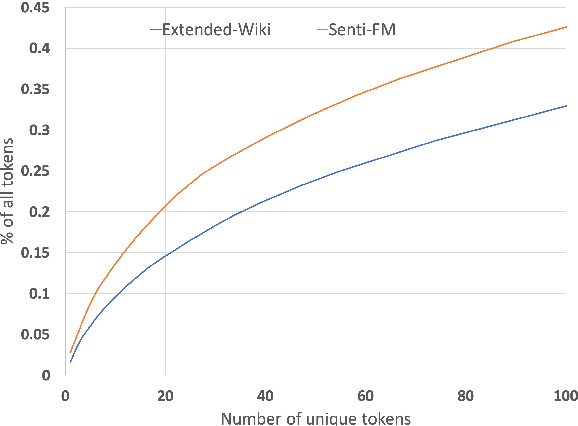
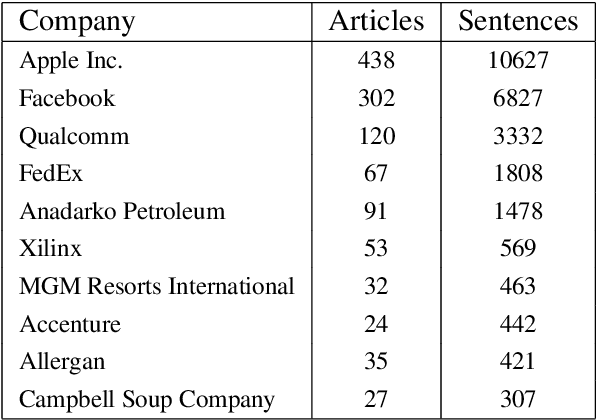
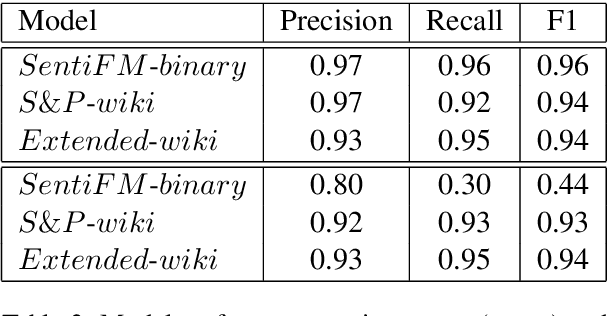
Extraction of financial and economic events from text has previously been done mostly using rule-based methods, with more recent works employing machine learning techniques. This work is in line with this latter approach, leveraging relevant Wikipedia sections to extract weak labels for sentences describing economic events. Whereas previous weakly supervised approaches required a knowledge-base of such events, or corresponding financial figures, our approach requires no such additional data, and can be employed to extract economic events related to companies which are not even mentioned in the training data.
Corpus Wide Argument Mining -- a Working Solution
Nov 25, 2019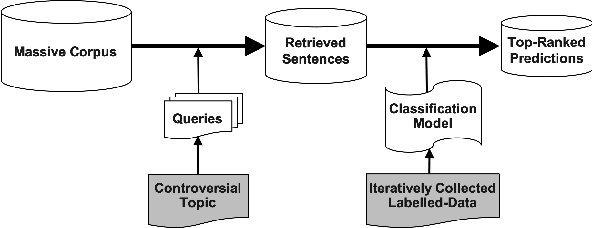
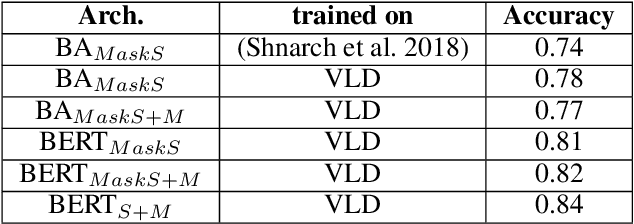
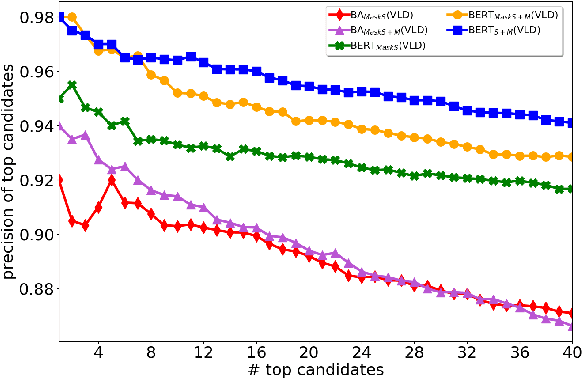
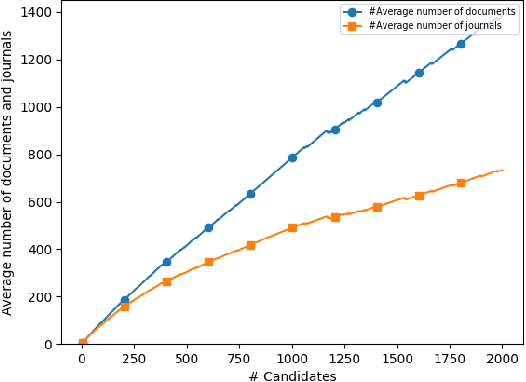
One of the main tasks in argument mining is the retrieval of argumentative content pertaining to a given topic. Most previous work addressed this task by retrieving a relatively small number of relevant documents as the initial source for such content. This line of research yielded moderate success, which is of limited use in a real-world system. Furthermore, for such a system to yield a comprehensive set of relevant arguments, over a wide range of topics, it requires leveraging a large and diverse corpus in an appropriate manner. Here we present a first end-to-end high-precision, corpus-wide argument mining system. This is made possible by combining sentence-level queries over an appropriate indexing of a very large corpus of newspaper articles, with an iterative annotation scheme. This scheme addresses the inherent label bias in the data and pinpoints the regions of the sample space whose manual labeling is required to obtain high-precision among top-ranked candidates.
Argument Invention from First Principles
Aug 22, 2019


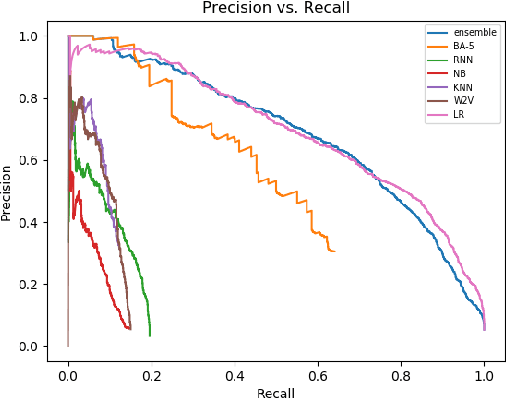
Competitive debaters often find themselves facing a challenging task -- how to debate a topic they know very little about, with only minutes to prepare, and without access to books or the Internet? What they often do is rely on "first principles", commonplace arguments which are relevant to many topics, and which they have refined in past debates. In this work we aim to explicitly define a taxonomy of such principled recurring arguments, and, given a controversial topic, to automatically identify which of these arguments are relevant to the topic. As far as we know, this is the first time that this approach to argument invention is formalized and made explicit in the context of NLP. The main goal of this work is to show that it is possible to define such a taxonomy. While the taxonomy suggested here should be thought of as a "first attempt" it is nonetheless coherent, covers well the relevant topics and coincides with what professional debaters actually argue in their speeches, and facilitates automatic argument invention for new topics.