 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGranite-Function Calling Model: Introducing Function Calling Abilities via Multi-task Learning of Granular Tasks
Jun 27, 2024



Large language models (LLMs) have recently shown tremendous promise in serving as the backbone to agentic systems, as demonstrated by their performance in multi-faceted, challenging benchmarks like SWE-Bench and Agent-Bench. However, to realize the true potential of LLMs as autonomous agents, they must learn to identify, call, and interact with external tools and application program interfaces (APIs) to complete complex tasks. These tasks together are termed function calling. Endowing LLMs with function calling abilities leads to a myriad of advantages, such as access to current and domain-specific information in databases and knowledge sources, and the ability to outsource tasks that can be reliably performed by tools, e.g., a Python interpreter or calculator. While there has been significant progress in function calling with LLMs, there is still a dearth of open models that perform on par with proprietary LLMs like GPT, Claude, and Gemini. Therefore, in this work, we introduce the GRANITE-20B-FUNCTIONCALLING model under an Apache 2.0 license. The model is trained using a multi-task training approach on seven fundamental tasks encompassed in function calling, those being Nested Function Calling, Function Chaining, Parallel Functions, Function Name Detection, Parameter-Value Pair Detection, Next-Best Function, and Response Generation. We present a comprehensive evaluation on multiple out-of-domain datasets comparing GRANITE-20B-FUNCTIONCALLING to more than 15 other best proprietary and open models. GRANITE-20B-FUNCTIONCALLING provides the best performance among all open models on the Berkeley Function Calling Leaderboard and fourth overall. As a result of the diverse tasks and datasets used for training our model, we show that GRANITE-20B-FUNCTIONCALLING has better generalizability on multiple tasks in seven different evaluation datasets.
Heuristic-based Inter-training to Improve Few-shot Multi-perspective Dialog Summarization
Mar 30, 2022
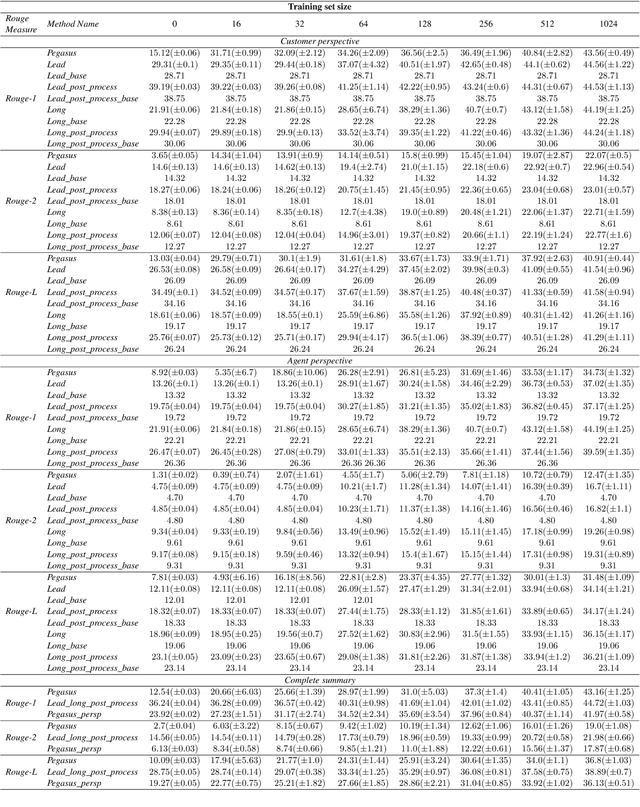
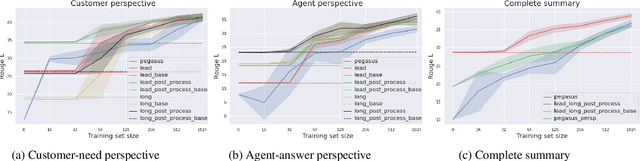
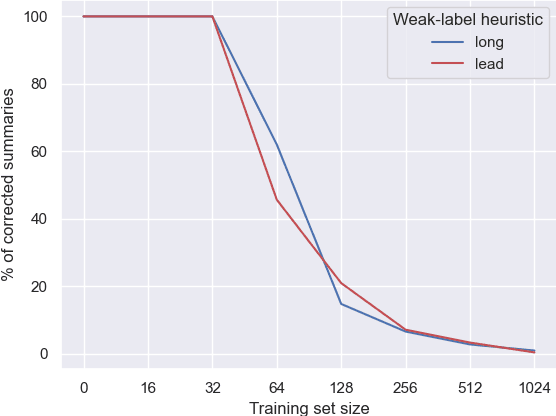
Many organizations require their customer-care agents to manually summarize their conversations with customers. These summaries are vital for decision making purposes of the organizations. The perspective of the summary that is required to be created depends on the application of the summaries. With this work, we study the multi-perspective summarization of customer-care conversations between support agents and customers. We observe that there are different heuristics that are associated with summaries of different perspectives, and explore these heuristics to create weak-labeled data for intermediate training of the models before fine-tuning with scarce human annotated summaries. Most importantly, we show that our approach supports models to generate multi-perspective summaries with a very small amount of annotated data. For example, our approach achieves 94\% of the performance (Rouge-2) of a model trained with the original data, by training only with 7\% of the original data.