 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDebatable Intelligence: Benchmarking LLM Judges via Debate Speech Evaluation
Jun 05, 2025We introduce Debate Speech Evaluation as a novel and challenging benchmark for assessing LLM judges. Evaluating debate speeches requires a deep understanding of the speech at multiple levels, including argument strength and relevance, the coherence and organization of the speech, the appropriateness of its style and tone, and so on. This task involves a unique set of cognitive abilities that have previously received limited attention in systematic LLM benchmarking. To explore such skills, we leverage a dataset of over 600 meticulously annotated debate speeches and present the first in-depth analysis of how state-of-the-art LLMs compare to human judges on this task. Our findings reveal a nuanced picture: while larger models can approximate individual human judgments in some respects, they differ substantially in their overall judgment behavior. We also investigate the ability of frontier LLMs to generate persuasive, opinionated speeches, showing that models may perform at a human level on this task.
Conversational Prompt Engineering
Aug 08, 2024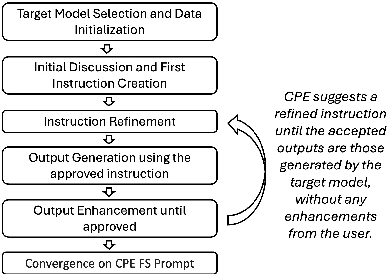

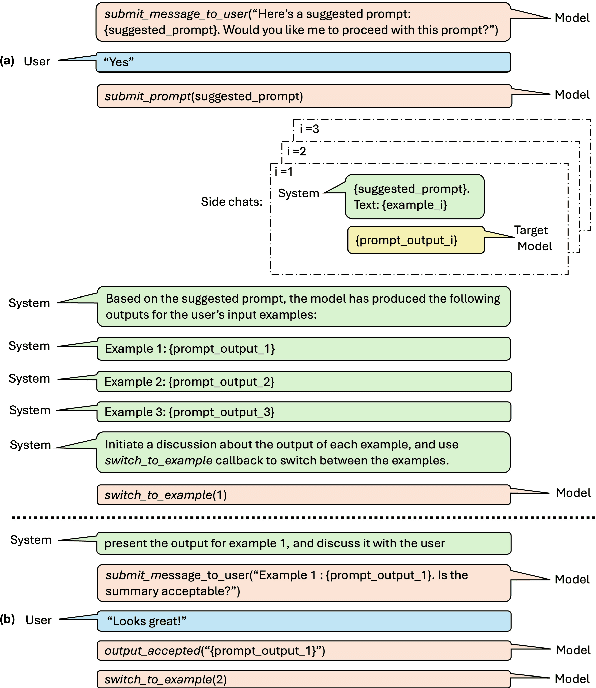
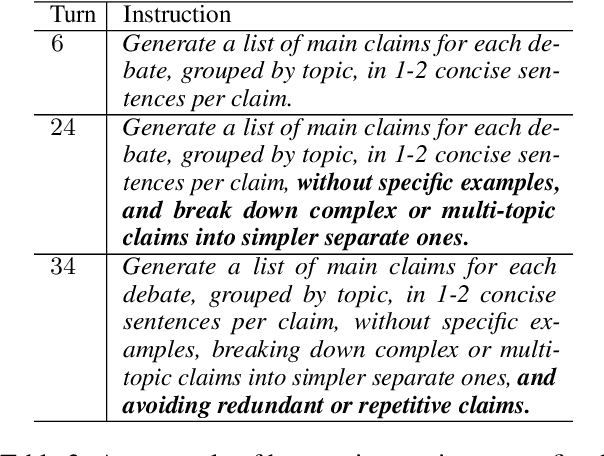
Prompts are how humans communicate with LLMs. Informative prompts are essential for guiding LLMs to produce the desired output. However, prompt engineering is often tedious and time-consuming, requiring significant expertise, limiting its widespread use. We propose Conversational Prompt Engineering (CPE), a user-friendly tool that helps users create personalized prompts for their specific tasks. CPE uses a chat model to briefly interact with users, helping them articulate their output preferences and integrating these into the prompt. The process includes two main stages: first, the model uses user-provided unlabeled data to generate data-driven questions and utilize user responses to shape the initial instruction. Then, the model shares the outputs generated by the instruction and uses user feedback to further refine the instruction and the outputs. The final result is a few-shot prompt, where the outputs approved by the user serve as few-shot examples. A user study on summarization tasks demonstrates the value of CPE in creating personalized, high-performing prompts. The results suggest that the zero-shot prompt obtained is comparable to its - much longer - few-shot counterpart, indicating significant savings in scenarios involving repetitive tasks with large text volumes.
Stay Tuned: An Empirical Study of the Impact of Hyperparameters on LLM Tuning in Real-World Applications
Jul 25, 2024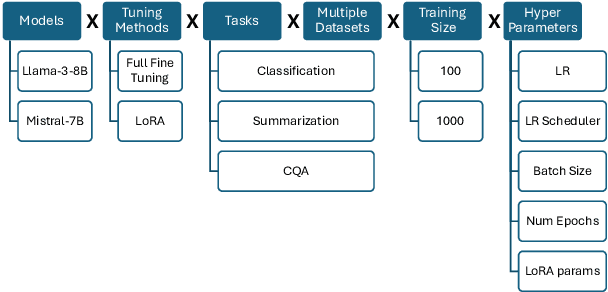


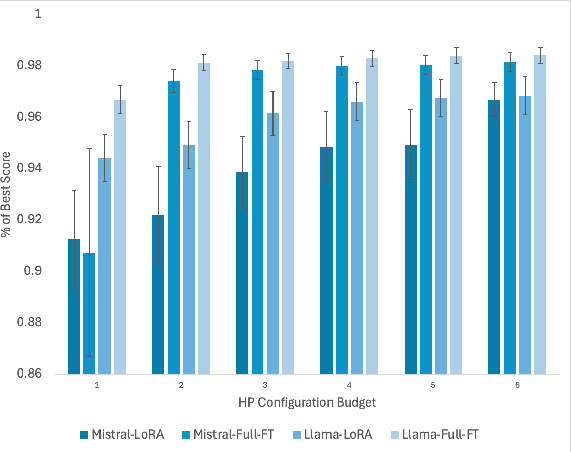
Fine-tuning Large Language Models (LLMs) is an effective method to enhance their performance on downstream tasks. However, choosing the appropriate setting of tuning hyperparameters (HPs) is a labor-intensive and computationally expensive process. Here, we provide recommended HP configurations for practical use-cases that represent a better starting point for practitioners, when considering two SOTA LLMs and two commonly used tuning methods. We describe Coverage-based Search (CBS), a process for ranking HP configurations based on an offline extensive grid search, such that the top ranked configurations collectively provide a practical robust recommendation for a wide range of datasets and domains. We focus our experiments on Llama-3-8B and Mistral-7B, as well as full fine-tuning and LoRa, conducting a total of > 10,000 tuning experiments. Our results suggest that, in general, Llama-3-8B and LoRA should be preferred, when possible. Moreover, we show that for both models and tuning methods, exploring only a few HP configurations, as recommended by our analysis, can provide excellent results in practice, making this work a valuable resource for practitioners.
Efficient Benchmarking (of Language Models)
Aug 31, 2023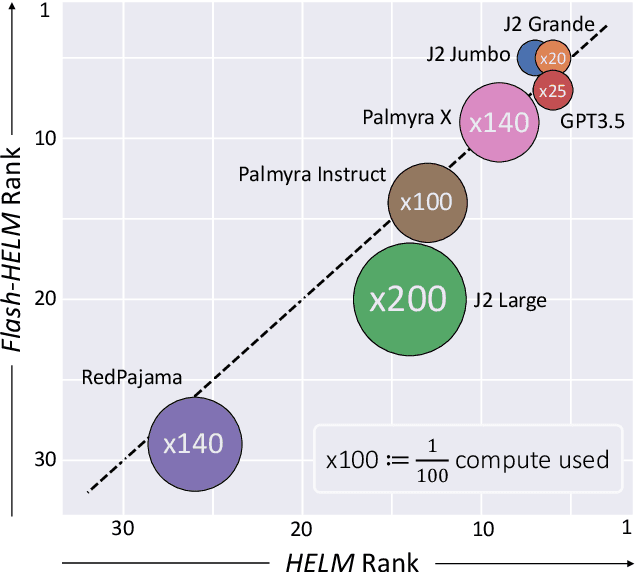
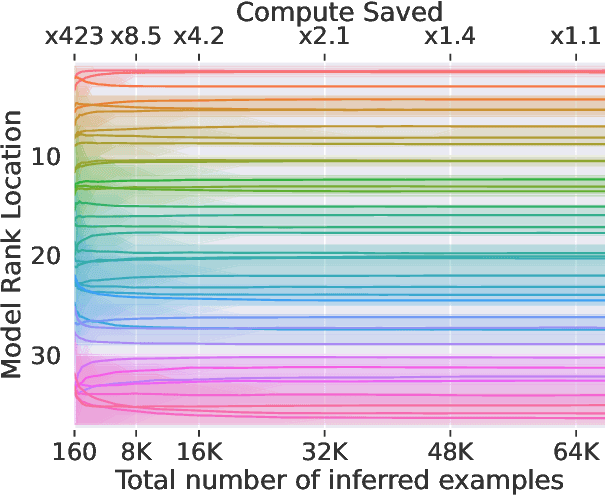
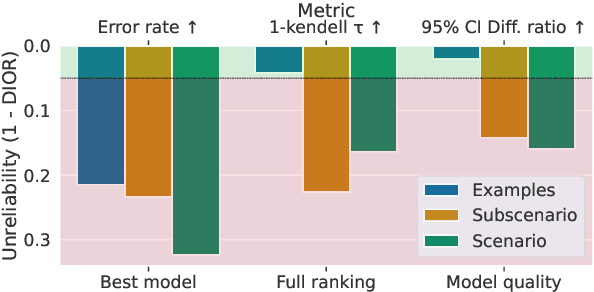
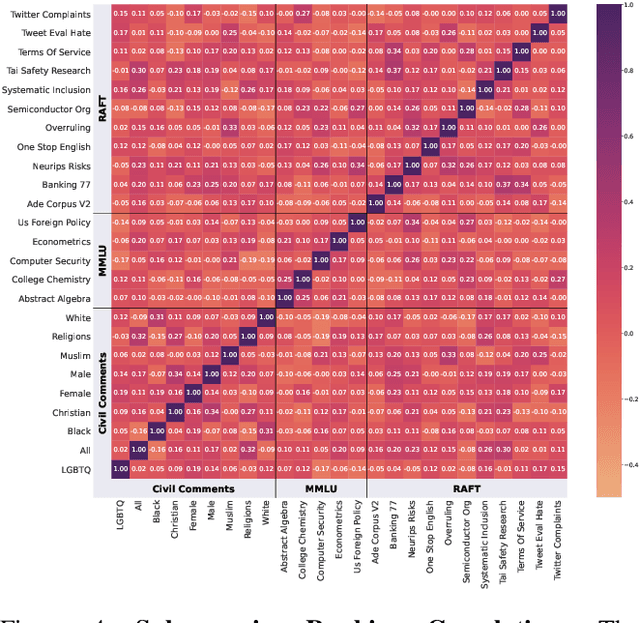
The increasing versatility of language models LMs has given rise to a new class of benchmarks that comprehensively assess a broad range of capabilities. Such benchmarks are associated with massive computational costs reaching thousands of GPU hours per model. However the efficiency aspect of these evaluation efforts had raised little discussion in the literature. In this work we present the problem of Efficient Benchmarking namely intelligently reducing the computation costs of LM evaluation without compromising reliability. Using the HELM benchmark as a test case we investigate how different benchmark design choices affect the computation-reliability tradeoff. We propose to evaluate the reliability of such decisions by using a new measure Decision Impact on Reliability DIoR for short. We find for example that the current leader on HELM may change by merely removing a low-ranked model from the benchmark and observe that a handful of examples suffice to obtain the correct benchmark ranking. Conversely a slightly different choice of HELM scenarios varies ranking widely. Based on our findings we outline a set of concrete recommendations for more efficient benchmark design and utilization practices leading to dramatic cost savings with minimal loss of benchmark reliability often reducing computation by x100 or more.
Active Learning for Natural Language Generation
May 24, 2023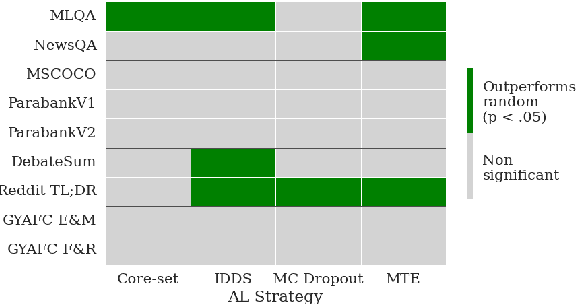

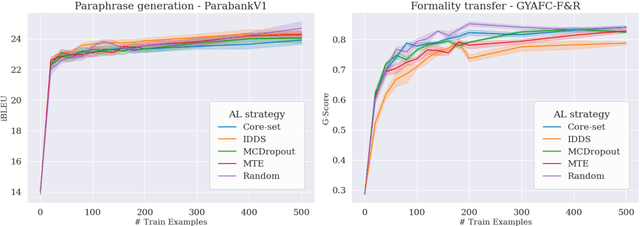

The field of text generation suffers from a severe shortage of labeled data due to the extremely expensive and time consuming process involved in manual annotation. A natural approach for coping with this problem is active learning (AL), a well-known machine learning technique for improving annotation efficiency by selectively choosing the most informative examples to label. However, while AL has been well-researched in the context of text classification, its application to text generation remained largely unexplored. In this paper, we present a first systematic study of active learning for text generation, considering a diverse set of tasks and multiple leading AL strategies. Our results indicate that existing AL strategies, despite their success in classification, are largely ineffective for the text generation scenario, and fail to consistently surpass the baseline of random example selection. We highlight some notable differences between the classification and generation scenarios, and analyze the selection behaviors of existing AL strategies. Our findings motivate exploring novel approaches for applying AL to NLG tasks.
The Benefits of Bad Advice: Autocontrastive Decoding across Model Layers
May 02, 2023



Applying language models to natural language processing tasks typically relies on the representations in the final model layer, as intermediate hidden layer representations are presumed to be less informative. In this work, we argue that due to the gradual improvement across model layers, additional information can be gleaned from the contrast between higher and lower layers during inference. Specifically, in choosing between the probable next token predictions of a generative model, the predictions of lower layers can be used to highlight which candidates are best avoided. We propose a novel approach that utilizes the contrast between layers to improve text generation outputs, and show that it mitigates degenerative behaviors of the model in open-ended generation, significantly improving the quality of generated texts. Furthermore, our results indicate that contrasting between model layers at inference time can yield substantial benefits to certain aspects of general language model capabilities, more effectively extracting knowledge during inference from a given set of model parameters.
Knowledge is a Region in Weight Space for Fine-tuned Language Models
Feb 12, 2023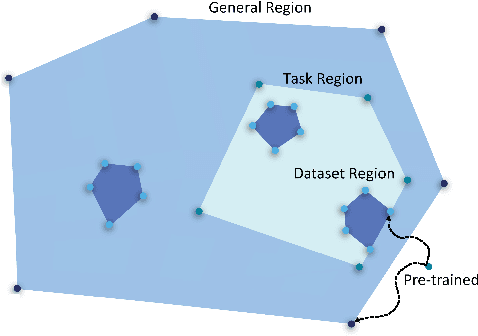

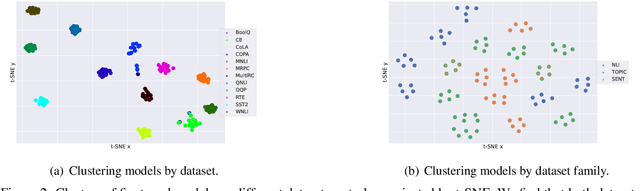

Research on neural networks has largely focused on understanding a single model trained on a single dataset. However, relatively little is known about the relationships between different models, especially those trained or tested on different datasets. We address this by studying how the weight space and underlying loss landscape of different models are interconnected. Specifically, we demonstrate that fine-tuned models that were optimized for high performance, reside in well-defined regions in weight space, and vice versa -- that any model that resides anywhere in those regions also has high performance. Specifically, we show that language models that have been fine-tuned on the same dataset form a tight cluster in the weight space and that models fine-tuned on different datasets from the same underlying task form a looser cluster. Moreover, traversing around the region between the models reaches new models that perform comparably or even better than models found via fine-tuning, even on tasks that the original models were not fine-tuned on. Our findings provide insight into the relationships between models, demonstrating that a model positioned between two similar models can acquire the knowledge of both. We leverage this finding and design a method to pick a better model for efficient fine-tuning. Specifically, we show that starting from the center of the region is as good or better than the pre-trained model in 11 of 12 datasets and improves accuracy by 3.06 on average.
SimpleStyle: An Adaptable Style Transfer Approach
Dec 22, 2022Attribute-controlled text rewriting, also known as text style-transfer, has a crucial role in regulating attributes and biases of textual training data and a machine generated text. In this work we present SimpleStyle, a minimalist yet effective approach for style-transfer composed of two simple ingredients: controlled denoising and output filtering. Despite the simplicity of our approach, which can be succinctly described with a few lines of code, it is competitive with previous state-of-the-art methods both in automatic and in human evaluation. To demonstrate the adaptability and practical value of our system beyond academic data, we apply SimpleStyle to transfer a wide range of text attributes appearing in real-world textual data from social networks. Additionally, we introduce a novel "soft noising" technique that further improves the performance of our system. We also show that teaching a student model to generate the output of SimpleStyle can result in a system that performs style transfer of equivalent quality with only a single greedy-decoded sample. Finally, we suggest our method as a remedy for the fundamental incompatible baseline issue that holds progress in the field. We offer our protocol as a simple yet strong baseline for works that wish to make incremental advancements in the field of attribute controlled text rewriting.
ColD Fusion: Collaborative Descent for Distributed Multitask Finetuning
Dec 02, 2022Pretraining has been shown to scale well with compute, data size and data diversity. Multitask learning trains on a mixture of supervised datasets and produces improved performance compared to self-supervised pretraining. Until now, massively multitask learning required simultaneous access to all datasets in the mixture and heavy compute resources that are only available to well-resourced teams. In this paper, we propose ColD Fusion, a method that provides the benefits of multitask learning but leverages distributed computation and requires limited communication and no sharing of data. Consequentially, ColD Fusion can create a synergistic loop, where finetuned models can be recycled to continually improve the pretrained model they are based on. We show that ColD Fusion yields comparable benefits to multitask pretraining by producing a model that (a) attains strong performance on all of the datasets it was multitask trained on and (b) is a better starting point for finetuning on unseen datasets. We find ColD Fusion outperforms RoBERTa and even previous multitask models. Specifically, when training and testing on 35 diverse datasets, ColD Fusion-based model outperforms RoBERTa by 2.45 points in average without any changes to the architecture.
Where to start? Analyzing the potential value of intermediate models
Nov 10, 2022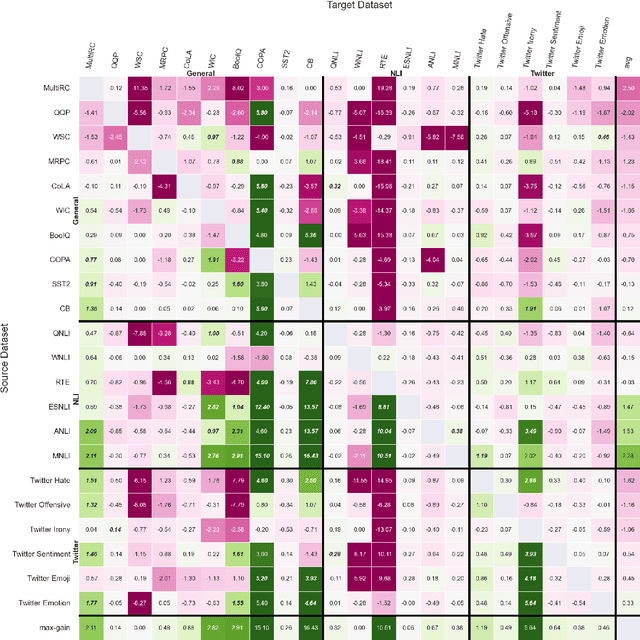



Previous studies observed that finetuned models may be better base models than the vanilla pretrained model. Such a model, finetuned on some source dataset, may provide a better starting point for a new finetuning process on a desired target dataset. Here, we perform a systematic analysis of this intertraining scheme, over a wide range of English classification tasks. Surprisingly, our analysis suggests that the potential intertraining gain can be analyzed independently for the target dataset under consideration, and for a base model being considered as a starting point. This is in contrast to current perception that the alignment between the target dataset and the source dataset used to generate the base model is a major factor in determining intertraining success. We analyze different aspects that contribute to each. Furthermore, we leverage our analysis to propose a practical and efficient approach to determine if and how to select a base model in real-world settings. Last, we release an updating ranking of best models in the HuggingFace hub per architecture https://ibm.github.io/model-recycling/.