 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKnowledge is a Region in Weight Space for Fine-tuned Language Models
Paper and Code
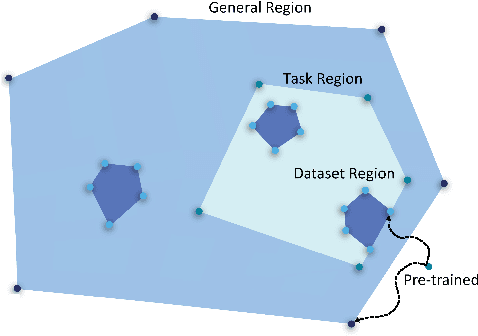

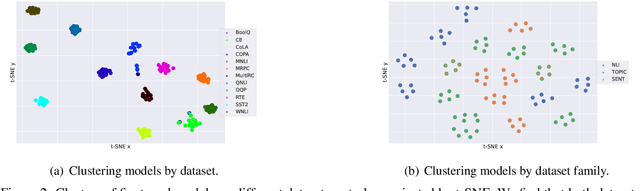

Research on neural networks has largely focused on understanding a single model trained on a single dataset. However, relatively little is known about the relationships between different models, especially those trained or tested on different datasets. We address this by studying how the weight space and underlying loss landscape of different models are interconnected. Specifically, we demonstrate that fine-tuned models that were optimized for high performance, reside in well-defined regions in weight space, and vice versa -- that any model that resides anywhere in those regions also has high performance. Specifically, we show that language models that have been fine-tuned on the same dataset form a tight cluster in the weight space and that models fine-tuned on different datasets from the same underlying task form a looser cluster. Moreover, traversing around the region between the models reaches new models that perform comparably or even better than models found via fine-tuning, even on tasks that the original models were not fine-tuned on. Our findings provide insight into the relationships between models, demonstrating that a model positioned between two similar models can acquire the knowledge of both. We leverage this finding and design a method to pick a better model for efficient fine-tuning. Specifically, we show that starting from the center of the region is as good or better than the pre-trained model in 11 of 12 datasets and improves accuracy by 3.06 on average.