 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRefVNLI: Towards Scalable Evaluation of Subject-driven Text-to-image Generation
Apr 24, 2025Subject-driven text-to-image (T2I) generation aims to produce images that align with a given textual description, while preserving the visual identity from a referenced subject image. Despite its broad downstream applicability -- ranging from enhanced personalization in image generation to consistent character representation in video rendering -- progress in this field is limited by the lack of reliable automatic evaluation. Existing methods either assess only one aspect of the task (i.e., textual alignment or subject preservation), misalign with human judgments, or rely on costly API-based evaluation. To address this, we introduce RefVNLI, a cost-effective metric that evaluates both textual alignment and subject preservation in a single prediction. Trained on a large-scale dataset derived from video-reasoning benchmarks and image perturbations, RefVNLI outperforms or matches existing baselines across multiple benchmarks and subject categories (e.g., \emph{Animal}, \emph{Object}), achieving up to 6.4-point gains in textual alignment and 8.5-point gains in subject consistency. It also excels with lesser-known concepts, aligning with human preferences at over 87\% accuracy.
Can LLMs Learn Macroeconomic Narratives from Social Media?
Jun 17, 2024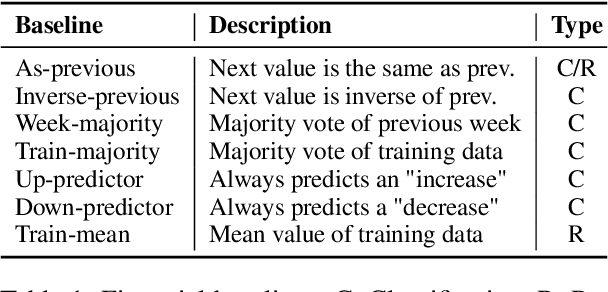


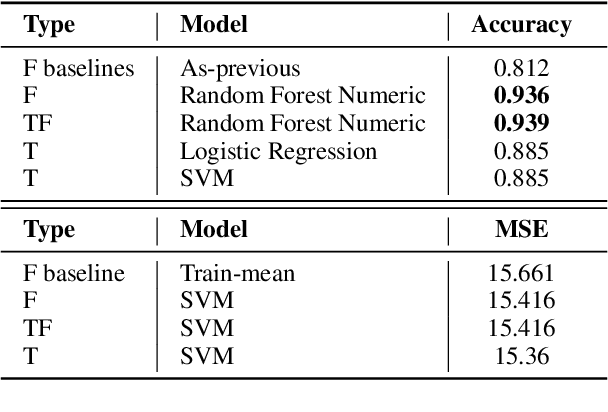
This study empirically tests the $\textit{Narrative Economics}$ hypothesis, which posits that narratives (ideas that are spread virally and affect public beliefs) can influence economic fluctuations. We introduce two curated datasets containing posts from X (formerly Twitter) which capture economy-related narratives (Data will be shared upon paper acceptance). Employing Natural Language Processing (NLP) methods, we extract and summarize narratives from the tweets. We test their predictive power for $\textit{macroeconomic}$ forecasting by incorporating the tweets' or the extracted narratives' representations in downstream financial prediction tasks. Our work highlights the challenges in improving macroeconomic models with narrative data, paving the way for the research community to realistically address this important challenge. From a scientific perspective, our investigation offers valuable insights and NLP tools for narrative extraction and summarization using Large Language Models (LLMs), contributing to future research on the role of narratives in economics.
LLMs Accelerate Annotation for Medical Information Extraction
Dec 04, 2023



The unstructured nature of clinical notes within electronic health records often conceals vital patient-related information, making it challenging to access or interpret. To uncover this hidden information, specialized Natural Language Processing (NLP) models are required. However, training these models necessitates large amounts of labeled data, a process that is both time-consuming and costly when relying solely on human experts for annotation. In this paper, we propose an approach that combines Large Language Models (LLMs) with human expertise to create an efficient method for generating ground truth labels for medical text annotation. By utilizing LLMs in conjunction with human annotators, we significantly reduce the human annotation burden, enabling the rapid creation of labeled datasets. We rigorously evaluate our method on a medical information extraction task, demonstrating that our approach not only substantially cuts down on human intervention but also maintains high accuracy. The results highlight the potential of using LLMs to improve the utilization of unstructured clinical data, allowing for the swift deployment of tailored NLP solutions in healthcare.
Knowledge is a Region in Weight Space for Fine-tuned Language Models
Feb 12, 2023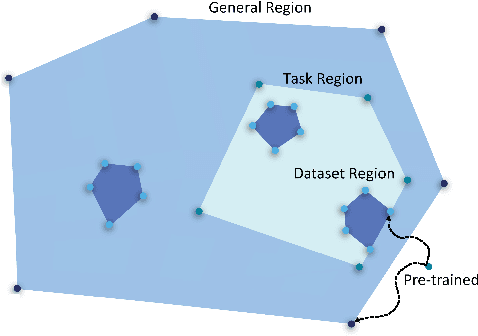

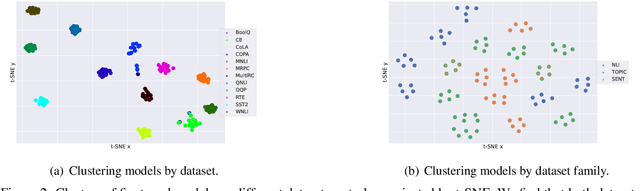

Research on neural networks has largely focused on understanding a single model trained on a single dataset. However, relatively little is known about the relationships between different models, especially those trained or tested on different datasets. We address this by studying how the weight space and underlying loss landscape of different models are interconnected. Specifically, we demonstrate that fine-tuned models that were optimized for high performance, reside in well-defined regions in weight space, and vice versa -- that any model that resides anywhere in those regions also has high performance. Specifically, we show that language models that have been fine-tuned on the same dataset form a tight cluster in the weight space and that models fine-tuned on different datasets from the same underlying task form a looser cluster. Moreover, traversing around the region between the models reaches new models that perform comparably or even better than models found via fine-tuning, even on tasks that the original models were not fine-tuned on. Our findings provide insight into the relationships between models, demonstrating that a model positioned between two similar models can acquire the knowledge of both. We leverage this finding and design a method to pick a better model for efficient fine-tuning. Specifically, we show that starting from the center of the region is as good or better than the pre-trained model in 11 of 12 datasets and improves accuracy by 3.06 on average.