 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe FACTS Leaderboard: A Comprehensive Benchmark for Large Language Model Factuality
Dec 11, 2025We introduce The FACTS Leaderboard, an online leaderboard suite and associated set of benchmarks that comprehensively evaluates the ability of language models to generate factually accurate text across diverse scenarios. The suite provides a holistic measure of factuality by aggregating the performance of models on four distinct sub-leaderboards: (1) FACTS Multimodal, which measures the factuality of responses to image-based questions; (2) FACTS Parametric, which assesses models' world knowledge by answering closed-book factoid questions from internal parameters; (3) FACTS Search, which evaluates factuality in information-seeking scenarios, where the model must use a search API; and (4) FACTS Grounding (v2), which evaluates whether long-form responses are grounded in provided documents, featuring significantly improved judge models. Each sub-leaderboard employs automated judge models to score model responses, and the final suite score is an average of the four components, designed to provide a robust and balanced assessment of a model's overall factuality. The FACTS Leaderboard Suite will be actively maintained, containing both public and private splits to allow for external participation while guarding its integrity. It can be found at https://www.kaggle.com/benchmarks/google/facts .
RefVNLI: Towards Scalable Evaluation of Subject-driven Text-to-image Generation
Apr 24, 2025Subject-driven text-to-image (T2I) generation aims to produce images that align with a given textual description, while preserving the visual identity from a referenced subject image. Despite its broad downstream applicability -- ranging from enhanced personalization in image generation to consistent character representation in video rendering -- progress in this field is limited by the lack of reliable automatic evaluation. Existing methods either assess only one aspect of the task (i.e., textual alignment or subject preservation), misalign with human judgments, or rely on costly API-based evaluation. To address this, we introduce RefVNLI, a cost-effective metric that evaluates both textual alignment and subject preservation in a single prediction. Trained on a large-scale dataset derived from video-reasoning benchmarks and image perturbations, RefVNLI outperforms or matches existing baselines across multiple benchmarks and subject categories (e.g., \emph{Animal}, \emph{Object}), achieving up to 6.4-point gains in textual alignment and 8.5-point gains in subject consistency. It also excels with lesser-known concepts, aligning with human preferences at over 87\% accuracy.
LLMs Accelerate Annotation for Medical Information Extraction
Dec 04, 2023



The unstructured nature of clinical notes within electronic health records often conceals vital patient-related information, making it challenging to access or interpret. To uncover this hidden information, specialized Natural Language Processing (NLP) models are required. However, training these models necessitates large amounts of labeled data, a process that is both time-consuming and costly when relying solely on human experts for annotation. In this paper, we propose an approach that combines Large Language Models (LLMs) with human expertise to create an efficient method for generating ground truth labels for medical text annotation. By utilizing LLMs in conjunction with human annotators, we significantly reduce the human annotation burden, enabling the rapid creation of labeled datasets. We rigorously evaluate our method on a medical information extraction task, demonstrating that our approach not only substantially cuts down on human intervention but also maintains high accuracy. The results highlight the potential of using LLMs to improve the utilization of unstructured clinical data, allowing for the swift deployment of tailored NLP solutions in healthcare.
Surfacing Biases in Large Language Models using Contrastive Input Decoding
May 12, 2023



Ensuring that large language models (LMs) are fair, robust and useful requires an understanding of how different modifications to their inputs impact the model's behaviour. In the context of open-text generation tasks, however, such an evaluation is not trivial. For example, when introducing a model with an input text and a perturbed, "contrastive" version of it, meaningful differences in the next-token predictions may not be revealed with standard decoding strategies. With this motivation in mind, we propose Contrastive Input Decoding (CID): a decoding algorithm to generate text given two inputs, where the generated text is likely given one input but unlikely given the other. In this way, the contrastive generations can highlight potentially subtle differences in how the LM output differs for the two inputs in a simple and interpretable manner. We use CID to highlight context-specific biases that are hard to detect with standard decoding strategies and quantify the effect of different input perturbations.
Useful Confidence Measures: Beyond the Max Score
Oct 25, 2022



An important component in deploying machine learning (ML) in safety-critic applications is having a reliable measure of confidence in the ML model's predictions. For a classifier $f$ producing a probability vector $f(x)$ over the candidate classes, the confidence is typically taken to be $\max_i f(x)_i$. This approach is potentially limited, as it disregards the rest of the probability vector. In this work, we derive several confidence measures that depend on information beyond the maximum score, such as margin-based and entropy-based measures, and empirically evaluate their usefulness, focusing on NLP tasks with distribution shifts and Transformer-based models. We show that when models are evaluated on the out-of-distribution data ``out of the box'', using only the maximum score to inform the confidence measure is highly suboptimal. In the post-processing regime (where the scores of $f$ can be improved using additional in-distribution held-out data), this remains true, albeit less significant. Overall, our results suggest that entropy-based confidence is a surprisingly useful measure.
Audio De-identification: A New Entity Recognition Task
Mar 17, 2019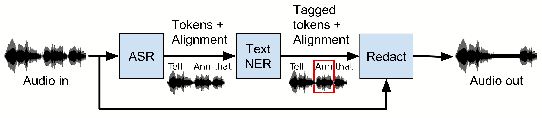
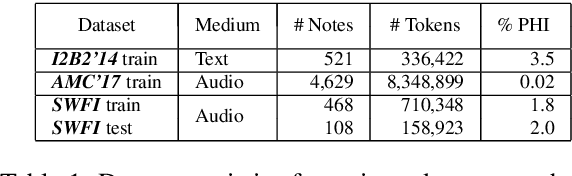
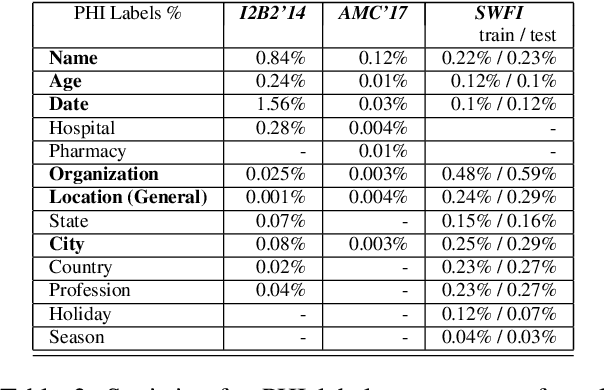
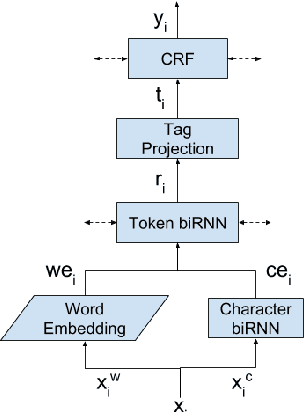
Named Entity Recognition (NER) has been mostly studied in the context of written text. Specifically, NER is an important step in de-identification (de-ID) of medical records, many of which are recorded conversations between a patient and a doctor. In such recordings, audio spans with personal information should be redacted, similar to the redaction of sensitive character spans in de-ID for written text. The application of NER in the context of audio de-identification has yet to be fully investigated. To this end, we define the task of audio de-ID, in which audio spans with entity mentions should be detected. We then present our pipeline for this task, which involves Automatic Speech Recognition (ASR), NER on the transcript text, and text-to-audio alignment. Finally, we introduce a novel metric for audio de-ID and a new evaluation benchmark consisting of a large labeled segment of the Switchboard and Fisher audio datasets and detail our pipeline's results on it.