 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeComplexity-Balanced Diffusion Splitting
Jun 04, 2026Standard continuous-time generative models rely on monolithic architectures that must navigate vastly different signal regimes, from isotropic noise to intricate data distributions. While scaling model capacity improves performance, deploying a massive network uniformly across the entire generative timeline is inherently inefficient. In this work, we propose Complexity-Balanced Splitting (CBS), a principled framework for temporal capacity allocation that distributes the generative workload across multiple specialized sub-networks. Grounded in function approximation theory and de Boor's equidistribution principle, CBS partitions the diffusion timeline into segments of equal approximation burden, allocating more representational capacity to regions where the generative dynamics are more difficult to model. To estimate this local complexity, we introduce two complementary and tractable monitor functions: a spatial measure based on the flow's Dirichlet energy, and a geometric measure based on the acceleration of the sampling trajectories. Using a lightweight auxiliary model to estimate these complexity profiles, our approach eliminates the need for heuristic temporal splits or computationally expensive search procedures. Extensive evaluation across multiple architectures (SiT, JiT, and UNet) and datasets demonstrates that CBS consistently improves synthesis quality without increasing per-step inference cost. In particular, CBS improves FID by ~35% on SiT-XL with CFG relative to naive temporal partitioning. Project page is available at https://noamissachar.github.io/CBS/.
LiveSVG: Zero-Shot SVG Animation via Video Generation
May 28, 2026We introduce LiveSVG, a zero-shot approach for generating Scalable Vector Graphics (SVG) animations using video diffusion models. Current SVG animation methods struggle with complex motions: LLM-based code synthesis fails to express fine, non-rigid Bézier deformations, while Score Distillation Sampling (SDS) provides noisy gradients and often requires category-specific priors like skeletons. In contrast, LiveSVG fits vector geometry directly to an explicitly generated target video. Given an input SVG image and a motion prompt, we generate a previewable target video using a frozen image-to-video model, then fit the original SVG to this video via differentiable rendering. Our fitting stage is skeleton-free, utilizing a dual-level motion representation that combines per-group homographies for coarse articulation with per-path Bézier control-point offsets for local deformations. To resolve color-induced correspondence ambiguities during pixel-wise fitting, we introduce a novel sphere-packing recolorization strategy. We also present ChallengeSVG, a benchmark of complex, multi-object scenes that exposes the limitations of prior work. Evaluations demonstrate that LiveSVG significantly outperforms existing methods on both AniClipart and ChallengeSVG, establishing direct reference-video fitting as a practical, robust route to prompt-aligned and fully editable vector animation.
Retrieval-Augmented Gaussian Avatars: Improving Expression Generalization
Mar 09, 2026Template-free animatable head avatars can achieve high visual fidelity by learning expression-dependent facial deformation directly from a subject's capture, avoiding parametric face templates and hand-designed blendshape spaces. However, since learned deformation is supervised only by the expressions observed for a single identity, these models suffer from limited expression coverage and often struggle when driven by motions that deviate from the training distribution. We introduce RAF (Retrieval-Augmented Faces), a simple training-time augmentation designed for template-free head avatars that learn deformation from data. RAF constructs a large unlabeled expression bank and, during training, replaces a subset of the subject's expression features with nearest-neighbor expressions retrieved from this bank while still reconstructing the subject's original frames. This exposes the deformation field to a broader range of expression conditions, encouraging stronger identity-expression decoupling and improving robustness to expression distribution shift without requiring paired cross-identity data, additional annotations, or architectural changes. We further analyze how retrieval augmentation increases expression diversity and validate retrieval quality with a user study showing that retrieved neighbors are perceptually closer in expression and pose. Experiments on the NeRSemble benchmark demonstrate that RAF consistently improves expression fidelity over the baseline, in both self-driving and cross-driving scenarios.
Cycle-Consistent Tuning for Layered Image Decomposition
Feb 24, 2026Disentangling visual layers in real-world images is a persistent challenge in vision and graphics, as such layers often involve non-linear and globally coupled interactions, including shading, reflection, and perspective distortion. In this work, we present an in-context image decomposition framework that leverages large diffusion foundation models for layered separation. We focus on the challenging case of logo-object decomposition, where the goal is to disentangle a logo from the surface on which it appears while faithfully preserving both layers. Our method fine-tunes a pretrained diffusion model via lightweight LoRA adaptation and introduces a cycle-consistent tuning strategy that jointly trains decomposition and composition models, enforcing reconstruction consistency between decomposed and recomposed images. This bidirectional supervision substantially enhances robustness in cases where the layers exhibit complex interactions. Furthermore, we introduce a progressive self-improving process, which iteratively augments the training set with high-quality model-generated examples to refine performance. Extensive experiments demonstrate that our approach achieves accurate and coherent decompositions and also generalizes effectively across other decomposition types, suggesting its potential as a unified framework for layered image decomposition.
DyPE: Dynamic Position Extrapolation for Ultra High Resolution Diffusion
Oct 23, 2025Diffusion Transformer models can generate images with remarkable fidelity and detail, yet training them at ultra-high resolutions remains extremely costly due to the self-attention mechanism's quadratic scaling with the number of image tokens. In this paper, we introduce Dynamic Position Extrapolation (DyPE), a novel, training-free method that enables pre-trained diffusion transformers to synthesize images at resolutions far beyond their training data, with no additional sampling cost. DyPE takes advantage of the spectral progression inherent to the diffusion process, where low-frequency structures converge early, while high-frequencies take more steps to resolve. Specifically, DyPE dynamically adjusts the model's positional encoding at each diffusion step, matching their frequency spectrum with the current stage of the generative process. This approach allows us to generate images at resolutions that exceed the training resolution dramatically, e.g., 16 million pixels using FLUX. On multiple benchmarks, DyPE consistently improves performance and achieves state-of-the-art fidelity in ultra-high-resolution image generation, with gains becoming even more pronounced at higher resolutions. Project page is available at https://noamissachar.github.io/DyPE/.
Story2Board: A Training-Free Approach for Expressive Storyboard Generation
Aug 13, 2025We present Story2Board, a training-free framework for expressive storyboard generation from natural language. Existing methods narrowly focus on subject identity, overlooking key aspects of visual storytelling such as spatial composition, background evolution, and narrative pacing. To address this, we introduce a lightweight consistency framework composed of two components: Latent Panel Anchoring, which preserves a shared character reference across panels, and Reciprocal Attention Value Mixing, which softly blends visual features between token pairs with strong reciprocal attention. Together, these mechanisms enhance coherence without architectural changes or fine-tuning, enabling state-of-the-art diffusion models to generate visually diverse yet consistent storyboards. To structure generation, we use an off-the-shelf language model to convert free-form stories into grounded panel-level prompts. To evaluate, we propose the Rich Storyboard Benchmark, a suite of open-domain narratives designed to assess layout diversity and background-grounded storytelling, in addition to consistency. We also introduce a new Scene Diversity metric that quantifies spatial and pose variation across storyboards. Our qualitative and quantitative results, as well as a user study, show that Story2Board produces more dynamic, coherent, and narratively engaging storyboards than existing baselines.
EditInspector: A Benchmark for Evaluation of Text-Guided Image Edits
Jun 11, 2025Text-guided image editing, fueled by recent advancements in generative AI, is becoming increasingly widespread. This trend highlights the need for a comprehensive framework to verify text-guided edits and assess their quality. To address this need, we introduce EditInspector, a novel benchmark for evaluation of text-guided image edits, based on human annotations collected using an extensive template for edit verification. We leverage EditInspector to evaluate the performance of state-of-the-art (SoTA) vision and language models in assessing edits across various dimensions, including accuracy, artifact detection, visual quality, seamless integration with the image scene, adherence to common sense, and the ability to describe edit-induced changes. Our findings indicate that current models struggle to evaluate edits comprehensively and frequently hallucinate when describing the changes. To address these challenges, we propose two novel methods that outperform SoTA models in both artifact detection and difference caption generation.
RefVNLI: Towards Scalable Evaluation of Subject-driven Text-to-image Generation
Apr 24, 2025Subject-driven text-to-image (T2I) generation aims to produce images that align with a given textual description, while preserving the visual identity from a referenced subject image. Despite its broad downstream applicability -- ranging from enhanced personalization in image generation to consistent character representation in video rendering -- progress in this field is limited by the lack of reliable automatic evaluation. Existing methods either assess only one aspect of the task (i.e., textual alignment or subject preservation), misalign with human judgments, or rely on costly API-based evaluation. To address this, we introduce RefVNLI, a cost-effective metric that evaluates both textual alignment and subject preservation in a single prediction. Trained on a large-scale dataset derived from video-reasoning benchmarks and image perturbations, RefVNLI outperforms or matches existing baselines across multiple benchmarks and subject categories (e.g., \emph{Animal}, \emph{Object}), achieving up to 6.4-point gains in textual alignment and 8.5-point gains in subject consistency. It also excels with lesser-known concepts, aligning with human preferences at over 87\% accuracy.
Task-Specific Adaptation with Restricted Model Access
Feb 02, 2025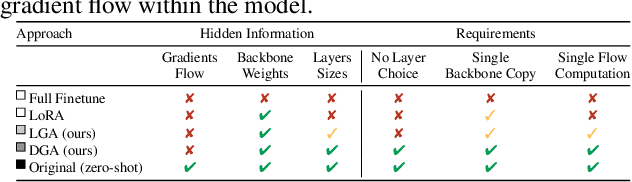
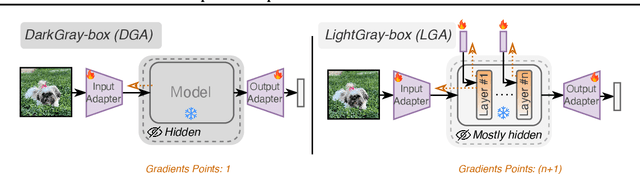
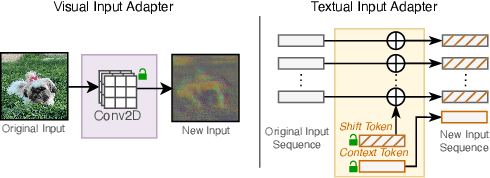
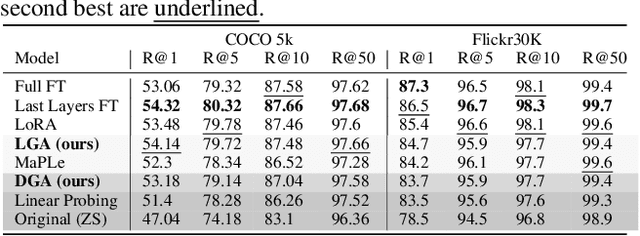
The emergence of foundational models has greatly improved performance across various downstream tasks, with fine-tuning often yielding even better results. However, existing fine-tuning approaches typically require access to model weights and layers, leading to challenges such as managing multiple model copies or inference pipelines, inefficiencies in edge device optimization, and concerns over proprietary rights, privacy, and exposure to unsafe model variants. In this paper, we address these challenges by exploring "Gray-box" fine-tuning approaches, where the model's architecture and weights remain hidden, allowing only gradient propagation. We introduce a novel yet simple and effective framework that adapts to new tasks using two lightweight learnable modules at the model's input and output. Additionally, we present a less restrictive variant that offers more entry points into the model, balancing performance with model exposure. We evaluate our approaches across several backbones on benchmarks such as text-image alignment, text-video alignment, and sketch-image alignment. Results show that our Gray-box approaches are competitive with full-access fine-tuning methods, despite having limited access to the model.
Stable Flow: Vital Layers for Training-Free Image Editing
Nov 21, 2024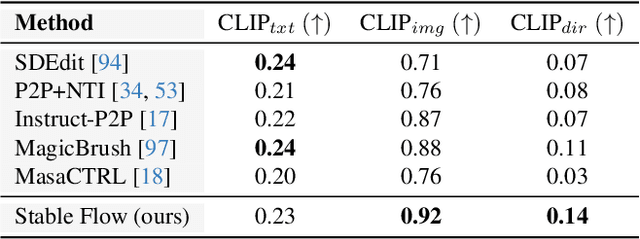

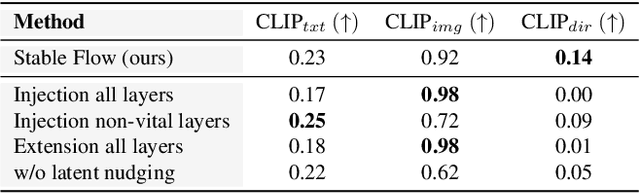
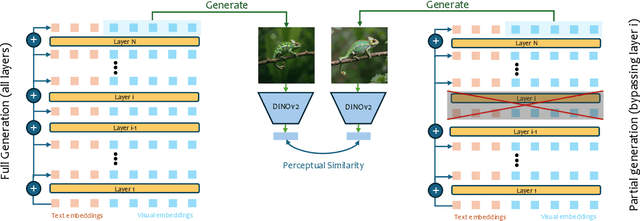
Diffusion models have revolutionized the field of content synthesis and editing. Recent models have replaced the traditional UNet architecture with the Diffusion Transformer (DiT), and employed flow-matching for improved training and sampling. However, they exhibit limited generation diversity. In this work, we leverage this limitation to perform consistent image edits via selective injection of attention features. The main challenge is that, unlike the UNet-based models, DiT lacks a coarse-to-fine synthesis structure, making it unclear in which layers to perform the injection. Therefore, we propose an automatic method to identify "vital layers" within DiT, crucial for image formation, and demonstrate how these layers facilitate a range of controlled stable edits, from non-rigid modifications to object addition, using the same mechanism. Next, to enable real-image editing, we introduce an improved image inversion method for flow models. Finally, we evaluate our approach through qualitative and quantitative comparisons, along with a user study, and demonstrate its effectiveness across multiple applications. The project page is available at https://omriavrahami.com/stable-flow