 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVidMsg: A Benchmark for Implicit Message Inference in Short Videos
Jun 02, 2026Understanding short online videos involves more than identifying visible objects and actions; video makers often include an underlying message or purpose in the clip. We introduce VidMsg, a benchmark for evaluating implicit message understanding in short, internet-native video clips. VidMsg contains 400 YouTube-derived clips across 9 practical topic areas and 52 fine-grained target messages, covering domains such as career and finance, education, health and well-being, culture, safety, sustainability, and lifestyle. VidMsg is constructed through a message-first pipeline: an LLM first translates target messages into indirect search scenarios, which are used to retrieve candidate clips. Human annotators then retain clips that convey the intended message without being overly explicit. VidMsg is designed primarily for bidirectional message-clip retrieval for scalable applications such as video search and recommendation, where systems must capture holistic video understanding. In addition to retrieval, VidMsg includes a diagnostic multiple-choice QA benchmark, where models select the intended message of a clip from semantically related alternatives. Experiments with contemporary video-language and retrieval models show that strong models often fail on VidMsg, because the task requires pragmatic inference, integration of contextual cues, and discrimination among semantically close messages. We also introduce VidVec-Msg, a baseline method that improves message-oriented retrieval while leaving substantial headroom for future work.
Retrieval-Augmented Gaussian Avatars: Improving Expression Generalization
Mar 09, 2026Template-free animatable head avatars can achieve high visual fidelity by learning expression-dependent facial deformation directly from a subject's capture, avoiding parametric face templates and hand-designed blendshape spaces. However, since learned deformation is supervised only by the expressions observed for a single identity, these models suffer from limited expression coverage and often struggle when driven by motions that deviate from the training distribution. We introduce RAF (Retrieval-Augmented Faces), a simple training-time augmentation designed for template-free head avatars that learn deformation from data. RAF constructs a large unlabeled expression bank and, during training, replaces a subset of the subject's expression features with nearest-neighbor expressions retrieved from this bank while still reconstructing the subject's original frames. This exposes the deformation field to a broader range of expression conditions, encouraging stronger identity-expression decoupling and improving robustness to expression distribution shift without requiring paired cross-identity data, additional annotations, or architectural changes. We further analyze how retrieval augmentation increases expression diversity and validate retrieval quality with a user study showing that retrieved neighbors are perceptually closer in expression and pose. Experiments on the NeRSemble benchmark demonstrate that RAF consistently improves expression fidelity over the baseline, in both self-driving and cross-driving scenarios.
VidVec: Unlocking Video MLLM Embeddings for Video-Text Retrieval
Feb 08, 2026Recent studies have adapted generative Multimodal Large Language Models (MLLMs) into embedding extractors for vision tasks, typically through fine-tuning to produce universal representations. However, their performance on video remains inferior to Video Foundation Models (VFMs). In this paper, we focus on leveraging MLLMs for video-text embedding and retrieval. We first conduct a systematic layer-wise analysis, showing that intermediate (pre-trained) MLLM layers already encode substantial task-relevant information. Leveraging this insight, we demonstrate that combining intermediate-layer embeddings with a calibrated MLLM head yields strong zero-shot retrieval performance without any training. Building on these findings, we introduce a lightweight text-based alignment strategy which maps dense video captions to short summaries and enables task-related video-text embedding learning without visual supervision. Remarkably, without any fine-tuning beyond text, our method outperforms current methods, often by a substantial margin, achieving state-of-the-art results across common video retrieval benchmarks.
Fast Autoregressive Video Diffusion and World Models with Temporal Cache Compression and Sparse Attention
Feb 02, 2026Autoregressive video diffusion models enable streaming generation, opening the door to long-form synthesis, video world models, and interactive neural game engines. However, their core attention layers become a major bottleneck at inference time: as generation progresses, the KV cache grows, causing both increasing latency and escalating GPU memory, which in turn restricts usable temporal context and harms long-range consistency. In this work, we study redundancy in autoregressive video diffusion and identify three persistent sources: near-duplicate cached keys across frames, slowly evolving (largely semantic) queries/keys that make many attention computations redundant, and cross-attention over long prompts where only a small subset of tokens matters per frame. Building on these observations, we propose a unified, training-free attention framework for autoregressive diffusion: TempCache compresses the KV cache via temporal correspondence to bound cache growth; AnnCA accelerates cross-attention by selecting frame-relevant prompt tokens using fast approximate nearest neighbor (ANN) matching; and AnnSA sparsifies self-attention by restricting each query to semantically matched keys, also using a lightweight ANN. Together, these modules reduce attention, compute, and memory and are compatible with existing autoregressive diffusion backbones and world models. Experiments demonstrate up to x5--x10 end-to-end speedups while preserving near-identical visual quality and, crucially, maintaining stable throughput and nearly constant peak GPU memory usage over long rollouts, where prior methods progressively slow down and suffer from increasing memory usage.
SSNAPS: Audio-Visual Separation of Speech and Background Noise with Diffusion Inverse Sampling
Feb 01, 2026This paper addresses the challenge of audio-visual single-microphone speech separation and enhancement in the presence of real-world environmental noise. Our approach is based on generative inverse sampling, where we model clean speech and ambient noise with dedicated diffusion priors and jointly leverage them to recover all underlying sources. To achieve this, we reformulate a recent inverse sampler to match our setting. We evaluate on mixtures of 1, 2, and 3 speakers with noise and show that, despite being entirely unsupervised, our method consistently outperforms leading supervised baselines in \ac{WER} across all conditions. We further extend our framework to handle off-screen speaker separation. Moreover, the high fidelity of the separated noise component makes it suitable for downstream acoustic scene detection. Demo page: https://ssnapsicml.github.io/ssnapsicml2026/
Find your Needle: Small Object Image Retrieval via Multi-Object Attention Optimization
Mar 10, 2025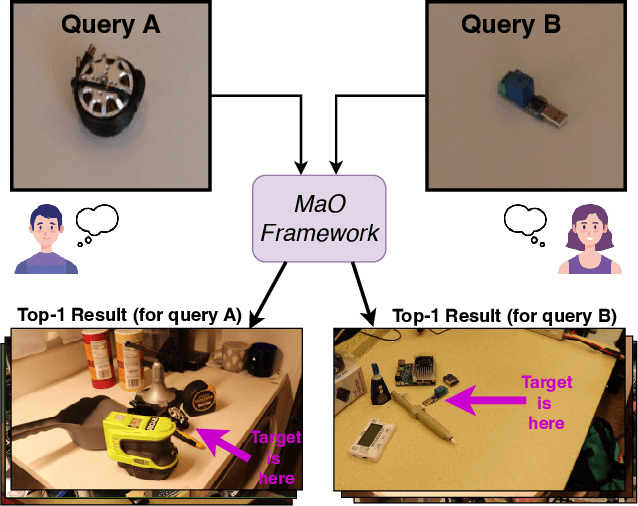
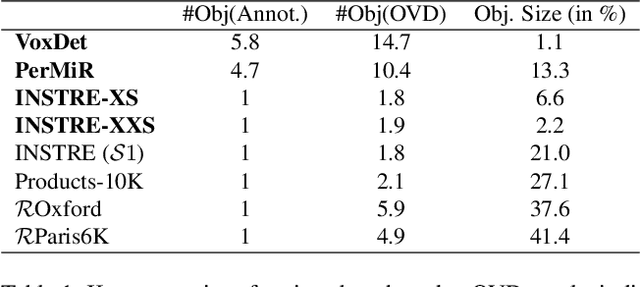
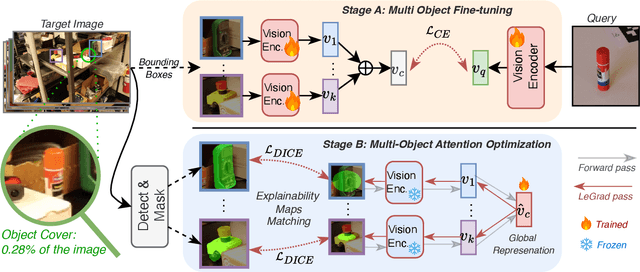
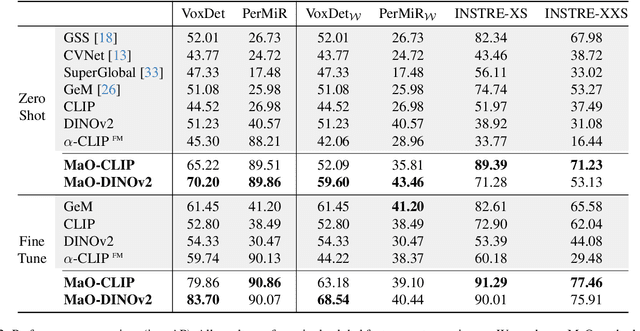
We address the challenge of Small Object Image Retrieval (SoIR), where the goal is to retrieve images containing a specific small object, in a cluttered scene. The key challenge in this setting is constructing a single image descriptor, for scalable and efficient search, that effectively represents all objects in the image. In this paper, we first analyze the limitations of existing methods on this challenging task and then introduce new benchmarks to support SoIR evaluation. Next, we introduce Multi-object Attention Optimization (MaO), a novel retrieval framework which incorporates a dedicated multi-object pre-training phase. This is followed by a refinement process that leverages attention-based feature extraction with object masks, integrating them into a single unified image descriptor. Our MaO approach significantly outperforms existing retrieval methods and strong baselines, achieving notable improvements in both zero-shot and lightweight multi-object fine-tuning. We hope this work will lay the groundwork and inspire further research to enhance retrieval performance for this highly practical task.
CarGait: Cross-Attention based Re-ranking for Gait recognition
Mar 05, 2025



Gait recognition is a computer vision task that identifies individuals based on their walking patterns. Gait recognition performance is commonly evaluated by ranking a gallery of candidates and measuring the accuracy at the top Rank-$K$. Existing models are typically single-staged, i.e. searching for the probe's nearest neighbors in a gallery using a single global feature representation. Although these models typically excel at retrieving the correct identity within the top-$K$ predictions, they struggle when hard negatives appear in the top short-list, leading to relatively low performance at the highest ranks (e.g., Rank-1). In this paper, we introduce CarGait, a Cross-Attention Re-ranking method for gait recognition, that involves re-ordering the top-$K$ list leveraging the fine-grained correlations between pairs of gait sequences through cross-attention between gait strips. This re-ranking scheme can be adapted to existing single-stage models to enhance their final results. We demonstrate the capabilities of CarGait by extensive experiments on three common gait datasets, Gait3D, GREW, and OU-MVLP, and seven different gait models, showing consistent improvements in Rank-1,5 accuracy, superior results over existing re-ranking methods, and strong baselines.
Task-Specific Adaptation with Restricted Model Access
Feb 02, 2025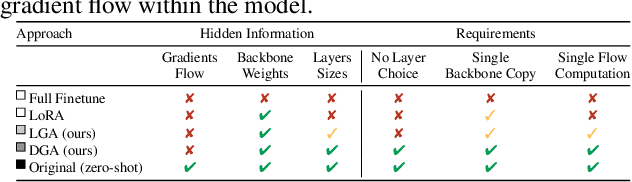
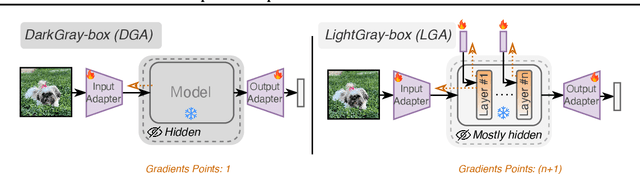
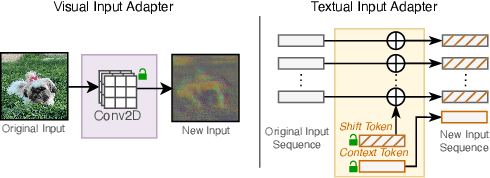
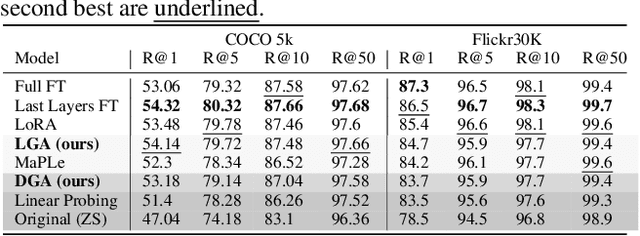
The emergence of foundational models has greatly improved performance across various downstream tasks, with fine-tuning often yielding even better results. However, existing fine-tuning approaches typically require access to model weights and layers, leading to challenges such as managing multiple model copies or inference pipelines, inefficiencies in edge device optimization, and concerns over proprietary rights, privacy, and exposure to unsafe model variants. In this paper, we address these challenges by exploring "Gray-box" fine-tuning approaches, where the model's architecture and weights remain hidden, allowing only gradient propagation. We introduce a novel yet simple and effective framework that adapts to new tasks using two lightweight learnable modules at the model's input and output. Additionally, we present a less restrictive variant that offers more entry points into the model, balancing performance with model exposure. We evaluate our approaches across several backbones on benchmarks such as text-image alignment, text-video alignment, and sketch-image alignment. Results show that our Gray-box approaches are competitive with full-access fine-tuning methods, despite having limited access to the model.
Active Learning via Classifier Impact and Greedy Selection for Interactive Image Retrieval
Dec 03, 2024
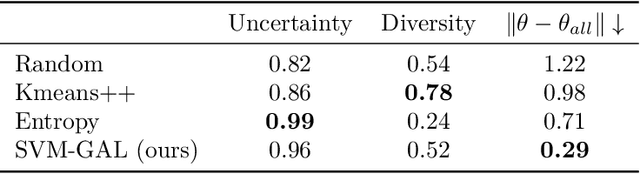
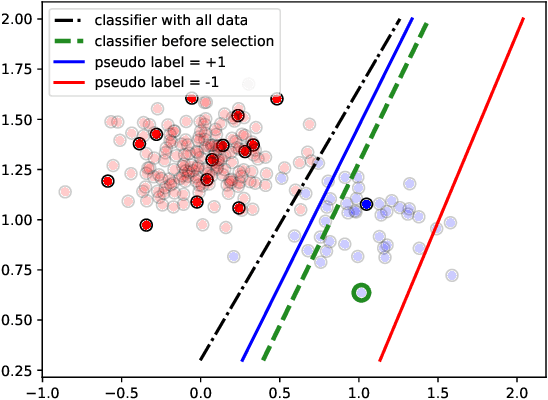

Active Learning (AL) is a user-interactive approach aimed at reducing annotation costs by selecting the most crucial examples to label. Although AL has been extensively studied for image classification tasks, the specific scenario of interactive image retrieval has received relatively little attention. This scenario presents unique characteristics, including an open-set and class-imbalanced binary classification, starting with very few labeled samples. We introduce a novel batch-mode Active Learning framework named GAL (Greedy Active Learning) that better copes with this application. It incorporates a new acquisition function for sample selection that measures the impact of each unlabeled sample on the classifier. We further embed this strategy in a greedy selection approach, better exploiting the samples within each batch. We evaluate our framework with both linear (SVM) and non-linear MLP/Gaussian Process classifiers. For the Gaussian Process case, we show a theoretical guarantee on the greedy approximation. Finally, we assess our performance for the interactive content-based image retrieval task on several benchmarks and demonstrate its superiority over existing approaches and common baselines. Code is available at https://github.com/barleah/GreedyAL.
Unveiling the Power of Diffusion Features For Personalized Segmentation and Retrieval
May 28, 2024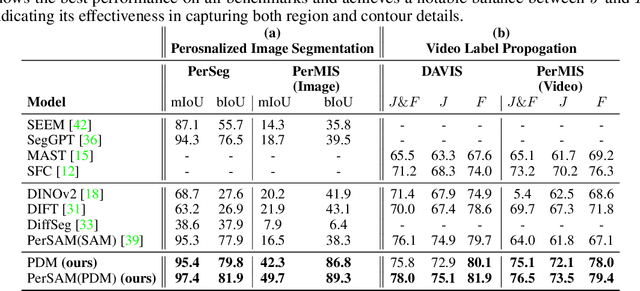

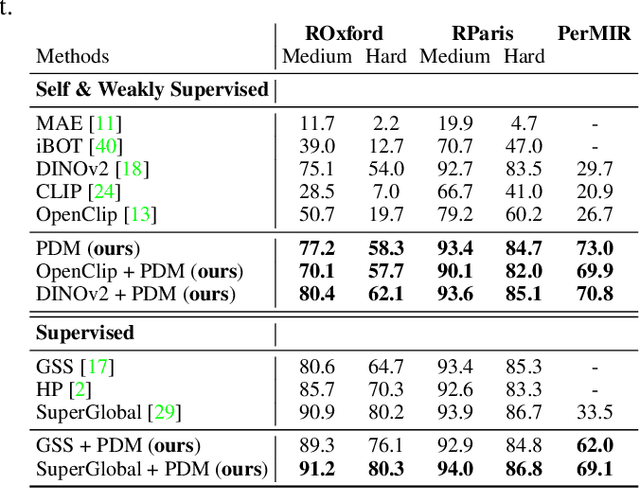
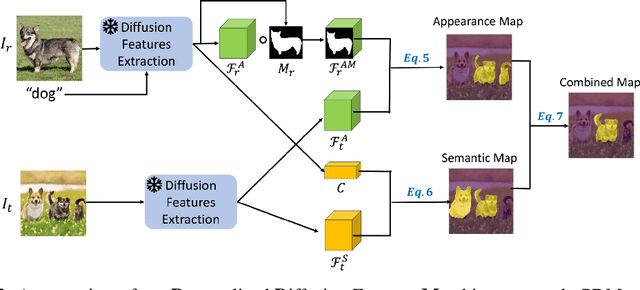
Personalized retrieval and segmentation aim to locate specific instances within a dataset based on an input image and a short description of the reference instance. While supervised methods are effective, they require extensive labeled data for training. Recently, self-supervised foundation models have been introduced to these tasks showing comparable results to supervised methods. However, a significant flaw in these models is evident: they struggle to locate a desired instance when other instances within the same class are presented. In this paper, we explore text-to-image diffusion models for these tasks. Specifically, we propose a novel approach called PDM for Personalized Features Diffusion Matching, that leverages intermediate features of pre-trained text-to-image models for personalization tasks without any additional training. PDM demonstrates superior performance on popular retrieval and segmentation benchmarks, outperforming even supervised methods. We also highlight notable shortcomings in current instance and segmentation datasets and propose new benchmarks for these tasks.