 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeActive Learning via Classifier Impact and Greedy Selection for Interactive Image Retrieval
Dec 03, 2024
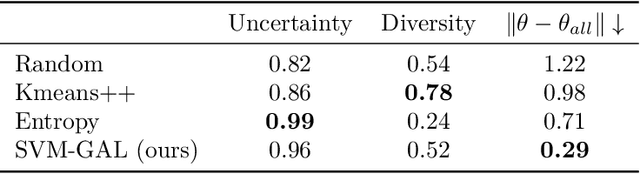
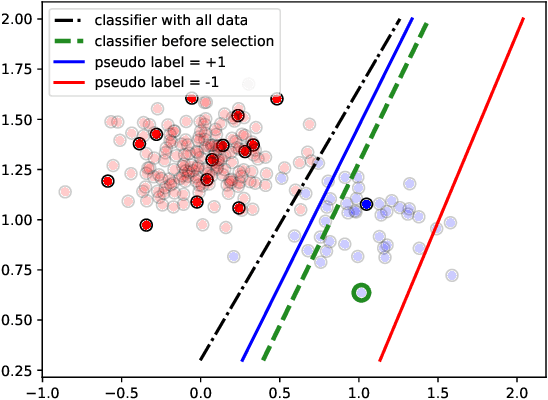

Active Learning (AL) is a user-interactive approach aimed at reducing annotation costs by selecting the most crucial examples to label. Although AL has been extensively studied for image classification tasks, the specific scenario of interactive image retrieval has received relatively little attention. This scenario presents unique characteristics, including an open-set and class-imbalanced binary classification, starting with very few labeled samples. We introduce a novel batch-mode Active Learning framework named GAL (Greedy Active Learning) that better copes with this application. It incorporates a new acquisition function for sample selection that measures the impact of each unlabeled sample on the classifier. We further embed this strategy in a greedy selection approach, better exploiting the samples within each batch. We evaluate our framework with both linear (SVM) and non-linear MLP/Gaussian Process classifiers. For the Gaussian Process case, we show a theoretical guarantee on the greedy approximation. Finally, we assess our performance for the interactive content-based image retrieval task on several benchmarks and demonstrate its superiority over existing approaches and common baselines. Code is available at https://github.com/barleah/GreedyAL.
EffoVPR: Effective Foundation Model Utilization for Visual Place Recognition
May 28, 2024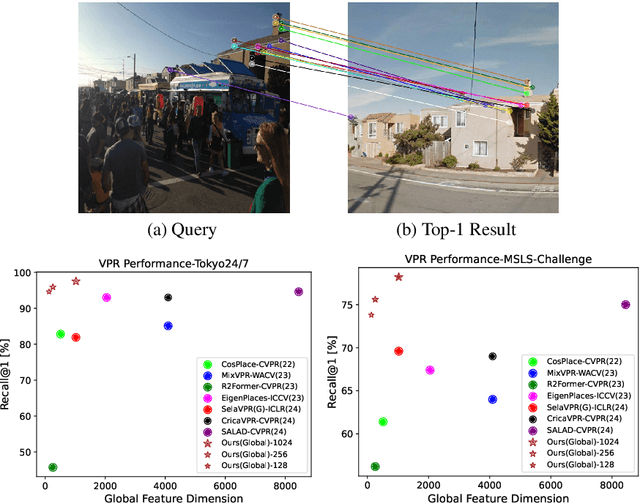
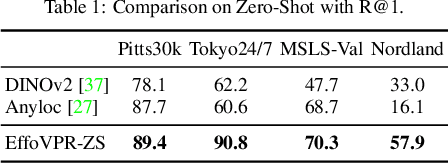
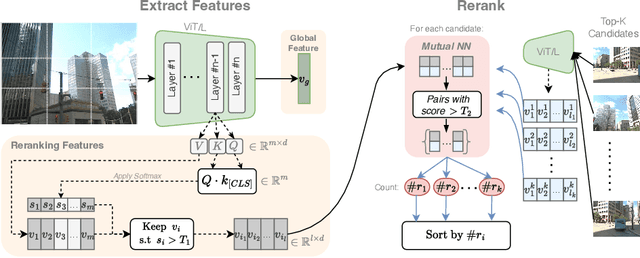
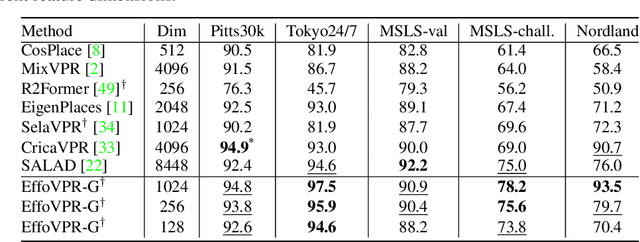
The task of Visual Place Recognition (VPR) is to predict the location of a query image from a database of geo-tagged images. Recent studies in VPR have highlighted the significant advantage of employing pre-trained foundation models like DINOv2 for the VPR task. However, these models are often deemed inadequate for VPR without further fine-tuning on task-specific data. In this paper, we propose a simple yet powerful approach to better exploit the potential of a foundation model for VPR. We first demonstrate that features extracted from self-attention layers can serve as a powerful re-ranker for VPR. Utilizing these features in a zero-shot manner, our method surpasses previous zero-shot methods and achieves competitive results compared to supervised methods across multiple datasets. Subsequently, we demonstrate that a single-stage method leveraging internal ViT layers for pooling can generate global features that achieve state-of-the-art results, even when reduced to a dimensionality as low as 128D. Nevertheless, incorporating our local foundation features for re-ranking, expands this gap. Our approach further demonstrates remarkable robustness and generalization, achieving state-of-the-art results, with a significant gap, in challenging scenarios, involving occlusion, day-night variations, and seasonal changes.
Advancing Image Retrieval with Few-Shot Learning and Relevance Feedback
Dec 18, 2023With such a massive growth in the number of images stored, efficient search in a database has become a crucial endeavor managed by image retrieval systems. Image Retrieval with Relevance Feedback (IRRF) involves iterative human interaction during the retrieval process, yielding more meaningful outcomes. This process can be generally cast as a binary classification problem with only {\it few} labeled samples derived from user feedback. The IRRF task frames a unique few-shot learning characteristics including binary classification of imbalanced and asymmetric classes, all in an open-set regime. In this paper, we study this task through the lens of few-shot learning methods. We propose a new scheme based on a hyper-network, that is tailored to the task and facilitates swift adjustment to user feedback. Our approach's efficacy is validated through comprehensive evaluations on multiple benchmarks and two supplementary tasks, supported by theoretical analysis. We demonstrate the advantage of our model over strong baselines on 4 different datasets in IRRF, addressing also retrieval of images with multiple objects. Furthermore, we show that our method can attain SoTA results in few-shot one-class classification and reach comparable results in binary classification task of few-shot open-set recognition.
Boosting the Performance of Semi-Supervised Learning with Unsupervised Clustering
Dec 01, 2020



Recently, Semi-Supervised Learning (SSL) has shown much promise in leveraging unlabeled data while being provided with very few labels. In this paper, we show that ignoring the labels altogether for whole epochs intermittently during training can significantly improve performance in the small sample regime. More specifically, we propose to train a network on two tasks jointly. The primary classification task is exposed to both the unlabeled and the scarcely annotated data, whereas the secondary task seeks to cluster the data without any labels. As opposed to hand-crafted pretext tasks frequently used in self-supervision, our clustering phase utilizes the same classification network and head in an attempt to relax the primary task and propagate the information from the labels without overfitting them. On top of that, the self-supervised technique of classifying image rotations is incorporated during the unsupervised learning phase to stabilize training. We demonstrate our method's efficacy in boosting several state-of-the-art SSL algorithms, significantly improving their results and reducing running time in various standard semi-supervised benchmarks, including 92.6% accuracy on CIFAR-10 and 96.9% on SVHN, using only 4 labels per class in each task. We also notably improve the results in the extreme cases of 1,2 and 3 labels per class, and show that features learned by our model are more meaningful for separating the data.
Transfer Learning of Photometric Phenotypes in Agriculture Using Metadata
Apr 01, 2020

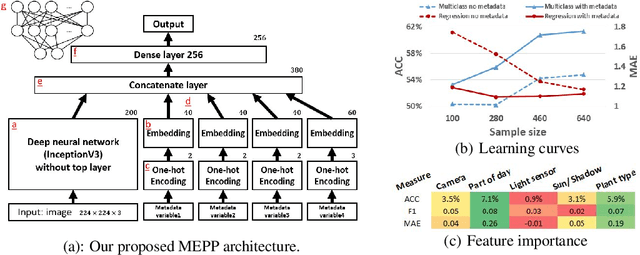
Estimation of photometric plant phenotypes (e.g., hue, shine, chroma) in field conditions is important for decisions on the expected yield quality, fruit ripeness, and need for further breeding. Estimating these from images is difficult due to large variances in lighting conditions, shadows, and sensor properties. We combine the image and metadata regarding capturing conditions embedded into a network, enabling more accurate estimation and transfer between different conditions. Compared to a state-of-the-art deep CNN and a human expert, metadata embedding improves the estimation of the tomato's hue and chroma.