 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVISTA: Validation-Informed Trajectory Adaptation via Self-Distillation
Apr 13, 2026Deep learning models may converge to suboptimal solutions despite strong validation accuracy, masking an optimization failure we term Trajectory Deviation. This is because as training proceeds, models can abandon high generalization states for specific data sub-populations, thus discarding previously learned latent features without triggering classical overfitting signals. To address this problem we introduce VISTA, an online self-distillation framework that enforces consistency along the optimization trajectory. Using a validation-informed Marginal Coverage score, VISTA identifies expert anchors, which are earlier model states that retain specialized competence over distinct data regions. A coverage-weighted ensemble of these anchors is integrated online during training, regularizing the loss landscape and preserving mastered knowledge. When evaluated across multiple benchmarks, VISTA demonstrates improved robustness and generalization over standard training and prior self-distillation methods, while a lightweight implementation reduces storage overhead by 90% without performance loss.
Leveraging Complementary Embeddings for Replay Selection in Continual Learning with Small Buffers
Apr 09, 2026Catastrophic forgetting remains a key challenge in Continual Learning (CL). In replay-based CL with severe memory constraints, performance critically depends on the sample selection strategy for the replay buffer. Most existing approaches construct memory buffers using embeddings learned under supervised objectives. However, class-agnostic, self-supervised representations often encode rich, class-relevant semantics that are overlooked. We propose a new method, Multiple Embedding Replay Selection, MERS, which replaces the buffer selection module with a graph-based approach that integrates both supervised and self-supervised embeddings. Empirical results show consistent improvements over SOTA selection strategies across a range of continual learning algorithms, with particularly strong gains in low-memory regimes. On CIFAR-100 and TinyImageNet, MERS outperforms single-embedding baselines without adding model parameters or increasing replay volume, making it a practical, drop-in enhancement for replay-based continual learning.
Active Learning with a Noisy Annotator
Apr 06, 2025Active Learning (AL) aims to reduce annotation costs by strategically selecting the most informative samples for labeling. However, most active learning methods struggle in the low-budget regime where only a few labeled examples are available. This issue becomes even more pronounced when annotators provide noisy labels. A common AL approach for the low- and mid-budget regimes focuses on maximizing the coverage of the labeled set across the entire dataset. We propose a novel framework called Noise-Aware Active Sampling (NAS) that extends existing greedy, coverage-based active learning strategies to handle noisy annotations. NAS identifies regions that remain uncovered due to the selection of noisy representatives and enables resampling from these areas. We introduce a simple yet effective noise filtering approach suitable for the low-budget regime, which leverages the inner mechanism of NAS and can be applied for noise filtering before model training. On multiple computer vision benchmarks, including CIFAR100 and ImageNet subsets, NAS significantly improves performance for standard active learning methods across different noise types and rates.
On Local Overfitting and Forgetting in Deep Neural Networks
Dec 17, 2024



The infrequent occurrence of overfitting in deep neural networks is perplexing: contrary to theoretical expectations, increasing model size often enhances performance in practice. But what if overfitting does occur, though restricted to specific sub-regions of the data space? In this work, we propose a novel score that captures the forgetting rate of deep models on validation data. We posit that this score quantifies local overfitting: a decline in performance confined to certain regions of the data space. We then show empirically that local overfitting occurs regardless of the presence of traditional overfitting. Using the framework of deep over-parametrized linear models, we offer a certain theoretical characterization of forgotten knowledge, and show that it correlates with knowledge forgotten by real deep models. Finally, we devise a new ensemble method that aims to recover forgotten knowledge, relying solely on the training history of a single network. When combined with self-distillation, this method enhances the performance of any trained model without adding inference costs. Extensive empirical evaluations demonstrate the efficacy of our method across multiple datasets, contemporary neural network architectures, and training protocols.
DCoM: Active Learning for All Learners
Jul 01, 2024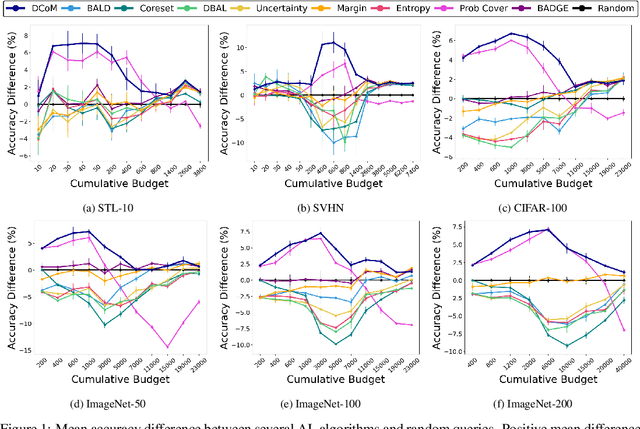



Deep Active Learning (AL) techniques can be effective in reducing annotation costs for training deep models. However, their effectiveness in low- and high-budget scenarios seems to require different strategies, and achieving optimal results across varying budget scenarios remains a challenge. In this study, we introduce Dynamic Coverage & Margin mix (DCoM), a novel active learning approach designed to bridge this gap. Unlike existing strategies, DCoM dynamically adjusts its strategy, considering the competence of the current model. Through theoretical analysis and empirical evaluations on diverse datasets, including challenging computer vision tasks, we demonstrate DCoM's ability to overcome the cold start problem and consistently improve results across different budgetary constraints. Thus DCoM achieves state-of-the-art performance in both low- and high-budget regimes.
TEAL: New Selection Strategy for Small Buffers in Experience Replay Class Incremental Learning
Jun 30, 2024



Continual Learning is an unresolved challenge, whose relevance increases when considering modern applications. Unlike the human brain, trained deep neural networks suffer from a phenomenon called Catastrophic Forgetting, where they progressively lose previously acquired knowledge upon learning new tasks. To mitigate this problem, numerous methods have been developed, many relying on replaying past exemplars during new task training. However, as the memory allocated for replay decreases, the effectiveness of these approaches diminishes. On the other hand, maintaining a large memory for the purpose of replay is inefficient and often impractical. Here we introduce TEAL, a novel approach to populate the memory with exemplars, that can be integrated with various experience-replay methods and significantly enhance their performance on small memory buffers. We show that TEAL improves the average accuracy of the SOTA method XDER as well as ER and ER-ACE on several image recognition benchmarks, with a small memory buffer of 1-3 exemplars per class in the final task. This confirms the hypothesis that when memory is scarce, it is best to prioritize the most typical data.
United We Stand: Using Epoch-wise Agreement of Ensembles to Combat Overfit
Oct 17, 2023



Deep neural networks have become the method of choice for solving many image classification tasks, largely because they can fit very complex functions defined over raw images. The downside of such powerful learners is the danger of overfitting the training set, leading to poor generalization, which is usually avoided by regularization and "early stopping" of the training. In this paper, we propose a new deep network ensemble classifier that is very effective against overfit. We begin with the theoretical analysis of a regression model, whose predictions - that the variance among classifiers increases when overfit occurs - is demonstrated empirically in deep networks in common use. Guided by these results, we construct a new ensemble-based prediction method designed to combat overfit, where the prediction is determined by the most consensual prediction throughout the training. On multiple image and text classification datasets, we show that when regular ensembles suffer from overfit, our method eliminates the harmful reduction in generalization due to overfit, and often even surpasses the performance obtained by early stopping. Our method is easy to implement, and can be integrated with any training scheme and architecture, without additional prior knowledge beyond the training set. Accordingly, it is a practical and useful tool to overcome overfit.
Relearning Forgotten Knowledge: on Forgetting, Overfit and Training-Free Ensembles of DNNs
Oct 17, 2023The infrequent occurrence of overfit in deep neural networks is perplexing. On the one hand, theory predicts that as models get larger they should eventually become too specialized for a specific training set, with ensuing decrease in generalization. In contrast, empirical results in image classification indicate that increasing the training time of deep models or using bigger models almost never hurts generalization. Is it because the way we measure overfit is too limited? Here, we introduce a novel score for quantifying overfit, which monitors the forgetting rate of deep models on validation data. Presumably, this score indicates that even while generalization improves overall, there are certain regions of the data space where it deteriorates. When thus measured, we show that overfit can occur with and without a decrease in validation accuracy, and may be more common than previously appreciated. This observation may help to clarify the aforementioned confusing picture. We use our observations to construct a new ensemble method, based solely on the training history of a single network, which provides significant improvement in performance without any additional cost in training time. An extensive empirical evaluation with modern deep models shows our method's utility on multiple datasets, neural networks architectures and training schemes, both when training from scratch and when using pre-trained networks in transfer learning. Notably, our method outperforms comparable methods while being easier to implement and use, and further improves the performance of competitive networks on Imagenet by 1\%.
Semi-Supervised Learning in the Few-Shot Zero-Shot Scenario
Aug 27, 2023Semi-Supervised Learning (SSL) leverages both labeled and unlabeled data to improve model performance. Traditional SSL methods assume that labeled and unlabeled data share the same label space. However, in real-world applications, especially when the labeled training set is small, there may be classes that are missing from the labeled set. Existing frameworks aim to either reject all unseen classes (open-set SSL) or to discover unseen classes by partitioning an unlabeled set during training (open-world SSL). In our work, we construct a classifier for points from both seen and unseen classes. Our approach is based on extending an existing SSL method, such as FlexMatch, by incorporating an additional entropy loss. This enhancement allows our method to improve the performance of any existing SSL method in the classification of both seen and unseen classes. We demonstrate large improvement gains over state-of-the-art SSL, open-set SSL, and open-world SSL methods, on two benchmark image classification data sets, CIFAR-100 and STL-10. The gains are most pronounced when the labeled data is severely limited (1-25 labeled examples per class).
Pruning the Unlabeled Data to Improve Semi-Supervised Learning
Aug 27, 2023

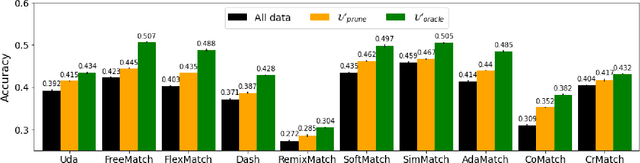
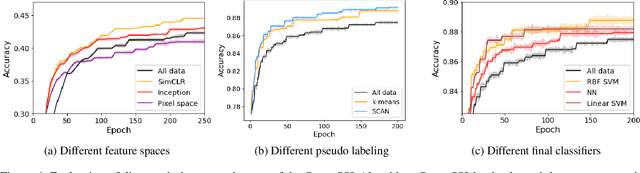
In the domain of semi-supervised learning (SSL), the conventional approach involves training a learner with a limited amount of labeled data alongside a substantial volume of unlabeled data, both drawn from the same underlying distribution. However, for deep learning models, this standard practice may not yield optimal results. In this research, we propose an alternative perspective, suggesting that distributions that are more readily separable could offer superior benefits to the learner as compared to the original distribution. To achieve this, we present PruneSSL, a practical technique for selectively removing examples from the original unlabeled dataset to enhance its separability. We present an empirical study, showing that although PruneSSL reduces the quantity of available training data for the learner, it significantly improves the performance of various competitive SSL algorithms, thereby achieving state-of-the-art results across several image classification tasks.