 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeActive Learning with a Noisy Annotator
Apr 06, 2025Active Learning (AL) aims to reduce annotation costs by strategically selecting the most informative samples for labeling. However, most active learning methods struggle in the low-budget regime where only a few labeled examples are available. This issue becomes even more pronounced when annotators provide noisy labels. A common AL approach for the low- and mid-budget regimes focuses on maximizing the coverage of the labeled set across the entire dataset. We propose a novel framework called Noise-Aware Active Sampling (NAS) that extends existing greedy, coverage-based active learning strategies to handle noisy annotations. NAS identifies regions that remain uncovered due to the selection of noisy representatives and enables resampling from these areas. We introduce a simple yet effective noise filtering approach suitable for the low-budget regime, which leverages the inner mechanism of NAS and can be applied for noise filtering before model training. On multiple computer vision benchmarks, including CIFAR100 and ImageNet subsets, NAS significantly improves performance for standard active learning methods across different noise types and rates.
Same accuracy, twice as fast: continuous training surpasses retraining from scratch
Feb 28, 2025Continual learning aims to enable models to adapt to new datasets without losing performance on previously learned data, often assuming that prior data is no longer available. However, in many practical scenarios, both old and new data are accessible. In such cases, good performance on both datasets is typically achieved by abandoning the model trained on the previous data and re-training a new model from scratch on both datasets. This training from scratch is computationally expensive. In contrast, methods that leverage the previously trained model and old data are worthy of investigation, as they could significantly reduce computational costs. Our evaluation framework quantifies the computational savings of such methods while maintaining or exceeding the performance of training from scratch. We identify key optimization aspects -- initialization, regularization, data selection, and hyper-parameters -- that can each contribute to reducing computational costs. For each aspect, we propose effective first-step methods that already yield substantial computational savings. By combining these methods, we achieve up to 2.7x reductions in computation time across various computer vision tasks, highlighting the potential for further advancements in this area.
Forgetting Order of Continual Learning: Examples That are Learned First are Forgotten Last
Jun 14, 2024Catastrophic forgetting poses a significant challenge in continual learning, where models often forget previous tasks when trained on new data. Our empirical analysis reveals a strong correlation between catastrophic forgetting and the learning speed of examples: examples learned early are rarely forgotten, while those learned later are more susceptible to forgetting. We demonstrate that replay-based continual learning methods can leverage this phenomenon by focusing on mid-learned examples for rehearsal. We introduce Goldilocks, a novel replay buffer sampling method that filters out examples learned too quickly or too slowly, keeping those learned at an intermediate speed. Goldilocks improves existing continual learning algorithms, leading to state-of-the-art performance across several image classification tasks.
Pruning the Unlabeled Data to Improve Semi-Supervised Learning
Aug 27, 2023

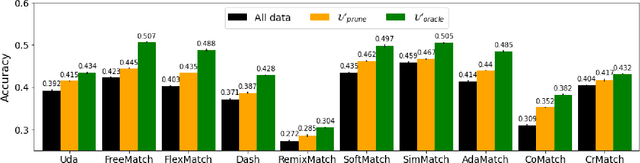
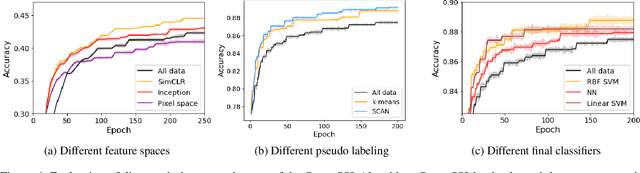
In the domain of semi-supervised learning (SSL), the conventional approach involves training a learner with a limited amount of labeled data alongside a substantial volume of unlabeled data, both drawn from the same underlying distribution. However, for deep learning models, this standard practice may not yield optimal results. In this research, we propose an alternative perspective, suggesting that distributions that are more readily separable could offer superior benefits to the learner as compared to the original distribution. To achieve this, we present PruneSSL, a practical technique for selectively removing examples from the original unlabeled dataset to enhance its separability. We present an empirical study, showing that although PruneSSL reduces the quantity of available training data for the learner, it significantly improves the performance of various competitive SSL algorithms, thereby achieving state-of-the-art results across several image classification tasks.
Semi-Supervised Learning in the Few-Shot Zero-Shot Scenario
Aug 27, 2023Semi-Supervised Learning (SSL) leverages both labeled and unlabeled data to improve model performance. Traditional SSL methods assume that labeled and unlabeled data share the same label space. However, in real-world applications, especially when the labeled training set is small, there may be classes that are missing from the labeled set. Existing frameworks aim to either reject all unseen classes (open-set SSL) or to discover unseen classes by partitioning an unlabeled set during training (open-world SSL). In our work, we construct a classifier for points from both seen and unseen classes. Our approach is based on extending an existing SSL method, such as FlexMatch, by incorporating an additional entropy loss. This enhancement allows our method to improve the performance of any existing SSL method in the classification of both seen and unseen classes. We demonstrate large improvement gains over state-of-the-art SSL, open-set SSL, and open-world SSL methods, on two benchmark image classification data sets, CIFAR-100 and STL-10. The gains are most pronounced when the labeled data is severely limited (1-25 labeled examples per class).
How to Select Which Active Learning Strategy is Best Suited for Your Specific Problem and Budget
Jun 06, 2023In Active Learning (AL), a learner actively chooses which unlabeled examples to query for labels from an oracle, under some budget constraints. Different AL query strategies are more suited to different problems and budgets. Therefore, in practice, knowing in advance which AL strategy is most suited for the problem at hand remains an open problem. To tackle this challenge, we propose a practical derivative-based method that dynamically identifies the best strategy for each budget. We provide theoretical analysis of a simplified case to motivate our approach and build intuition. We then introduce a method to dynamically select an AL strategy based on the specific problem and budget. Empirical results showcase the effectiveness of our approach across diverse budgets and computer vision tasks.
Active Learning Through a Covering Lens
May 23, 2022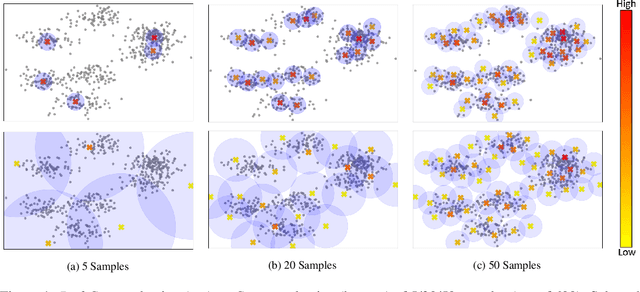


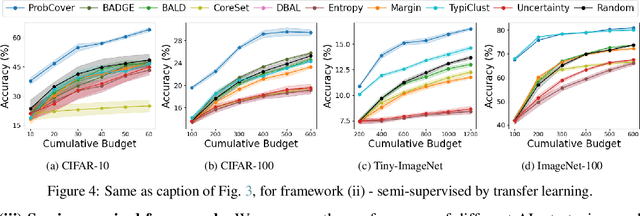
Deep active learning aims to reduce the annotation cost for deep neural networks, which are notoriously data-hungry. Until recently, deep active learning methods struggled in the low-budget regime, where only a small amount of samples are annotated. The situation has been alleviated by recent advances in self-supervised representation learning methods, which impart the geometry of the data representation with rich information about the points. Taking advantage of this progress, we study the problem of subset selection for annotation through a "covering" lens, proposing ProbCover -- a new active learning algorithm for the low budget regime, which seeks to maximize Probability Coverage. We describe a dual way to view our formulation, from which one can derive strategies suitable for the high budget regime of active learning, related to existing methods like Coreset. We conclude with extensive experiments, evaluating ProbCover in the low budget regime. We show that our principled active learning strategy improves the state-of-the-art in the low-budget regime in several image recognition benchmarks. This method is especially beneficial in semi-supervised settings, allowing state-of-the-art semi-supervised methods to achieve high accuracy with only a few labels.
Active Learning on a Budget: Opposite Strategies Suit High and Low Budgets
Feb 08, 2022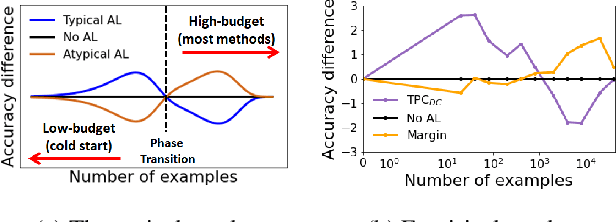
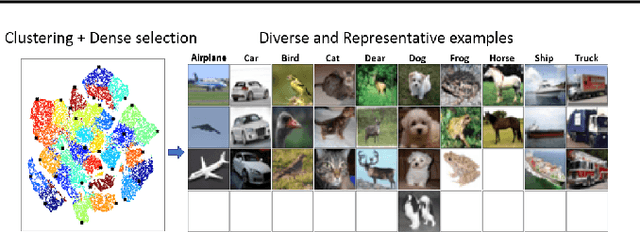
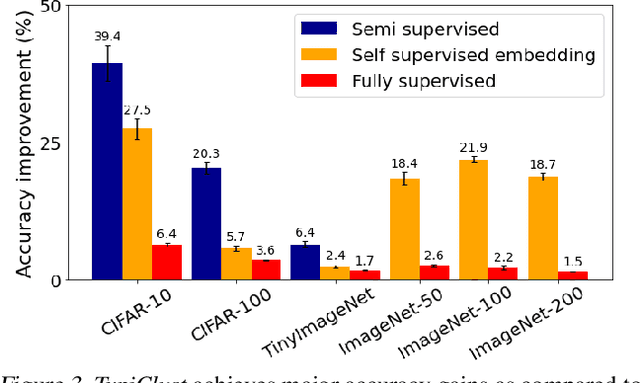
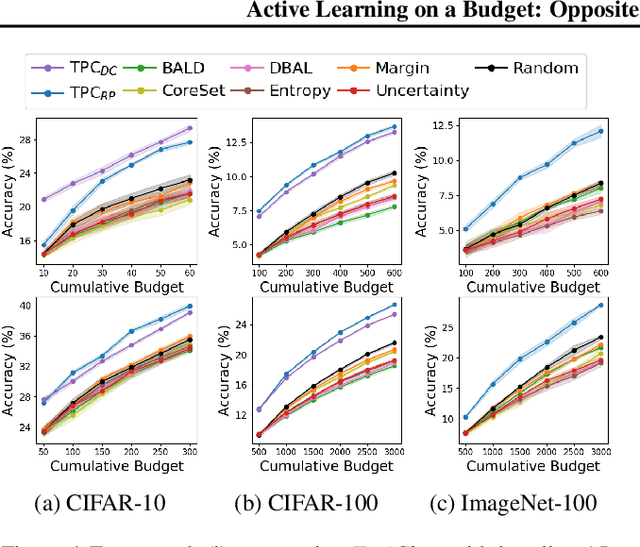
Investigating active learning, we focus on the relation between the number of labeled examples (budget size), and suitable corresponding querying strategies. Our theoretical analysis shows a behavior reminiscent of phase transition: typical points should best be queried in the low budget regime, while atypical (or uncertain) points are best queried when the budget is large. Combined evidence from our theoretical and empirical studies shows that a similar phenomenon occurs in simple classification models. Accordingly, we propose TypiClust -- a deep active learning strategy suited for low budgets. In a comparative empirical investigation using a variety of architectures and image datasets, we report that in the low budget regime, TypiClust outperforms all other active learning strategies. Using TypiClust in a semi-supervised framework, the performance of competitive semi-supervised methods gets a significant boost, surpassing the state of the art.
The Grammar-Learning Trajectories of Neural Language Models
Sep 13, 2021
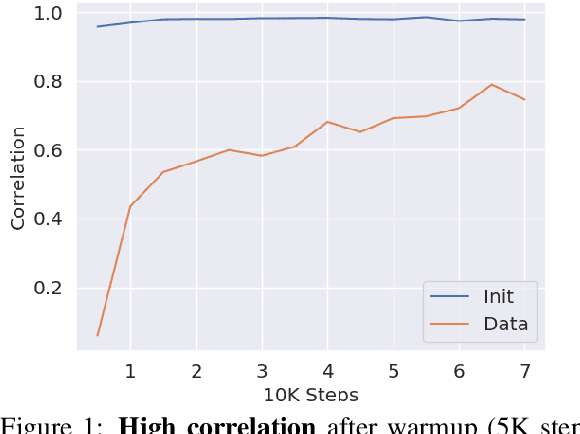
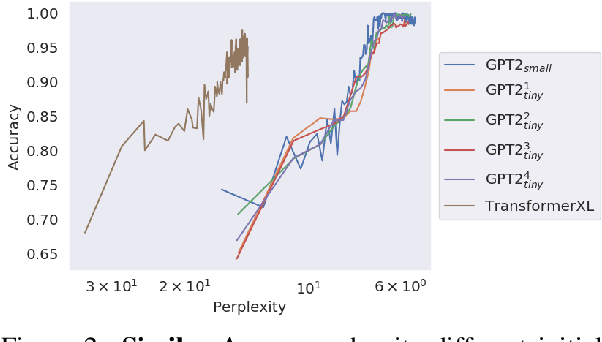
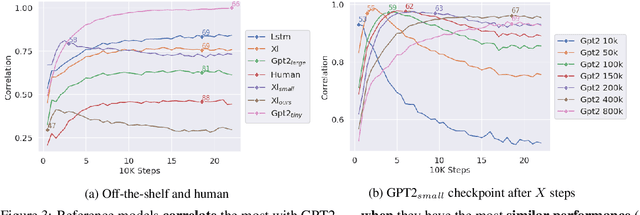
The learning trajectories of linguistic phenomena provide insight into the nature of linguistic representation, beyond what can be gleaned from inspecting the behavior of an adult speaker. To apply a similar approach to analyze neural language models (NLM), it is first necessary to establish that different models are similar enough in the generalizations they make. In this paper, we show that NLMs with different initialization, architecture, and training data acquire linguistic phenomena in a similar order, despite having different end performances over the data. Leveraging these findings, we compare the relative performance on different phenomena at varying learning stages with simpler reference models. Results suggest that NLMs exhibit consistent ``developmental'' stages. Initial analysis of these stages presents phenomena clusters (notably morphological ones), whose performance progresses in unison, suggesting potential links between their acquired representations.
Principal Components Bias in Deep Neural Networks
Jun 01, 2021
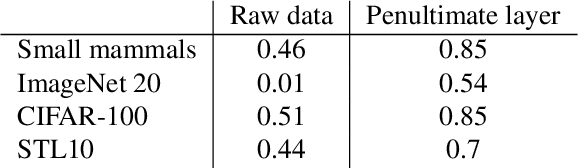


Recent work suggests that convolutional neural networks of different architectures learn to classify images in the same order. To understand this phenomenon, we revisit the over-parametrized deep linear network model. Our asymptotic analysis, assuming that the hidden layers are wide enough, reveals that the convergence rate of this model's parameters is exponentially faster along directions corresponding to the larger principal components of the data, at a rate governed by the singular values. We term this convergence pattern the Principal Components bias (PC-bias). We show how the PC-bias streamlines the order of learning of both linear and non-linear networks, more prominently at earlier stages of learning. We then compare our results to the spectral bias, showing that both biases can be seen independently, and affect the order of learning in different ways. Finally, we discuss how the PC-bias may explain some benefits of early stopping and its connection to PCA, and why deep networks converge more slowly when given random labels.