 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePrincipal Components Bias in Deep Neural Networks
Paper and Code
Jun 01, 2021
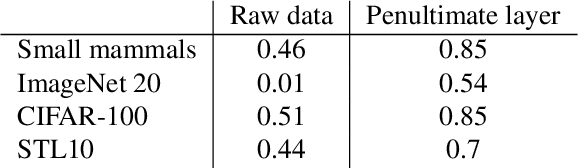


Recent work suggests that convolutional neural networks of different architectures learn to classify images in the same order. To understand this phenomenon, we revisit the over-parametrized deep linear network model. Our asymptotic analysis, assuming that the hidden layers are wide enough, reveals that the convergence rate of this model's parameters is exponentially faster along directions corresponding to the larger principal components of the data, at a rate governed by the singular values. We term this convergence pattern the Principal Components bias (PC-bias). We show how the PC-bias streamlines the order of learning of both linear and non-linear networks, more prominently at earlier stages of learning. We then compare our results to the spectral bias, showing that both biases can be seen independently, and affect the order of learning in different ways. Finally, we discuss how the PC-bias may explain some benefits of early stopping and its connection to PCA, and why deep networks converge more slowly when given random labels.