 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpeaker Attributed Automatic Speech Recognition Using Speech Aware LLMS
Apr 13, 2026Speaker-Attributed Automatic Speech Recognition (SAA) enhances traditional ASR systems by incorporating relative speaker identity tags directly into the transcript (e.g., [Speaker 1]:, [Speaker 2]:). In this work, we extend the capabilities of Granite-speech, a state-of-the-art speech-aware Large Language Model (LLM) originally trained for transcription and translation. We demonstrate that it can be effectively adapted for SAA with only minimal architectural changes. Our core contribution is the introduction of speaker cluster identification tags (e.g., [Speaker 1 cluster 42]:) which are jointly trained with SAA to significantly improve accuracy. To address limitations in training data, we propose a data augmentation method that uses artificially concatenated multi-speaker conversations. Our approach is evaluated across multiple benchmarks and shows superior performance compared to conventional pipelines that sequentially perform speaker diarization followed by ASR.
Knowing What to Stress: A Discourse-Conditioned Text-to-Speech Benchmark
Apr 12, 2026Spoken meaning often depends not only on what is said, but also on which word is emphasized. The same sentence can convey correction, contrast, or clarification depending on where emphasis falls. Although modern text-to-speech (TTS) systems generate expressive speech, it remains unclear whether they infer contextually appropriate stress from discourse alone. To address this gap, we present Context-Aware Stress TTS (CAST), a benchmark for evaluating context-conditioned word-level stress in TTS. Items are defined as contrastive context pairs: identical sentences paired with distinct contexts requiring different stressed words. We evaluate state-of-the-art systems and find a consistent gap: text-only language models reliably recover the intended stress from context, yet TTS systems frequently fail to realize it in speech. We release the benchmark, evaluation framework, construction pipeline and a synthetic corpus to support future work on context-aware speech synthesis.
Balanced Thinking: Improving Chain of Thought Training in Vision Language Models
Mar 19, 2026Multimodal reasoning in vision-language models (VLMs) typically relies on a two-stage process: supervised fine-tuning (SFT) and reinforcement learning (RL). In standard SFT, all tokens contribute equally to the loss, even though reasoning data are inherently token-imbalanced. Long <think> traces overshadow short but task-critical <answer> segments, leading to verbose reasoning and inaccurate answers. We propose SCALe (Scheduled Curriculum Adaptive Loss), which explicitly separates supervision over reasoning and answer segments using dynamic, length-independent weighting. Unlike vanilla SFT, which overweights the <think> segment, SCALe-SFT gradually shifts the focus from <think> to <answer> throughout training via a cosine scheduling policy, encouraging concise and well-grounded reasoning. We evaluate SCALe across diverse benchmarks and architectures. Results show that SCALe consistently improves accuracy over vanilla SFT and matches the performance of the full two-phase SFT + GRPO pipeline while requiring only about one-seventh of the training time, making it a lightweight yet effective alternative. When combined with GRPO, SCALe achieves the best overall performance, highlighting its value both as a standalone method and as a strong foundation for reinforcement refinement.
Self-Speculative Decoding for LLM-based ASR with CTC Encoder Drafts
Mar 11, 2026We propose self-speculative decoding for speech-aware LLMs by using the CTC encoder as a draft model to accelerate auto-regressive (AR) inference and improve ASR accuracy. Our three-step procedure works as follows: (1) if the frame entropies of the CTC output distributions are below a threshold, the greedy CTC hypothesis is accepted as final; (2) otherwise, the CTC hypothesis is verified in a single LLM forward pass using a relaxed acceptance criterion based on token likelihoods; (3) if verification fails, AR decoding resumes from the accepted CTC prefix. Experiments on nine corpora and five languages show that this approach can simultaneously accelerate decoding and reduce WER. On the HuggingFace Open ASR benchmark with a 1B parameter LLM and 440M parameter CTC encoder, we achieve a record 5.58% WER and improve the inverse real time factor by a factor of 4.4 with only a 12% relative WER increase over AR search. Code and model weights are publicly available under a permissive license.
NLE: Non-autoregressive LLM-based ASR by Transcript Editing
Mar 09, 2026While autoregressive (AR) LLM-based ASR systems achieve strong accuracy, their sequential decoding limits parallelism and incurs high latency. We propose NLE, a non-autoregressive (NAR) approach that formulates speech recognition as conditional transcript editing, enabling fully parallel prediction. NLE extracts acoustic embeddings and an initial hypothesis from a pretrained speech encoder, then refines the hypothesis using a bidirectional LLM editor trained with a latent alignment objective. An interleaved padding strategy exploits the identity mapping bias of Transformers, allowing the model to focus on corrections rather than full reconstruction. On the Open ASR leaderboard, NLE++ achieves 5.67% average WER with an RTFx (inverse real-time factor) of 1630. In single-utterance scenarios, NLE achieves 27x speedup over the AR baseline, making it suitable for real-time applications.
Spoken question answering for visual queries
May 29, 2025Question answering (QA) systems are designed to answer natural language questions. Visual QA (VQA) and Spoken QA (SQA) systems extend the textual QA system to accept visual and spoken input respectively. This work aims to create a system that enables user interaction through both speech and images. That is achieved through the fusion of text, speech, and image modalities to tackle the task of spoken VQA (SVQA). The resulting multi-modal model has textual, visual, and spoken inputs and can answer spoken questions on images. Training and evaluating SVQA models requires a dataset for all three modalities, but no such dataset currently exists. We address this problem by synthesizing VQA datasets using two zero-shot TTS models. Our initial findings indicate that a model trained only with synthesized speech nearly reaches the performance of the upper-bounding model trained on textual QAs. In addition, we show that the choice of the TTS model has a minor impact on accuracy.
Granite-speech: open-source speech-aware LLMs with strong English ASR capabilities
May 14, 2025Granite-speech LLMs are compact and efficient speech language models specifically designed for English ASR and automatic speech translation (AST). The models were trained by modality aligning the 2B and 8B parameter variants of granite-3.3-instruct to speech on publicly available open-source corpora containing audio inputs and text targets consisting of either human transcripts for ASR or automatically generated translations for AST. Comprehensive benchmarking shows that on English ASR, which was our primary focus, they outperform several competitors' models that were trained on orders of magnitude more proprietary data, and they keep pace on English-to-X AST for major European languages, Japanese, and Chinese. The speech-specific components are: a conformer acoustic encoder using block attention and self-conditioning trained with connectionist temporal classification, a windowed query-transformer speech modality adapter used to do temporal downsampling of the acoustic embeddings and map them to the LLM text embedding space, and LoRA adapters to further fine-tune the text LLM. Granite-speech-3.3 operates in two modes: in speech mode, it performs ASR and AST by activating the encoder, projector, and LoRA adapters; in text mode, it calls the underlying granite-3.3-instruct model directly (without LoRA), essentially preserving all the text LLM capabilities and safety. Both models are freely available on HuggingFace (https://huggingface.co/ibm-granite/granite-speech-3.3-2b and https://huggingface.co/ibm-granite/granite-speech-3.3-8b) and can be used for both research and commercial purposes under a permissive Apache 2.0 license.
Continuous Speech Synthesis using per-token Latent Diffusion
Oct 21, 2024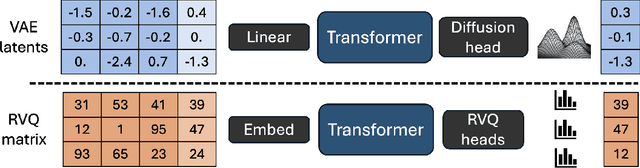
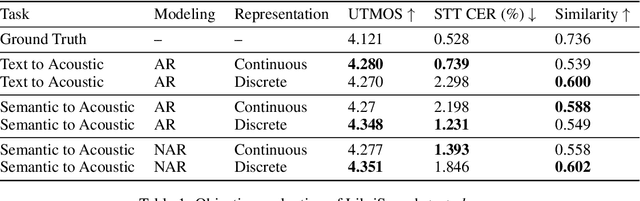
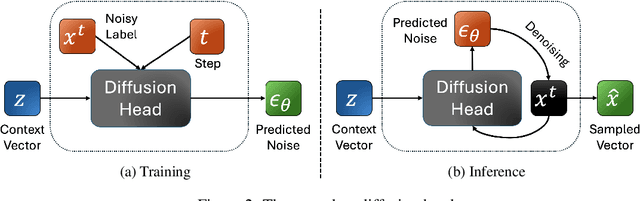

The success of autoregressive transformer models with discrete tokens has inspired quantization-based approaches for continuous modalities, though these often limit reconstruction quality. We therefore introduce SALAD, a per-token latent diffusion model for zero-shot text-to-speech, that operates on continuous representations. SALAD builds upon the recently proposed expressive diffusion head for image generation, and extends it to generate variable-length outputs. Our approach utilizes semantic tokens for providing contextual information and determining the stopping condition. We suggest three continuous variants for our method, extending popular discrete speech synthesis techniques. Additionally, we implement discrete baselines for each variant and conduct a comparative analysis of discrete versus continuous speech modeling techniques. Our results demonstrate that both continuous and discrete approaches are highly competent, and that SALAD achieves a superior intelligibility score while obtaining speech quality and speaker similarity on par with the ground-truth audio.
Low Bitrate High-Quality RVQGAN-based Discrete Speech Tokenizer
Oct 10, 2024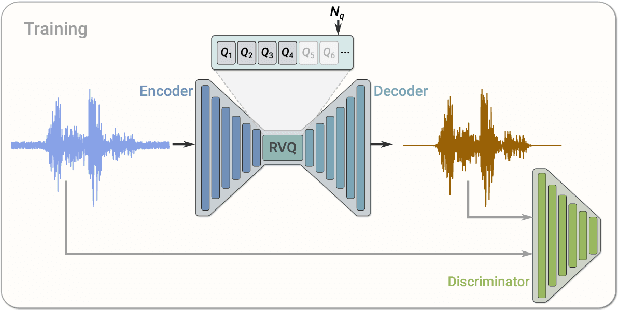



Discrete Audio codecs (or audio tokenizers) have recently regained interest due to the ability of Large Language Models (LLMs) to learn their compressed acoustic representations. Various publicly available trainable discrete tokenizers recently demonstrated impressive results for audio tokenization, yet they mostly require high token rates to gain high-quality reconstruction. In this study, we fine-tuned an open-source general audio RVQGAN model using diverse open-source speech data, considering various recording conditions and quality levels. The resulting wideband (24kHz) speech-only model achieves speech reconstruction, which is nearly indistinguishable from PCM (pulse-code modulation) with a rate of 150-300 tokens per second (1500-3000 bps). The evaluation used comprehensive English speech data encompassing different recording conditions, including studio settings. Speech samples are made publicly available in http://ibm.biz/IS24SpeechRVQ . The model is officially released in https://huggingface.co/ibm/DAC.speech.v1.0
* You can download the model from https://huggingface.co/ibm/DAC.speech.v1.0
Exploring the Benefits of Tokenization of Discrete Acoustic Units
Jun 08, 2024



Tokenization algorithms that merge the units of a base vocabulary into larger, variable-rate units have become standard in natural language processing tasks. This idea, however, has been mostly overlooked when the vocabulary consists of phonemes or Discrete Acoustic Units (DAUs), an audio-based representation that is playing an increasingly important role due to the success of discrete language-modeling techniques. In this paper, we showcase the advantages of tokenization of phonetic units and of DAUs on three prediction tasks: grapheme-to-phoneme, grapheme-to-DAUs, and unsupervised speech generation using DAU language modeling. We demonstrate that tokenization yields significant improvements in terms of performance, as well as training and inference speed, across all three tasks. We also offer theoretical insights to provide some explanation for the superior performance observed.