 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLow Bitrate High-Quality RVQGAN-based Discrete Speech Tokenizer
Paper and Code
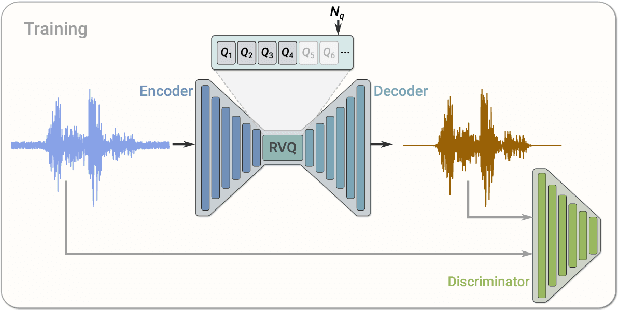



Discrete Audio codecs (or audio tokenizers) have recently regained interest due to the ability of Large Language Models (LLMs) to learn their compressed acoustic representations. Various publicly available trainable discrete tokenizers recently demonstrated impressive results for audio tokenization, yet they mostly require high token rates to gain high-quality reconstruction. In this study, we fine-tuned an open-source general audio RVQGAN model using diverse open-source speech data, considering various recording conditions and quality levels. The resulting wideband (24kHz) speech-only model achieves speech reconstruction, which is nearly indistinguishable from PCM (pulse-code modulation) with a rate of 150-300 tokens per second (1500-3000 bps). The evaluation used comprehensive English speech data encompassing different recording conditions, including studio settings. Speech samples are made publicly available in http://ibm.biz/IS24SpeechRVQ . The model is officially released in https://huggingface.co/ibm/DAC.speech.v1.0