 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpeak While You Think: Streaming Speech Synthesis During Text Generation
Paper and Code
Sep 20, 2023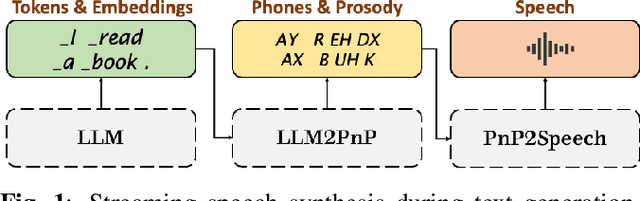
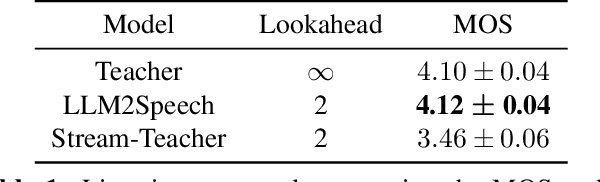
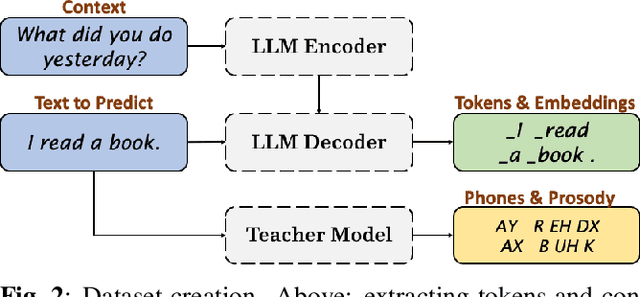
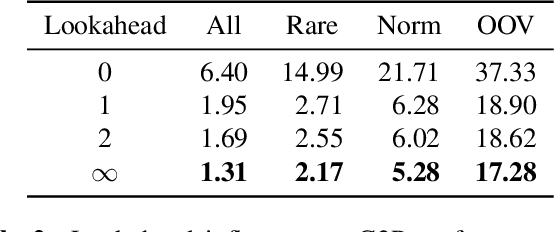
Large Language Models (LLMs) demonstrate impressive capabilities, yet interaction with these models is mostly facilitated through text. Using Text-To-Speech to synthesize LLM outputs typically results in notable latency, which is impractical for fluent voice conversations. We propose LLM2Speech, an architecture to synthesize speech while text is being generated by an LLM which yields significant latency reduction. LLM2Speech mimics the predictions of a non-streaming teacher model while limiting the exposure to future context in order to enable streaming. It exploits the hidden embeddings of the LLM, a by-product of the text generation that contains informative semantic context. Experimental results show that LLM2Speech maintains the teacher's quality while reducing the latency to enable natural conversations.