 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExploring the Benefits of Tokenization of Discrete Acoustic Units
Jun 08, 2024



Tokenization algorithms that merge the units of a base vocabulary into larger, variable-rate units have become standard in natural language processing tasks. This idea, however, has been mostly overlooked when the vocabulary consists of phonemes or Discrete Acoustic Units (DAUs), an audio-based representation that is playing an increasingly important role due to the success of discrete language-modeling techniques. In this paper, we showcase the advantages of tokenization of phonetic units and of DAUs on three prediction tasks: grapheme-to-phoneme, grapheme-to-DAUs, and unsupervised speech generation using DAU language modeling. We demonstrate that tokenization yields significant improvements in terms of performance, as well as training and inference speed, across all three tasks. We also offer theoretical insights to provide some explanation for the superior performance observed.
Creating an African American-Sounding TTS: Guidelines, Technical Challenges,and Surprising Evaluations
Mar 17, 2024
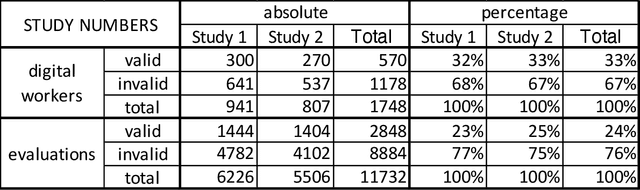

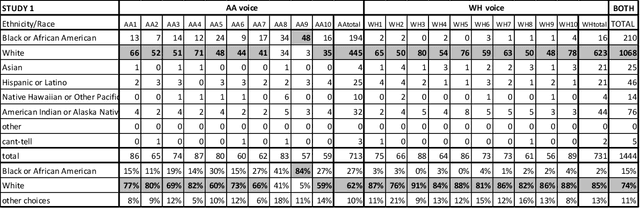
Representations of AI agents in user interfaces and robotics are predominantly White, not only in terms of facial and skin features, but also in the synthetic voices they use. In this paper we explore some unexpected challenges in the representation of race we found in the process of developing an U.S. English Text-to-Speech (TTS) system aimed to sound like an educated, professional, regional accent-free African American woman. The paper starts by presenting the results of focus groups with African American IT professionals where guidelines and challenges for the creation of a representative and appropriate TTS system were discussed and gathered, followed by a discussion about some of the technical difficulties faced by the TTS system developers. We then describe two studies with U.S. English speakers where the participants were not able to attribute the correct race to the African American TTS voice while overwhelmingly correctly recognizing the race of a White TTS system of similar quality. A focus group with African American IT workers not only confirmed the representativeness of the African American voice we built, but also suggested that the surprising recognition results may have been caused by the inability or the latent prejudice from non-African Americans to associate educated, non-vernacular, professionally-sounding voices to African American people.
Speak While You Think: Streaming Speech Synthesis During Text Generation
Sep 20, 2023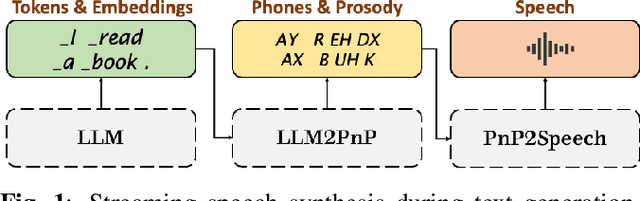
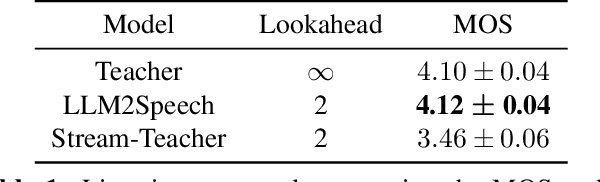
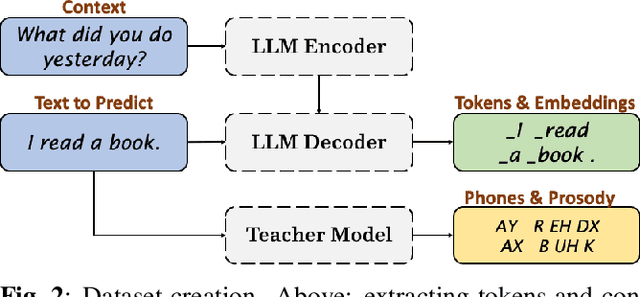
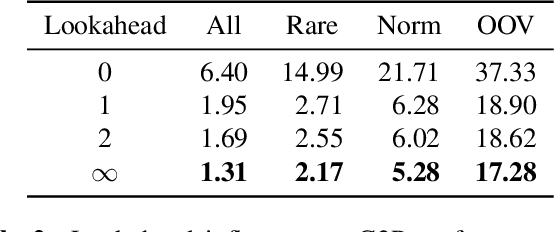
Large Language Models (LLMs) demonstrate impressive capabilities, yet interaction with these models is mostly facilitated through text. Using Text-To-Speech to synthesize LLM outputs typically results in notable latency, which is impractical for fluent voice conversations. We propose LLM2Speech, an architecture to synthesize speech while text is being generated by an LLM which yields significant latency reduction. LLM2Speech mimics the predictions of a non-streaming teacher model while limiting the exposure to future context in order to enable streaming. It exploits the hidden embeddings of the LLM, a by-product of the text generation that contains informative semantic context. Experimental results show that LLM2Speech maintains the teacher's quality while reducing the latency to enable natural conversations.
A Neural TTS System with Parallel Prosody Transfer from Unseen Speakers
Sep 20, 2023



Modern neural TTS systems are capable of generating natural and expressive speech when provided with sufficient amounts of training data. Such systems can be equipped with prosody-control functionality, allowing for more direct shaping of the speech output at inference time. In some TTS applications, it may be desirable to have an option that guides the TTS system with an ad-hoc speech recording exemplar to impose an implicit fine-grained, user-preferred prosodic realization for certain input prompts. In this work we present a first-of-its-kind neural TTS system equipped with such functionality to transfer the prosody from a parallel text recording from an unseen speaker. We demonstrate that the proposed system can precisely transfer the speech prosody from novel speakers to various trained TTS voices with no quality degradation, while preserving the target TTS speakers' identity, as evaluated by a set of subjective listening experiments.
* Presented at Interspeech 2023
Transplantation of Conversational Speaking Style with Interjections in Sequence-to-Sequence Speech Synthesis
Jul 25, 2022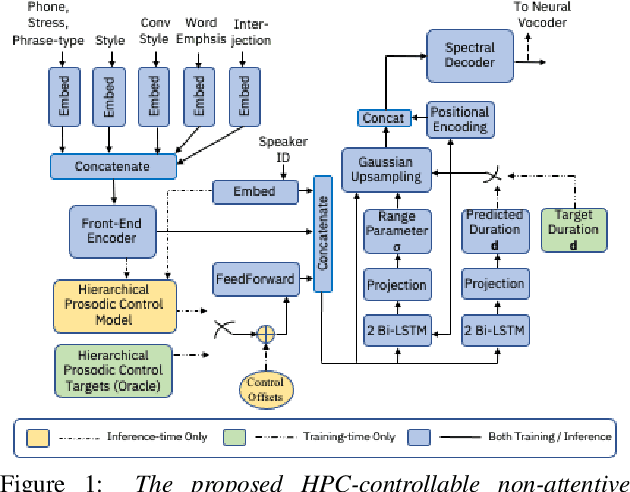

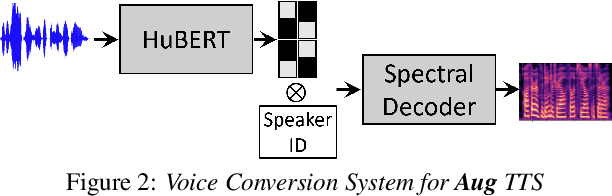

Sequence-to-Sequence Text-to-Speech architectures that directly generate low level acoustic features from phonetic sequences are known to produce natural and expressive speech when provided with adequate amounts of training data. Such systems can learn and transfer desired speaking styles from one seen speaker to another (in multi-style multi-speaker settings), which is highly desirable for creating scalable and customizable Human-Computer Interaction systems. In this work we explore one-to-many style transfer from a dedicated single-speaker conversational corpus with style nuances and interjections. We elaborate on the corpus design and explore the feasibility of such style transfer when assisted with Voice-Conversion-based data augmentation. In a set of subjective listening experiments, this approach resulted in high-fidelity style transfer with no quality degradation. However, a certain voice persona shift was observed, requiring further improvements in voice conversion.
Supervised and Unsupervised Approaches for Controlling Narrow Lexical Focus in Sequence-to-Sequence Speech Synthesis
Jan 25, 2021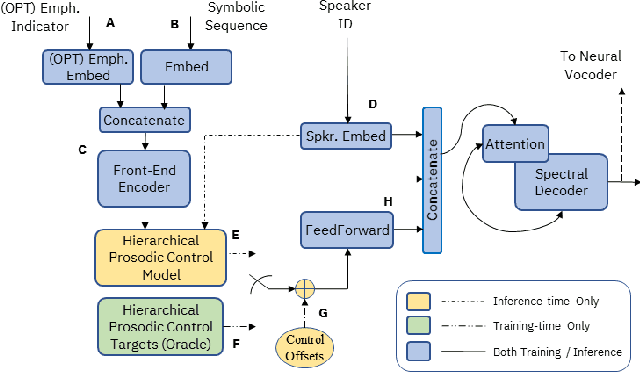
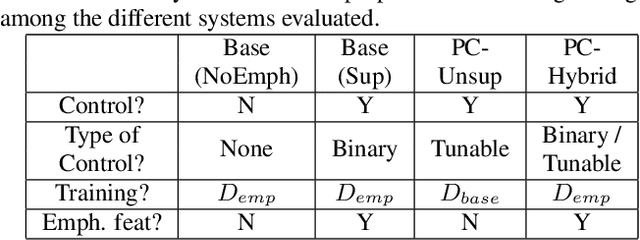
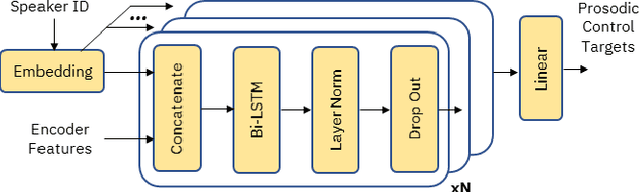
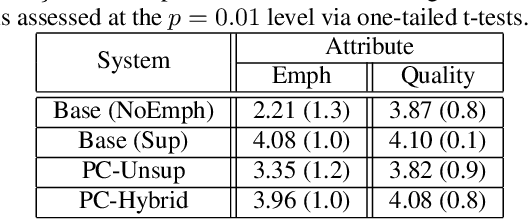
Although Sequence-to-Sequence (S2S) architectures have become state-of-the-art in speech synthesis, capable of generating outputs that approach the perceptual quality of natural samples, they are limited by a lack of flexibility when it comes to controlling the output. In this work we present a framework capable of controlling the prosodic output via a set of concise, interpretable, disentangled parameters. We apply this framework to the realization of emphatic lexical focus, proposing a variety of architectures designed to exploit different levels of supervision based on the availability of labeled resources. We evaluate these approaches via listening tests that demonstrate we are able to successfully realize controllable focus while maintaining the same, or higher, naturalness over an established baseline, and we explore how the different approaches compare when synthesizing in a target voice with or without labeled data.