 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA methodological analysis of prompt perturbations and their effect on attack success rates
Nov 11, 2025This work aims to investigate how different Large Language Models (LLMs) alignment methods affect the models' responses to prompt attacks. We selected open source models based on the most common alignment methods, namely, Supervised Fine-Tuning (SFT), Direct Preference Optimization (DPO), and Reinforcement Learning with Human Feedback (RLHF). We conducted a systematic analysis using statistical methods to verify how sensitive the Attack Success Rate (ASR) is when we apply variations to prompts designed to elicit inappropriate content from LLMs. Our results show that even small prompt modifications can significantly change the Attack Success Rate (ASR) according to the statistical tests we run, making the models more or less susceptible to types of attack. Critically, our results demonstrate that running existing 'attack benchmarks' alone may not be sufficient to elicit all possible vulnerabilities of both models and alignment methods. This paper thus contributes to ongoing efforts on model attack evaluation by means of systematic and statistically-based analyses of the different alignment methods and how sensitive their ASR is to prompt variation.
Harnessing the Power of Artificial Intelligence to Vitalize Endangered Indigenous Languages: Technologies and Experiences
Jul 17, 2024Since 2022 we have been exploring application areas and technologies in which Artificial Intelligence (AI) and modern Natural Language Processing (NLP), such as Large Language Models (LLMs), can be employed to foster the usage and facilitate the documentation of Indigenous languages which are in danger of disappearing. We start by discussing the decreasing diversity of languages in the world and how working with Indigenous languages poses unique ethical challenges for AI and NLP. To address those challenges, we propose an alternative development AI cycle based on community engagement and usage. Then, we report encouraging results in the development of high-quality machine learning translators for Indigenous languages by fine-tuning state-of-the-art (SOTA) translators with tiny amounts of data and discuss how to avoid some common pitfalls in the process. We also present prototypes we have built in projects done in 2023 and 2024 with Indigenous communities in Brazil, aimed at facilitating writing, and discuss the development of Indigenous Language Models (ILMs) as a replicable and scalable way to create spell-checkers, next-word predictors, and similar tools. Finally, we discuss how we envision a future for language documentation where dying languages are preserved as interactive language models.
Creating an African American-Sounding TTS: Guidelines, Technical Challenges,and Surprising Evaluations
Mar 17, 2024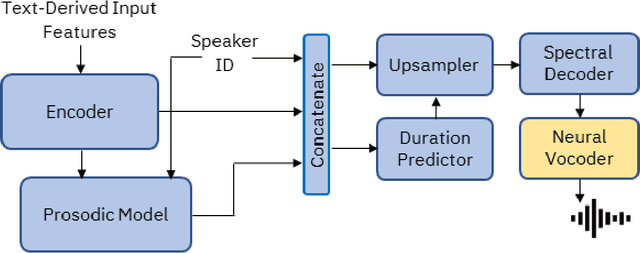
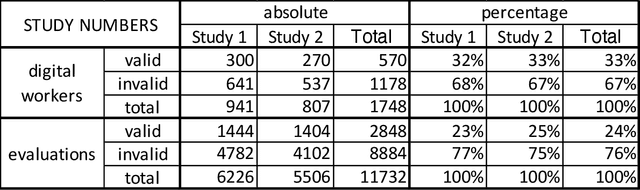

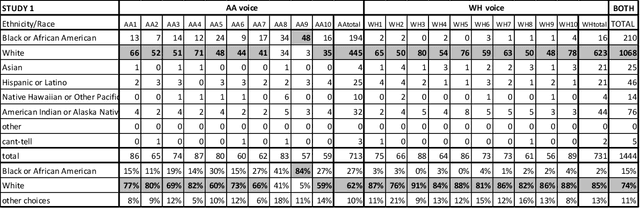
Representations of AI agents in user interfaces and robotics are predominantly White, not only in terms of facial and skin features, but also in the synthetic voices they use. In this paper we explore some unexpected challenges in the representation of race we found in the process of developing an U.S. English Text-to-Speech (TTS) system aimed to sound like an educated, professional, regional accent-free African American woman. The paper starts by presenting the results of focus groups with African American IT professionals where guidelines and challenges for the creation of a representative and appropriate TTS system were discussed and gathered, followed by a discussion about some of the technical difficulties faced by the TTS system developers. We then describe two studies with U.S. English speakers where the participants were not able to attribute the correct race to the African American TTS voice while overwhelmingly correctly recognizing the race of a White TTS system of similar quality. A focus group with African American IT workers not only confirmed the representativeness of the African American voice we built, but also suggested that the surprising recognition results may have been caused by the inability or the latent prejudice from non-African Americans to associate educated, non-vernacular, professionally-sounding voices to African American people.
Exploring the Advantages of Dense-Vector to One-Hot Encoding of Intent Classes in Out-of-Scope Detection Tasks
May 18, 2022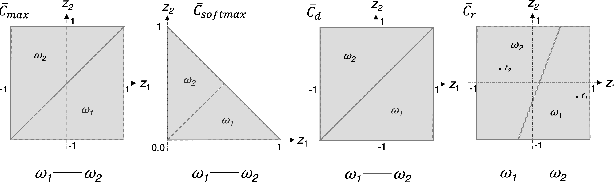
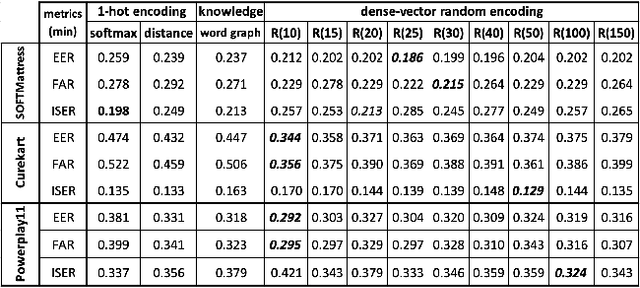
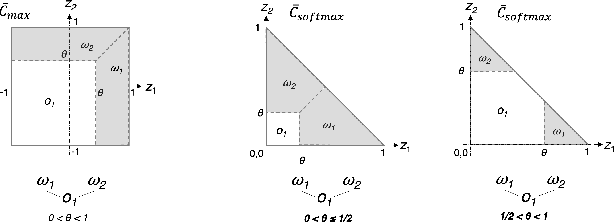
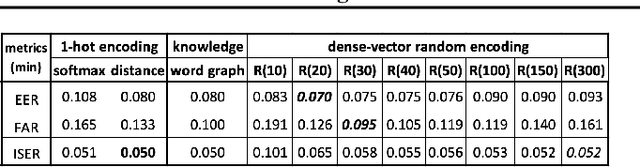
This work explores the intrinsic limitations of the popular one-hot encoding method in classification of intents when detection of out-of-scope (OOS) inputs is required. Although recent work has shown that there can be significant improvements in OOS detection when the intent classes are represented as dense-vectors based on domain specific knowledge, we argue in this paper that such gains are more likely due to advantages of dense-vector to one-hot encoding methods in representing the complexity of the OOS space. We start by showing how dense-vector encodings can create OOS spaces with much richer topologies than one-hot encoding methods. We then demonstrate empirically, using four standard intent classification datasets, that knowledge-free, randomly generated dense-vector encodings of intent classes can yield massive, over 20% gains over one-hot encodings, and also outperform the previous, domain knowledge-based, SOTA of one of the datasets. We finish by describing a novel algorithm to search for good dense-vector encodings and present initial but promising experimental results of its use.
Using Meta-Knowledge Mined from Identifiers to Improve Intent Recognition in Neuro-Symbolic Algorithms
Dec 16, 2020
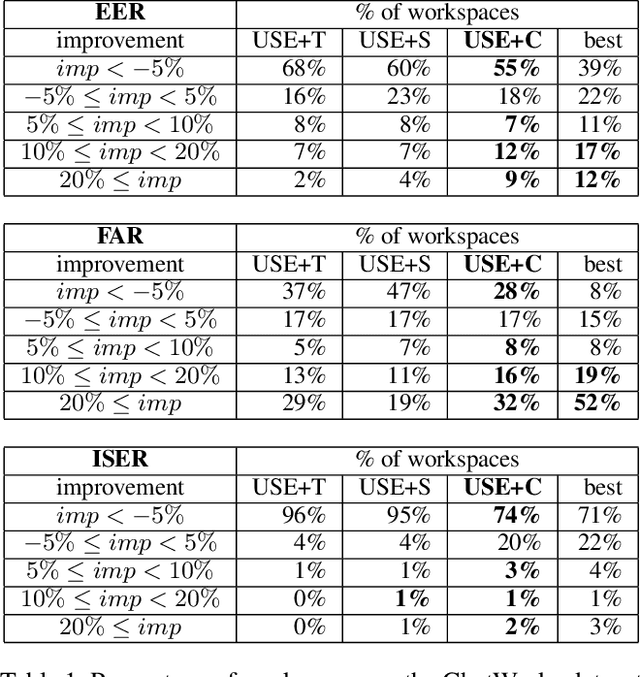
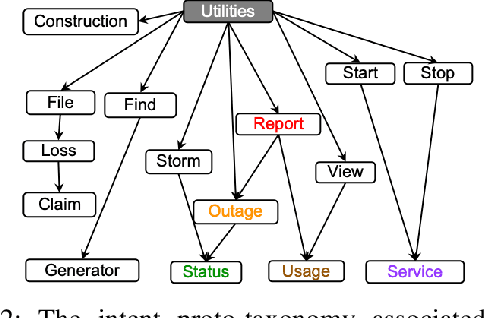
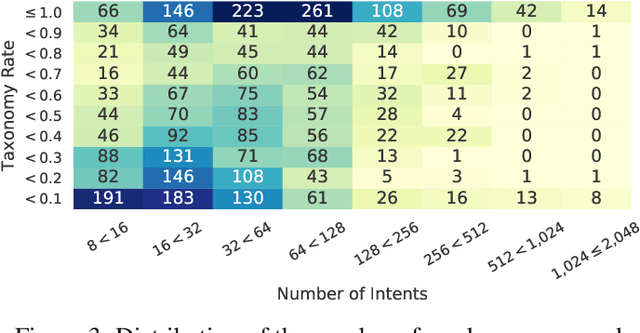
In this paper we explore the use of meta-knowledge embedded in intent identifiers to improve intent recognition in conversational systems. As evidenced by the analysis of thousands of real-world chatbots and in interviews with professional chatbot curators, developers and domain experts tend to organize the set of chatbot intents by identifying them using proto-taxonomies, i.e., meta-knowledge connecting high-level, symbolic concepts shared across different intents. By using neuro-symbolic algorithms able to incorporate such proto-taxonomies to expand intent representation, we show that such mined meta-knowledge can improve accuracy in intent recognition. In a dataset with intents and example utterances from hundreds of professional chatbots, we saw improvements of more than 10% in the equal error rate (EER) in almost a third of the chatbots when we apply those algorithms in comparison to a baseline of the same algorithms without the meta-knowledge. The meta-knowledge proved to be even more relevant in detecting out-of-scope utterances, decreasing the false acceptance rate (FAR) in more than 20\% in about half of the chatbots. The experiments demonstrate that such symbolic meta-knowledge structures can be effectively mined and used by neuro-symbolic algorithms, apparently by incorporating into the learning process higher-level structures of the problem being solved. Based on these results, we also discuss how the use of mined meta-knowledge can be an answer for the challenge of knowledge acquisition in neuro-symbolic algorithms.
A Hybrid Solution to Learn Turn-Taking in Multi-Party Service-based Chat Groups
Jan 14, 2020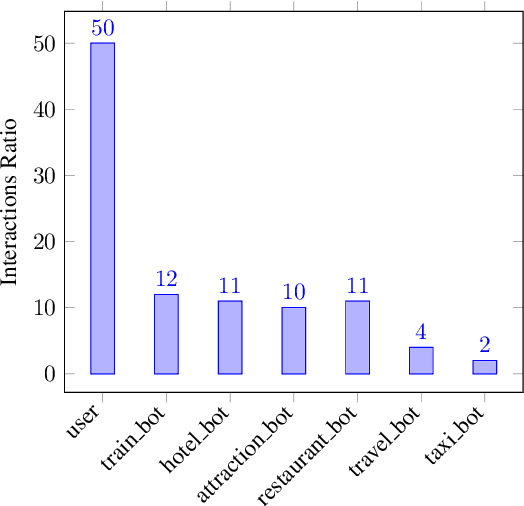
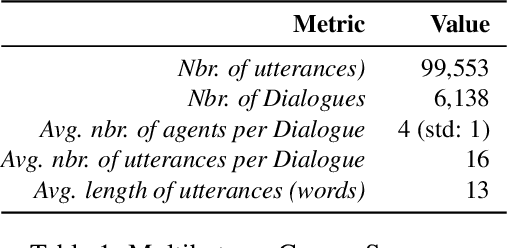
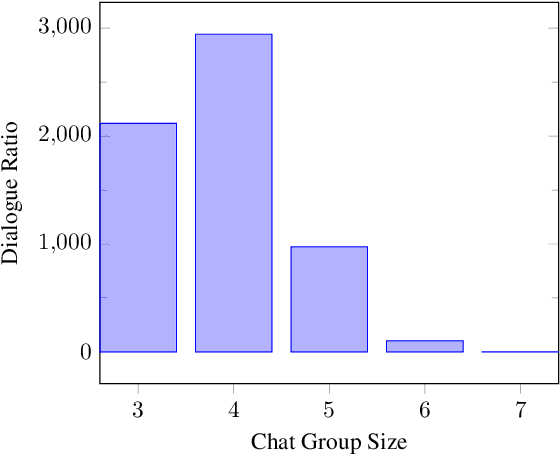

To predict the next most likely participant to interact in a multi-party conversation is a difficult problem. In a text-based chat group, the only information available is the sender, the content of the text and the dialogue history. In this paper we present our study on how these information can be used on the prediction task through a corpus and architecture that integrates turn-taking classifiers based on Maximum Likelihood Expectation (MLE), Convolutional Neural Networks (CNN) and Finite State Automata (FSA). The corpus is a synthetic adaptation of the Multi-Domain Wizard-of-Oz dataset (MultiWOZ) to a multiple travel service-based bots scenario with dialogue errors and was created to simulate user's interaction and evaluate the architecture. We present experimental results which show that the CNN approach achieves better performance than the baseline with an accuracy of 92.34%, but the integrated solution with MLE, CNN and FSA achieves performance even better, with 95.65%.
Learning Multi-Party Turn-Taking Models from Dialogue Logs
Jul 03, 2019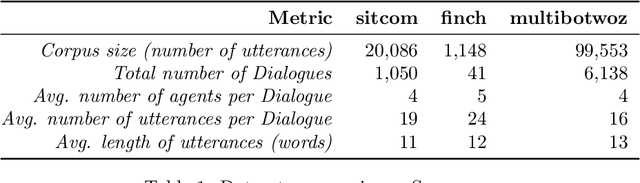

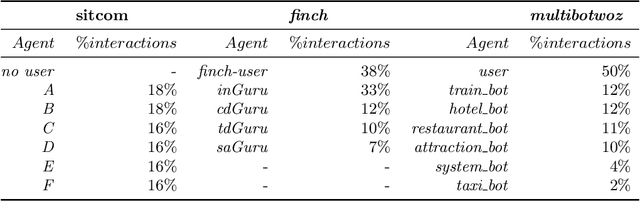
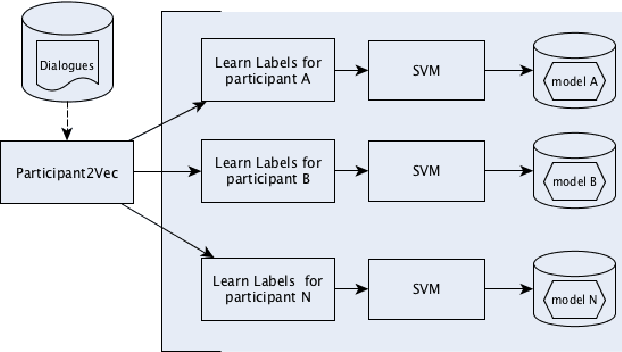
This paper investigates the application of machine learning (ML) techniques to enable intelligent systems to learn multi-party turn-taking models from dialogue logs. The specific ML task consists of determining who speaks next, after each utterance of a dialogue, given who has spoken and what was said in the previous utterances. With this goal, this paper presents comparisons of the accuracy of different ML techniques such as Maximum Likelihood Estimation (MLE), Support Vector Machines (SVM), and Convolutional Neural Networks (CNN) architectures, with and without utterance data. We present three corpora: the first with dialogues from an American TV situated comedy (chit-chat), the second with logs from a financial advice multi-bot system and the third with a corpus created from the Multi-Domain Wizard-of-Oz dataset (both are topic-oriented). The results show: (i) the size of the corpus has a very positive impact on the accuracy for the content-based deep learning approaches and those models perform best in the larger datasets; and (ii) if the dialogue dataset is small and topic-oriented (but with few topics), it is sufficient to use an agent-only MLE or SVM models, although slightly higher accuracies can be achieved with the use of the content of the utterances with a CNN model.
A Hybrid Architecture for Multi-Party Conversational Systems
May 04, 2017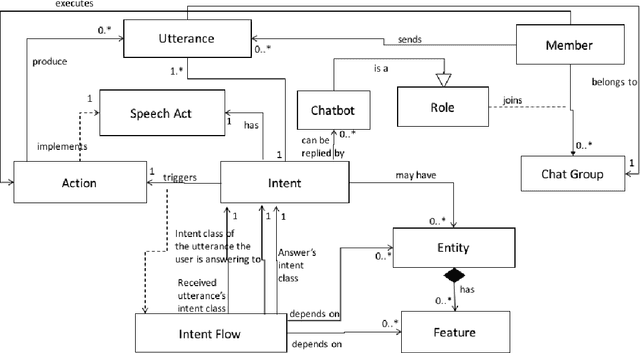
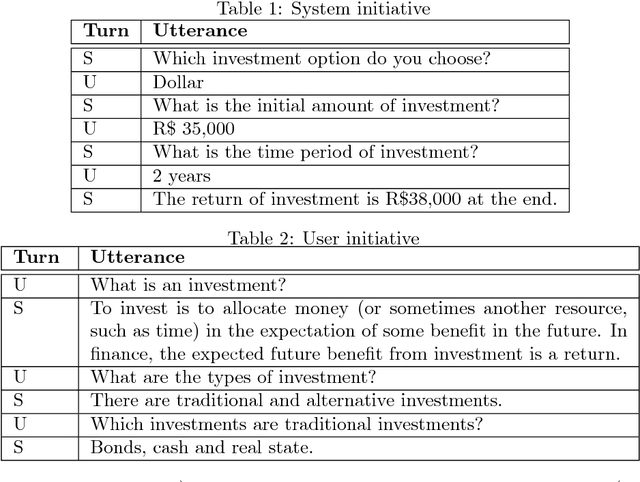
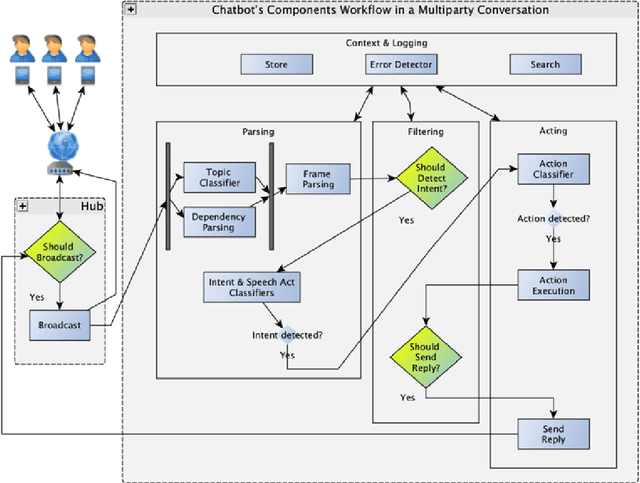
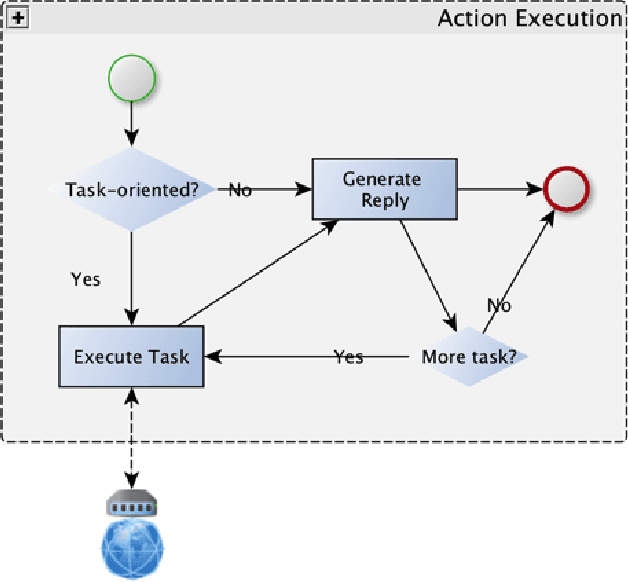
Multi-party Conversational Systems are systems with natural language interaction between one or more people or systems. From the moment that an utterance is sent to a group, to the moment that it is replied in the group by a member, several activities must be done by the system: utterance understanding, information search, reasoning, among others. In this paper we present the challenges of designing and building multi-party conversational systems, the state of the art, our proposed hybrid architecture using both rules and machine learning and some insights after implementing and evaluating one on the finance domain.