 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCarbon Figures of Merit Knowledge Creation with a Hybrid Solution and Carbon Tables API
May 18, 2022

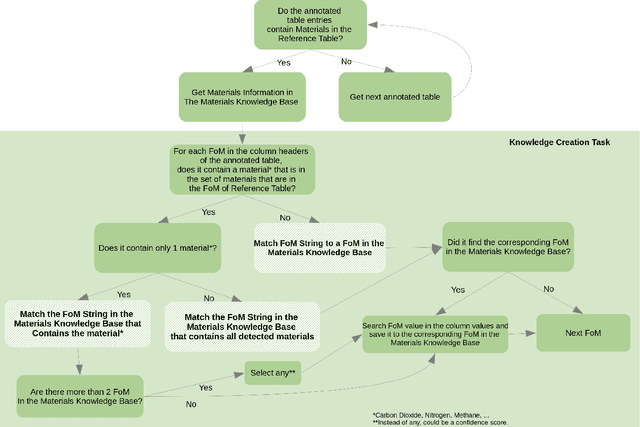

Nowadays there are algorithms, methods, and platforms that are being created to accelerate the discovery of materials that are able to absorb or adsorb $CO_2$ molecules that are in the atmosphere or during the combustion in power plants, for instance. In this work an asynchronous REST API is described to accelerate the creation of Carbon figures of merit knowledge, called Carbon Tables, because the knowledge is created from tables in scientific PDF documents and stored in knowledge graphs. The figures of merit knowledge creation solution uses a hybrid approach, in which heuristics and machine learning are part of. As a result, one can search the knowledge with mature and sophisticated cognitive tools, and create more with regards to Carbon figures of merit.
Using Meta-Knowledge Mined from Identifiers to Improve Intent Recognition in Neuro-Symbolic Algorithms
Dec 16, 2020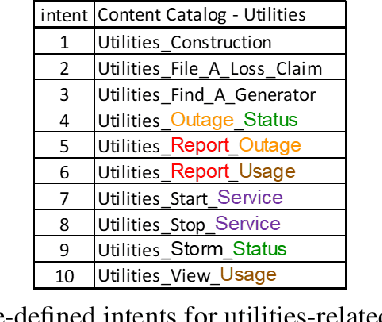
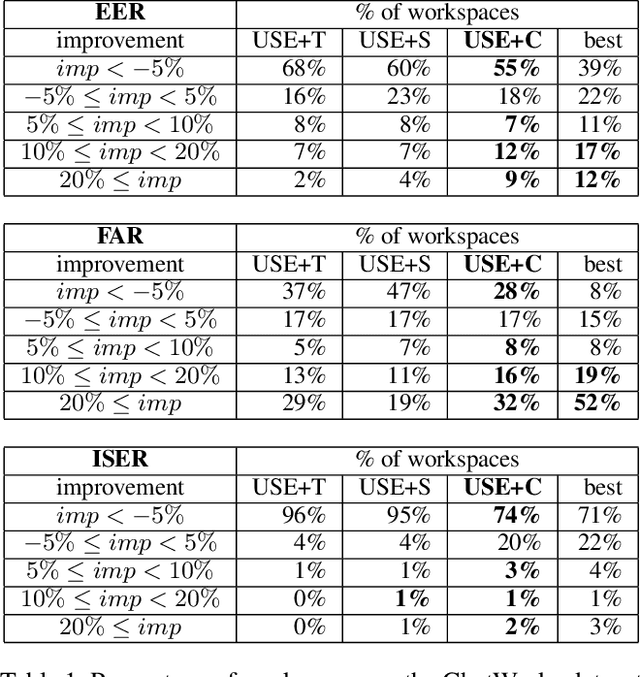
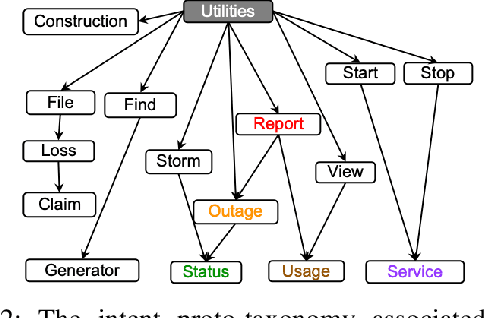
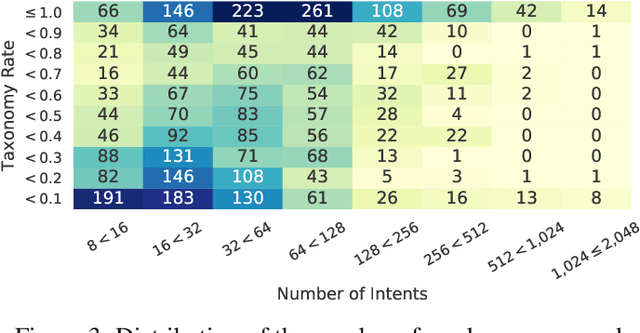
In this paper we explore the use of meta-knowledge embedded in intent identifiers to improve intent recognition in conversational systems. As evidenced by the analysis of thousands of real-world chatbots and in interviews with professional chatbot curators, developers and domain experts tend to organize the set of chatbot intents by identifying them using proto-taxonomies, i.e., meta-knowledge connecting high-level, symbolic concepts shared across different intents. By using neuro-symbolic algorithms able to incorporate such proto-taxonomies to expand intent representation, we show that such mined meta-knowledge can improve accuracy in intent recognition. In a dataset with intents and example utterances from hundreds of professional chatbots, we saw improvements of more than 10% in the equal error rate (EER) in almost a third of the chatbots when we apply those algorithms in comparison to a baseline of the same algorithms without the meta-knowledge. The meta-knowledge proved to be even more relevant in detecting out-of-scope utterances, decreasing the false acceptance rate (FAR) in more than 20\% in about half of the chatbots. The experiments demonstrate that such symbolic meta-knowledge structures can be effectively mined and used by neuro-symbolic algorithms, apparently by incorporating into the learning process higher-level structures of the problem being solved. Based on these results, we also discuss how the use of mined meta-knowledge can be an answer for the challenge of knowledge acquisition in neuro-symbolic algorithms.
A Hybrid Solution to Learn Turn-Taking in Multi-Party Service-based Chat Groups
Jan 14, 2020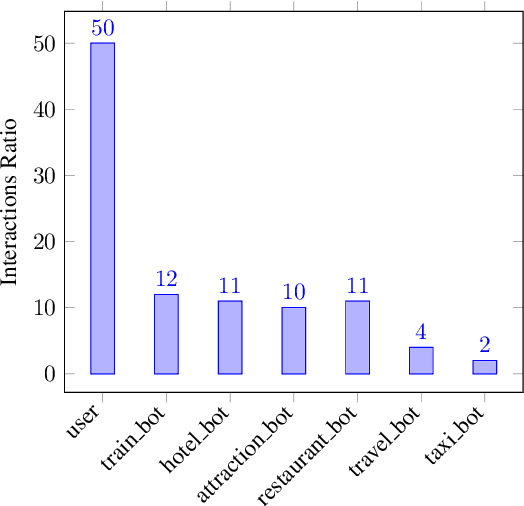
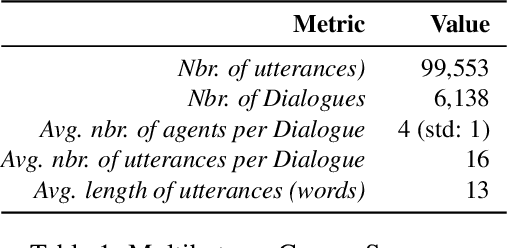
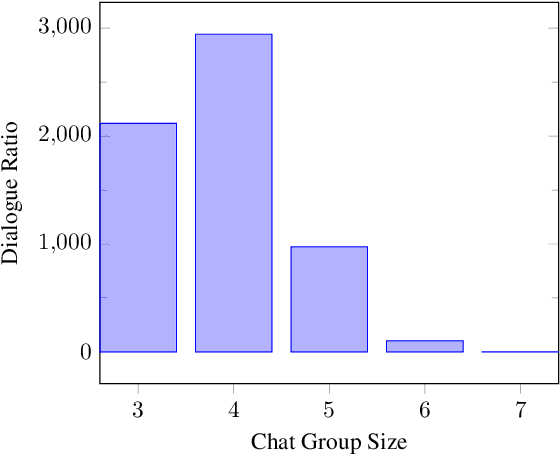

To predict the next most likely participant to interact in a multi-party conversation is a difficult problem. In a text-based chat group, the only information available is the sender, the content of the text and the dialogue history. In this paper we present our study on how these information can be used on the prediction task through a corpus and architecture that integrates turn-taking classifiers based on Maximum Likelihood Expectation (MLE), Convolutional Neural Networks (CNN) and Finite State Automata (FSA). The corpus is a synthetic adaptation of the Multi-Domain Wizard-of-Oz dataset (MultiWOZ) to a multiple travel service-based bots scenario with dialogue errors and was created to simulate user's interaction and evaluate the architecture. We present experimental results which show that the CNN approach achieves better performance than the baseline with an accuracy of 92.34%, but the integrated solution with MLE, CNN and FSA achieves performance even better, with 95.65%.
Learning Multi-Party Turn-Taking Models from Dialogue Logs
Jul 03, 2019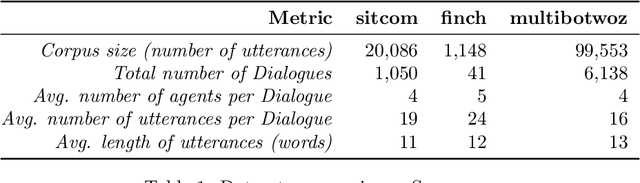

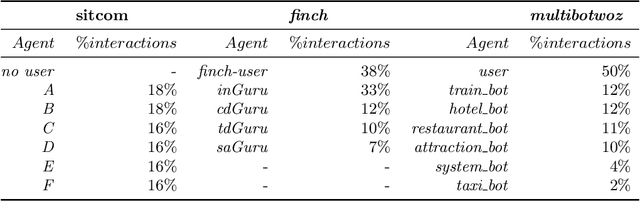
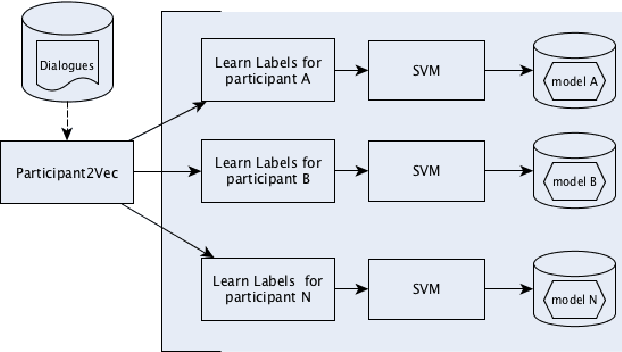
This paper investigates the application of machine learning (ML) techniques to enable intelligent systems to learn multi-party turn-taking models from dialogue logs. The specific ML task consists of determining who speaks next, after each utterance of a dialogue, given who has spoken and what was said in the previous utterances. With this goal, this paper presents comparisons of the accuracy of different ML techniques such as Maximum Likelihood Estimation (MLE), Support Vector Machines (SVM), and Convolutional Neural Networks (CNN) architectures, with and without utterance data. We present three corpora: the first with dialogues from an American TV situated comedy (chit-chat), the second with logs from a financial advice multi-bot system and the third with a corpus created from the Multi-Domain Wizard-of-Oz dataset (both are topic-oriented). The results show: (i) the size of the corpus has a very positive impact on the accuracy for the content-based deep learning approaches and those models perform best in the larger datasets; and (ii) if the dialogue dataset is small and topic-oriented (but with few topics), it is sufficient to use an agent-only MLE or SVM models, although slightly higher accuracies can be achieved with the use of the content of the utterances with a CNN model.
A Hybrid Architecture for Multi-Party Conversational Systems
May 04, 2017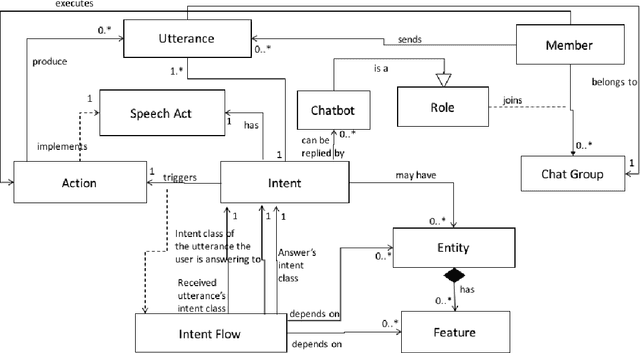
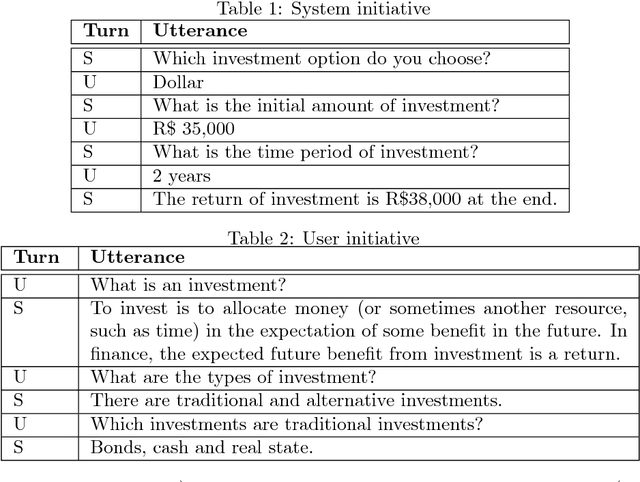
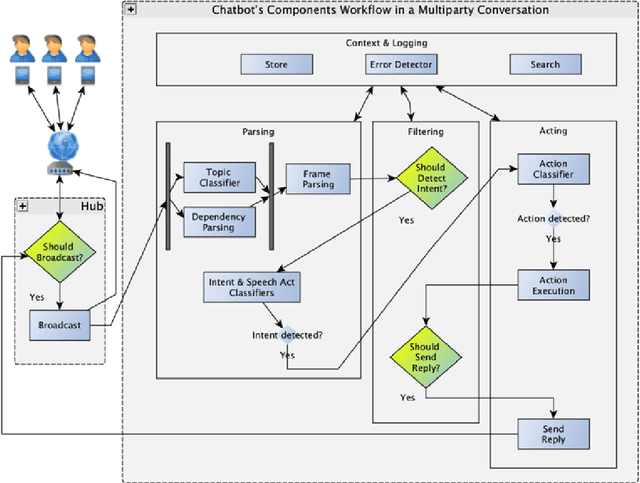
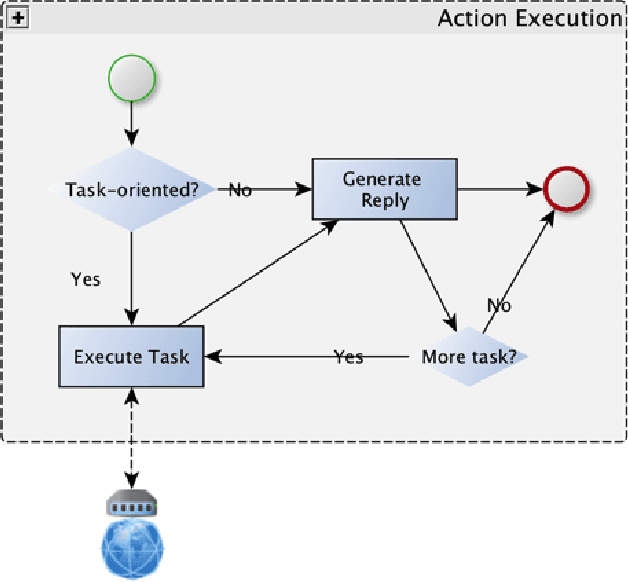
Multi-party Conversational Systems are systems with natural language interaction between one or more people or systems. From the moment that an utterance is sent to a group, to the moment that it is replied in the group by a member, several activities must be done by the system: utterance understanding, information search, reasoning, among others. In this paper we present the challenges of designing and building multi-party conversational systems, the state of the art, our proposed hybrid architecture using both rules and machine learning and some insights after implementing and evaluating one on the finance domain.