 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edgemiditok: A Python package for MIDI file tokenization
Oct 26, 2023
Recent progress in natural language processing has been adapted to the symbolic music modality. Language models, such as Transformers, have been used with symbolic music for a variety of tasks among which music generation, modeling or transcription, with state-of-the-art performances. These models are beginning to be used in production products. To encode and decode music for the backbone model, they need to rely on tokenizers, whose role is to serialize music into sequences of distinct elements called tokens. MidiTok is an open-source library allowing to tokenize symbolic music with great flexibility and extended features. It features the most popular music tokenizations, under a unified API. It is made to be easily used and extensible for everyone.
Impact of time and note duration tokenizations on deep learning symbolic music modeling
Oct 12, 2023



Symbolic music is widely used in various deep learning tasks, including generation, transcription, synthesis, and Music Information Retrieval (MIR). It is mostly employed with discrete models like Transformers, which require music to be tokenized, i.e., formatted into sequences of distinct elements called tokens. Tokenization can be performed in different ways. As Transformer can struggle at reasoning, but capture more easily explicit information, it is important to study how the way the information is represented for such model impact their performances. In this work, we analyze the common tokenization methods and experiment with time and note duration representations. We compare the performances of these two impactful criteria on several tasks, including composer and emotion classification, music generation, and sequence representation learning. We demonstrate that explicit information leads to better results depending on the task.
Byte Pair Encoding for Symbolic Music
Jan 27, 2023



The symbolic music modality is nowadays mostly represented as discrete and used with sequential models such as Transformers, for deep learning tasks. Recent research put efforts on the tokenization, i.e. the conversion of data into sequences of integers intelligible to such models. This can be achieved by many ways as music can be composed of simultaneous tracks, of simultaneous notes with several attributes. Until now, the proposed tokenizations are based on small vocabularies describing the note attributes and time events, resulting in fairly long token sequences. In this paper, we show how Byte Pair Encoding (BPE) can improve the results of deep learning models while improving its performances. We experiment on music generation and composer classification, and study the impact of BPE on how models learn the embeddings, and show that it can help to increase their isotropy, i.e., the uniformity of the variance of their positions in the space.
An adaptive music generation architecture for games based on the deep learning Transformer mode
Jul 04, 2022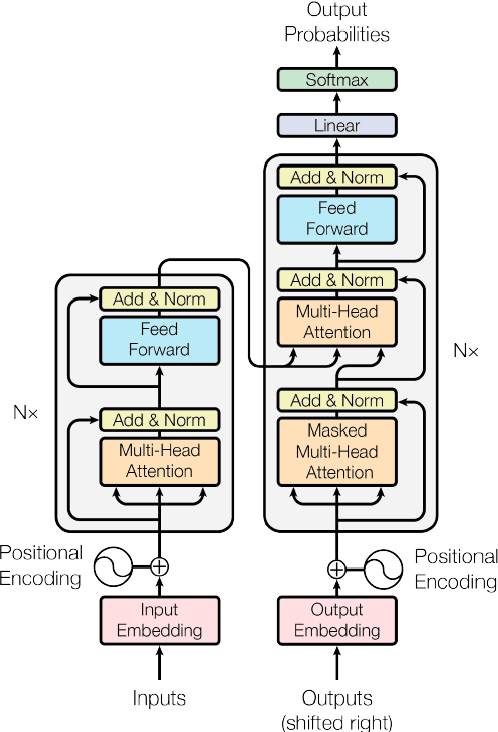
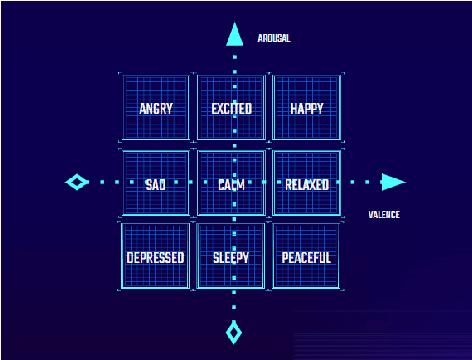
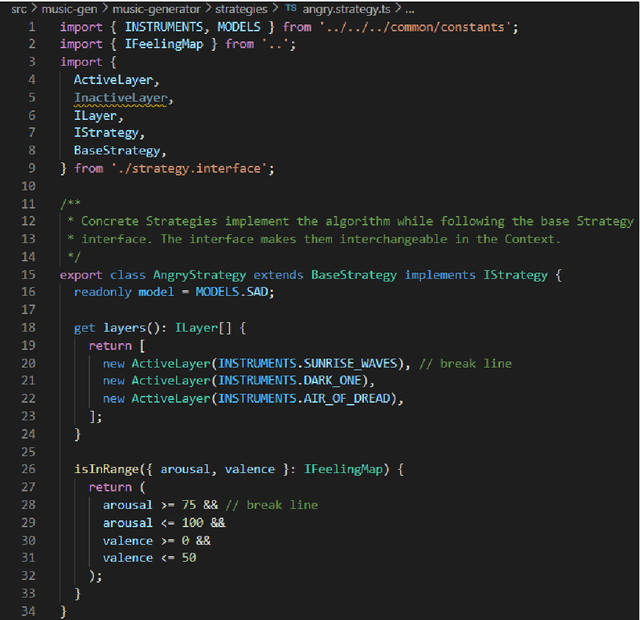
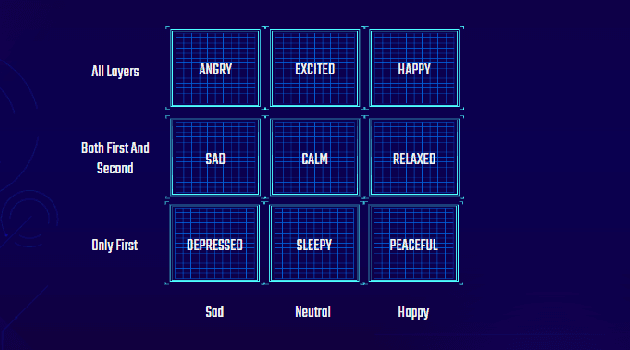
This paper presents an architecture for generating music for video games based on the Transformer deep learning model. The system generates music in various layers, following the standard layering strategy currently used by composers designing video game music. The music is adaptive to the psychological context of the player, according to the arousal-valence model. Our motivation is to customize music according to the player's tastes, who can select his preferred style of music through a set of training examples of music. We discuss current limitations and prospects for the future, such as collaborative and interactive control of the musical components.
From Procedures, Objects, Actors, Components, Services, to Agents -- A Comparative Analysis of the History and Evolution of Programming Abstractions
Jan 07, 2022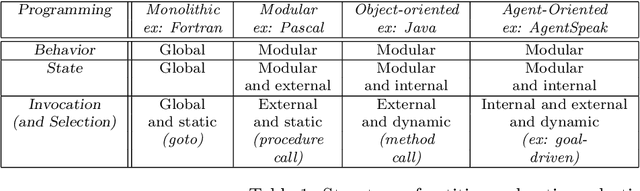
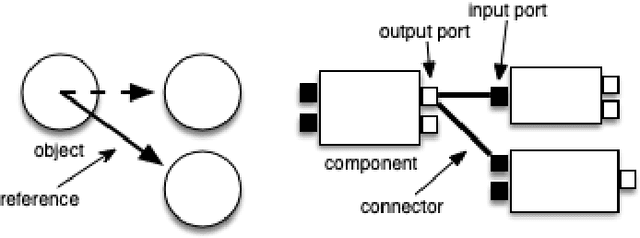
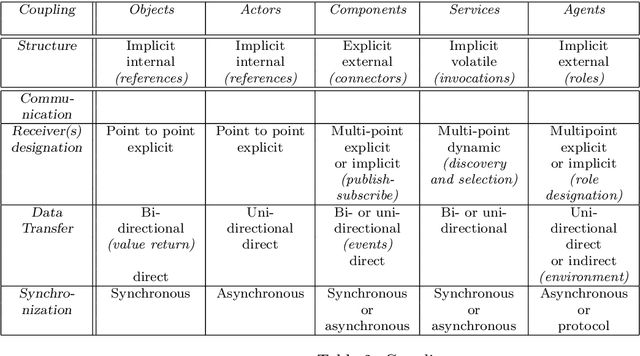
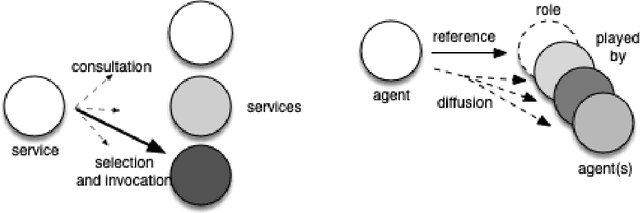
The objective of this chapter is to propose some retrospective analysis of the evolution of programming abstractions, from {\em procedures}, {\em objects}, {\em actors}, {\em components}, {\em services}, up to {\em agents}, %have some compare concepts of software component and of agent (and multi-agent system), %The method chosen is to by replacing them within a general historical perspective. Some common referential with three axes/dimensions is chosen: {\em action selection} at the level of one entity, {\em coupling flexibility} between entities, and {\em abstraction level}. We indeed may observe some continuous quest for higher flexibility (through notions such as {\em late binding}, or {\em reification} of {\em connections}) and higher level of {\em abstraction}. Concepts of components, services and agents have some common objectives (notably, {\em software modularity and reconfigurability}), with multi-agent systems raising further concepts of {\em autonomy} and {\em coordination}. notably through the notion of {\em auto-organization} and the use of {\em knowledge}. We hope that this analysis helps at highlighting some of the basic forces motivating the progress of programming abstractions and therefore that it may provide some seeds for the reflection about future programming abstractions.
Music Tempo Estimation via Neural Networks -- A Comparative Analysis
Jul 20, 2021
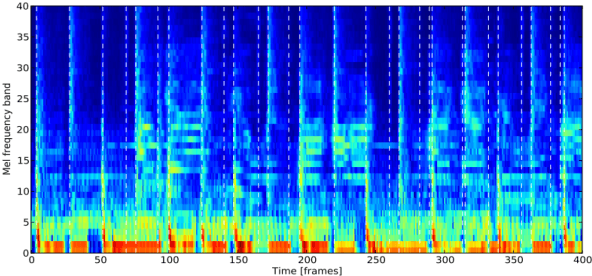
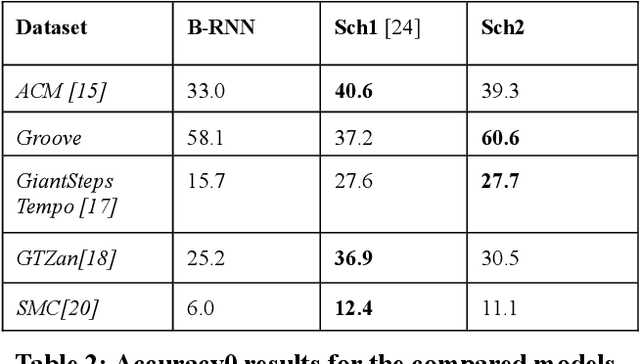
This paper presents a comparative analysis on two artificial neural networks (with different architectures) for the task of tempo estimation. For this purpose, it also proposes the modeling, training and evaluation of a B-RNN (Bidirectional Recurrent Neural Network) model capable of estimating tempo in bpm (beats per minutes) of musical pieces, without using external auxiliary modules. An extensive database (12,550 pieces in total) was curated to conduct a quantitative and qualitative analysis over the experiment. Percussion-only tracks were also included in the dataset. The performance of the B-RNN is compared to that of state-of-the-art models. For further comparison, a state-of-the-art CNN was also retrained with the same datasets used for the B-RNN training. Evaluation results for each model and datasets are presented and discussed, as well as observations and ideas for future research. Tempo estimation was more accurate for the percussion only dataset, suggesting that the estimation can be more accurate for percussion-only tracks, although further experiments (with more of such datasets) should be made to gather stronger evidence.
A Multi-Objective Approach for Sustainable Generative Audio Models
Jul 06, 2021



In recent years, the deep learning community has largely focused on the accuracy of deep generative models, resulting in impressive improvements in several research fields. However, this scientific race for quality comes at a tremendous computational cost, which incurs vast energy consumption and greenhouse gas emissions. If the current exponential growth of computational consumption persists, Artificial Intelligence (AI) will sadly become a considerable contributor to global warming. At the heart of this problem are the measures that we use as a scientific community to evaluate our work. Currently, researchers in the field of AI judge scientific works mostly based on the improvement in accuracy, log-likelihood, reconstruction or opinion scores, all of which entirely obliterates the actual computational cost of generative models. In this paper, we introduce the idea of relying on a multi-objective measure based on Pareto optimality, which simultaneously integrates the models accuracy, as well as the environmental impact of their training. By applying this measure on the current state-of-the-art in generative audio models, we show that this measure drastically changes the perceived significance of the results in the field, encouraging optimal training techniques and resource allocation. We hope that this type of measure will be widely adopted, in order to help the community to better evaluate the significance of their work, while bringing computational cost -- and in fine carbon emissions -- in the spotlight of AI research.
From Artificial Neural Networks to Deep Learning for Music Generation -- History, Concepts and Trends
Apr 07, 2020



The current tsunami of deep learning (the hyper-vitamined return of artificial neural networks) applies not only to traditional statistical machine learning tasks: prediction and classification (e.g., for weather prediction and pattern recognition), but has already conquered other areas, such as translation. A growing area of application is the generation of creative content: in particular the case of music, the topic of this paper. The motivation is in using the capacity of modern deep learning techniques to automatically learn musical styles from arbitrary musical corpora and then to generate musical samples from the estimated distribution, with some degree of control over the generation. This article provides a survey of music generation based on deep learning techniques. After a short introduction to the topic illustrated by a recent exemple, the article analyses some early works from the late 1980s using artificial neural networks for music generation and how their pioneering contributions foreshadowed current techniques. Then, we introduce some conceptual framework to analyze the various concepts and dimensions involved. Various examples of recent systems are introduced and analyzed to illustrate the variety of concerns and of techniques.
Music Generation by Deep Learning - Challenges and Directions
Sep 30, 2018

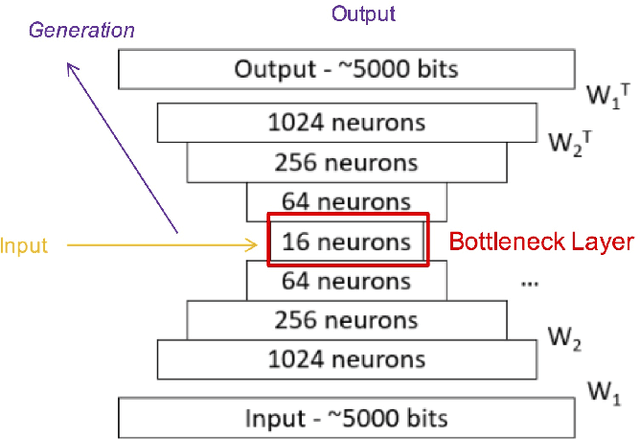
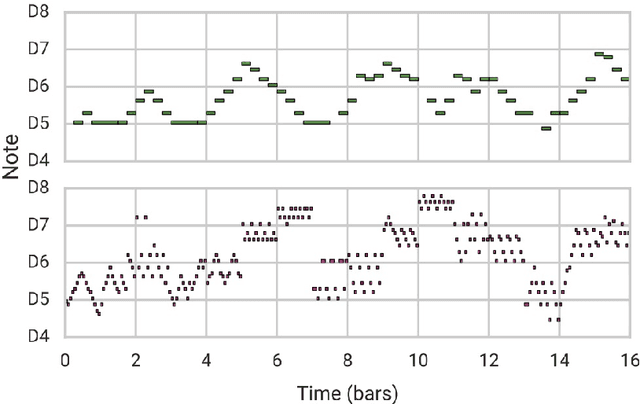
In addition to traditional tasks such as prediction, classification and translation, deep learning is receiving growing attention as an approach for music generation, as witnessed by recent research groups such as Magenta at Google and CTRL (Creator Technology Research Lab) at Spotify. The motivation is in using the capacity of deep learning architectures and training techniques to automatically learn musical styles from arbitrary musical corpora and then to generate samples from the estimated distribution. However, a direct application of deep learning to generate content rapidly reaches limits as the generated content tends to mimic the training set without exhibiting true creativity. Moreover, deep learning architectures do not offer direct ways for controlling generation (e.g., imposing some tonality or other arbitrary constraints). Furthermore, deep learning architectures alone are autistic automata which generate music autonomously without human user interaction, far from the objective of interactively assisting musicians to compose and refine music. Issues such as: control, structure, creativity and interactivity are the focus of our analysis. In this paper, we select some limitations of a direct application of deep learning to music generation, analyze why the issues are not fulfilled and how to address them by possible approaches. Various examples of recent systems are cited as examples of promising directions.
Deep Learning Techniques for Music Generation - A Survey
Sep 05, 2017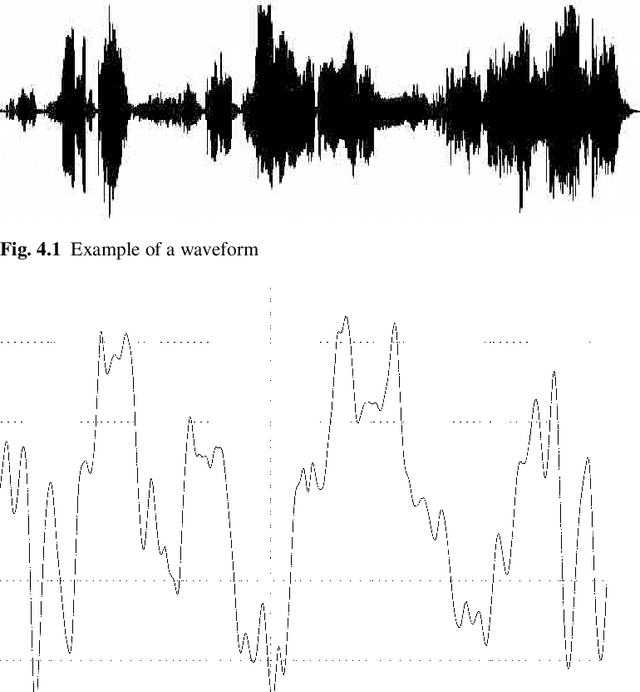

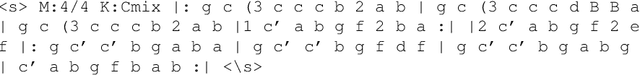

This book is a survey and an analysis of different ways of using deep learning (deep artificial neural networks) to generate musical content. At first, we propose a methodology based on four dimensions for our analysis: - objective - What musical content is to be generated? (e.g., melody, accompaniment...); - representation - What are the information formats used for the corpus and for the expected generated output? (e.g., MIDI, piano roll, text...); - architecture - What type of deep neural network is to be used? (e.g., recurrent network, autoencoder, generative adversarial networks...); - strategy - How to model and control the process of generation (e.g., direct feedforward, sampling, unit selection...). For each dimension, we conduct a comparative analysis of various models and techniques. For the strategy dimension, we propose some tentative typology of possible approaches and mechanisms. This classification is bottom-up, based on the analysis of many existing deep-learning based systems for music generation, which are described in this book. The last part of the book includes discussion and prospects.