 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTonal parsimony in chord-sequence analysis: combining modulation cost and tonal vocabulary
Jun 02, 2026We study the assignment of local tonalities to chord sequences, a task useful for harmonic analysis, composition, and jazz-oriented improvisation. Standard dynamic-programming approaches minimize modulations but can introduce unnecessarily many tonal centers. We compare this transition-only objective with pure minimum-vocabulary analysis and with tonal parsimony, which minimizes lexicographically the number of modulations and then the number of distinct tonalities. Although this joint objective is combinatorially hard in general, we give exact algorithms exploiting the fixed 24-tonality major/minor universe. On 31,032 LMD Chords sequences, tonal parsimony preserves the transition optimum while reducing tonal vocabulary in 55.8% of cases. With weighted jazz-substitution closure, it lowers mean tonalities from 3.802 to 3.206 and modulations from 16.728 to 12.141. On 1,555 annotated jazz standards, it improves compatible chord-scale agreement to 95.6%, supporting tractable professional-scale harmonic analysis.
Maximum Entropy Relaxation of Multi-Way Cardinality Constraints for Synthetic Population Generation
Mar 23, 2026Generating synthetic populations from aggregate statistics is a core component of microsimulation, agent-based modeling, policy analysis, and privacy-preserving data release. Beyond classical census marginals, many applications require matching heterogeneous unary, binary, and ternary constraints derived from surveys, expert knowledge, or automatically extracted descriptions. Constructing populations that satisfy such multi-way constraints simultaneously poses a significant computational challenge. We consider populations where each individual is described by categorical attributes and the target is a collection of global frequency constraints over attribute combinations. Exact formulations scale poorly as the number and arity of constraints increase, especially when the constraints are numerous and overlapping. Grounded in methods from statistical physics, we propose a maximum-entropy relaxation of this problem. Multi-way cardinality constraints are matched in expectation rather than exactly, yielding an exponential-family distribution over complete population assignments and a convex optimization problem over Lagrange multipliers. We evaluate the approach on NPORS-derived scaling benchmarks with 4 to 40 attributes and compare it primarily against generalized raking. The results show that MaxEnt becomes increasingly advantageous as the number of attributes and ternary interactions grows, while raking remains competitive on smaller, lower-arity instances.
Assisted music creation with Flow Machines: towards new categories of new
Jun 22, 2020



This chapter reflects on about 10 years of research in AI- assisted music composition, in particular during the Flow Machines project. We reflect on the motivations for such a project, its background, its main results and impact, both technological and musical, several years after its completion. We conclude with a proposal for new categories of new, created by the many uses of AI techniques to generate novel material.
Music Generation by Deep Learning - Challenges and Directions
Sep 30, 2018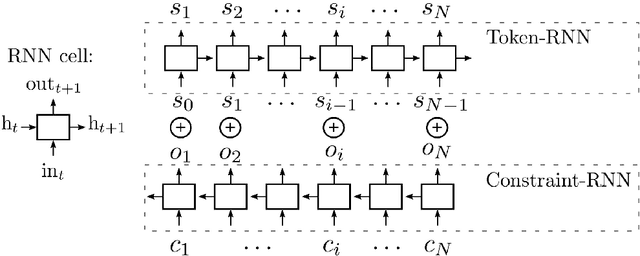

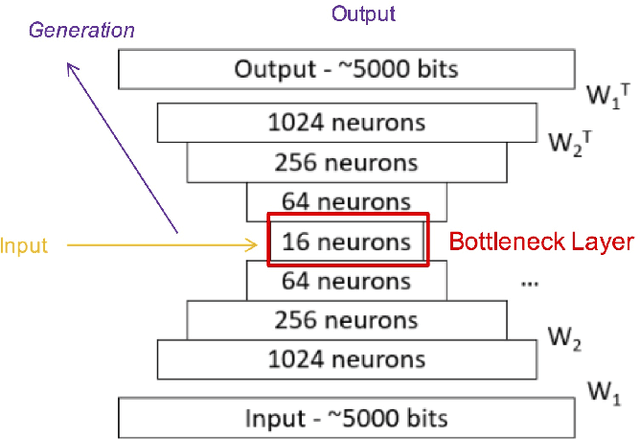
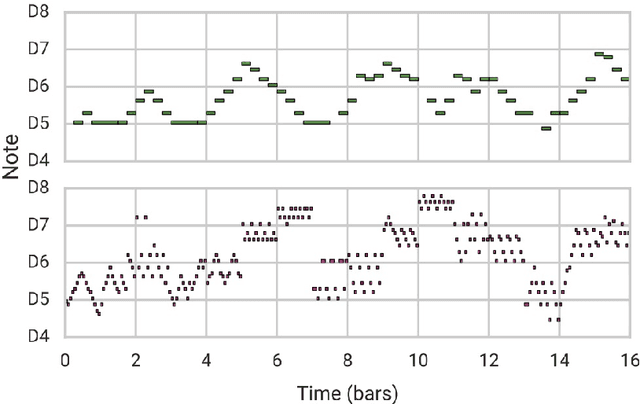
In addition to traditional tasks such as prediction, classification and translation, deep learning is receiving growing attention as an approach for music generation, as witnessed by recent research groups such as Magenta at Google and CTRL (Creator Technology Research Lab) at Spotify. The motivation is in using the capacity of deep learning architectures and training techniques to automatically learn musical styles from arbitrary musical corpora and then to generate samples from the estimated distribution. However, a direct application of deep learning to generate content rapidly reaches limits as the generated content tends to mimic the training set without exhibiting true creativity. Moreover, deep learning architectures do not offer direct ways for controlling generation (e.g., imposing some tonality or other arbitrary constraints). Furthermore, deep learning architectures alone are autistic automata which generate music autonomously without human user interaction, far from the objective of interactively assisting musicians to compose and refine music. Issues such as: control, structure, creativity and interactivity are the focus of our analysis. In this paper, we select some limitations of a direct application of deep learning to music generation, analyze why the issues are not fulfilled and how to address them by possible approaches. Various examples of recent systems are cited as examples of promising directions.
Deep Learning Techniques for Music Generation - A Survey
Sep 05, 2017

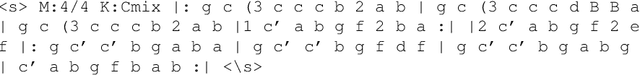

This book is a survey and an analysis of different ways of using deep learning (deep artificial neural networks) to generate musical content. At first, we propose a methodology based on four dimensions for our analysis: - objective - What musical content is to be generated? (e.g., melody, accompaniment...); - representation - What are the information formats used for the corpus and for the expected generated output? (e.g., MIDI, piano roll, text...); - architecture - What type of deep neural network is to be used? (e.g., recurrent network, autoencoder, generative adversarial networks...); - strategy - How to model and control the process of generation (e.g., direct feedforward, sampling, unit selection...). For each dimension, we conduct a comparative analysis of various models and techniques. For the strategy dimension, we propose some tentative typology of possible approaches and mechanisms. This classification is bottom-up, based on the analysis of many existing deep-learning based systems for music generation, which are described in this book. The last part of the book includes discussion and prospects.
GLSR-VAE: Geodesic Latent Space Regularization for Variational AutoEncoder Architectures
Jul 14, 2017
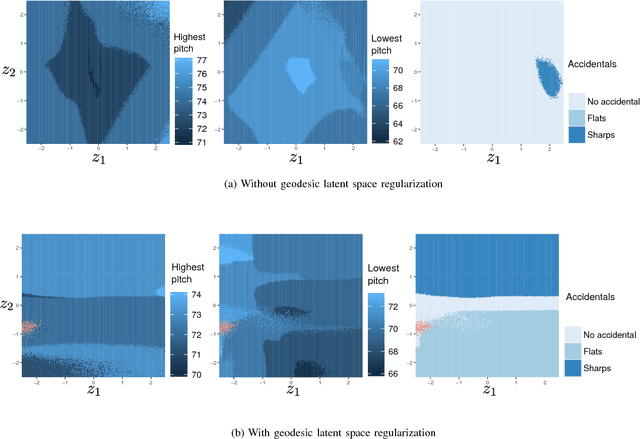
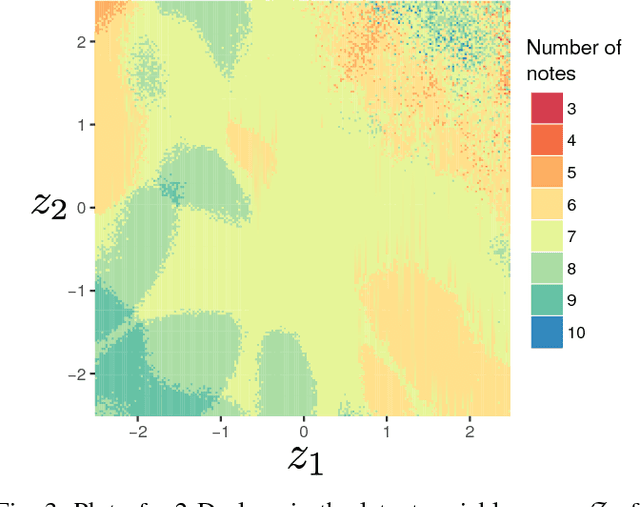
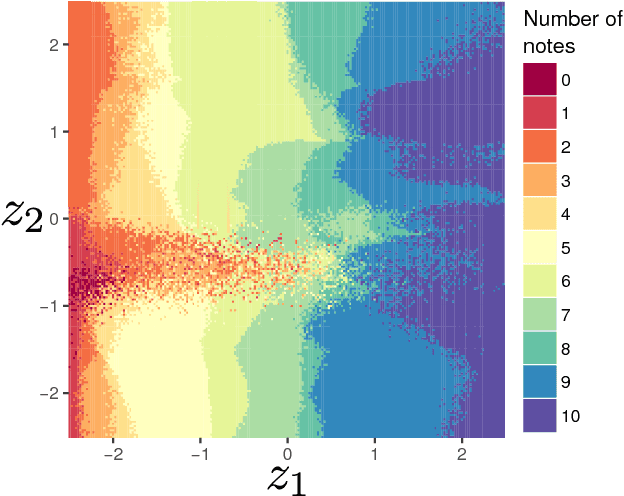
VAEs (Variational AutoEncoders) have proved to be powerful in the context of density modeling and have been used in a variety of contexts for creative purposes. In many settings, the data we model possesses continuous attributes that we would like to take into account at generation time. We propose in this paper GLSR-VAE, a Geodesic Latent Space Regularization for the Variational AutoEncoder architecture and its generalizations which allows a fine control on the embedding of the data into the latent space. When augmenting the VAE loss with this regularization, changes in the learned latent space reflects changes of the attributes of the data. This deeper understanding of the VAE latent space structure offers the possibility to modulate the attributes of the generated data in a continuous way. We demonstrate its efficiency on a monophonic music generation task where we manage to generate variations of discrete sequences in an intended and playful way.
DeepBach: a Steerable Model for Bach Chorales Generation
Jun 17, 2017

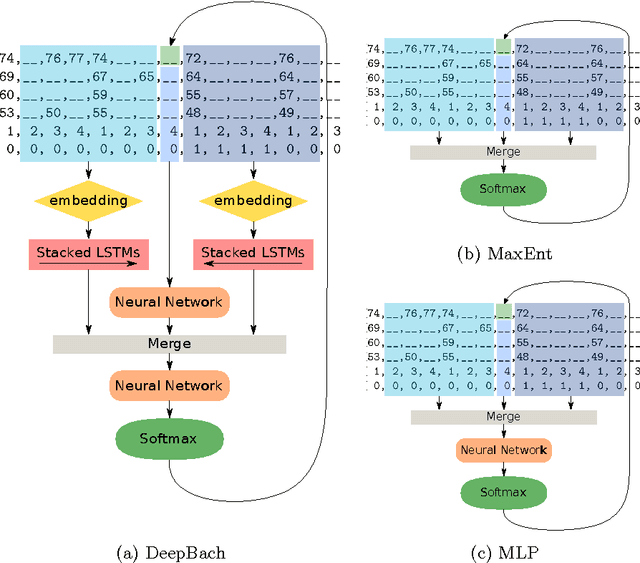
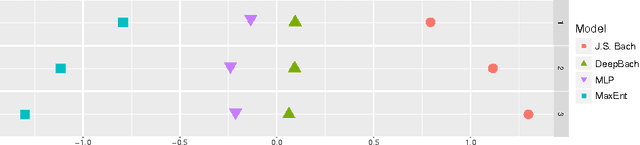
This paper introduces DeepBach, a graphical model aimed at modeling polyphonic music and specifically hymn-like pieces. We claim that, after being trained on the chorale harmonizations by Johann Sebastian Bach, our model is capable of generating highly convincing chorales in the style of Bach. DeepBach's strength comes from the use of pseudo-Gibbs sampling coupled with an adapted representation of musical data. This is in contrast with many automatic music composition approaches which tend to compose music sequentially. Our model is also steerable in the sense that a user can constrain the generation by imposing positional constraints such as notes, rhythms or cadences in the generated score. We also provide a plugin on top of the MuseScore music editor making the interaction with DeepBach easy to use.
* 10 pages, ICML2017 version
Sampling Variations of Lead Sheets
Mar 02, 2017
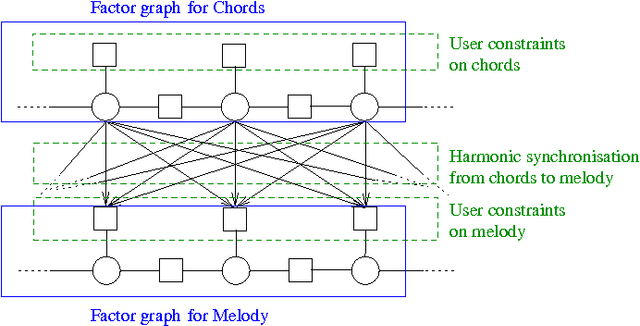
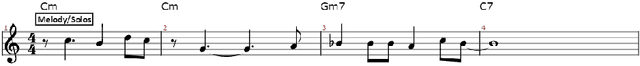
Machine-learning techniques have been recently used with spectacular results to generate artefacts such as music or text. However, these techniques are still unable to capture and generate artefacts that are convincingly structured. In this paper we present an approach to generate structured musical sequences. We introduce a mechanism for sampling efficiently variations of musical sequences. Given a input sequence and a statistical model, this mechanism samples a set of sequences whose distance to the input sequence is approximately within specified bounds. This mechanism is implemented as an extension of belief propagation, and uses local fields to bias the generation. We show experimentally that sampled sequences are indeed closely correlated to the standard musical similarity measure defined by Mongeau and Sankoff. We then show how this mechanism can used to implement composition strategies that enforce arbitrary structure on a musical lead sheet generation problem.
Maximum entropy models for generation of expressive music
Oct 12, 2016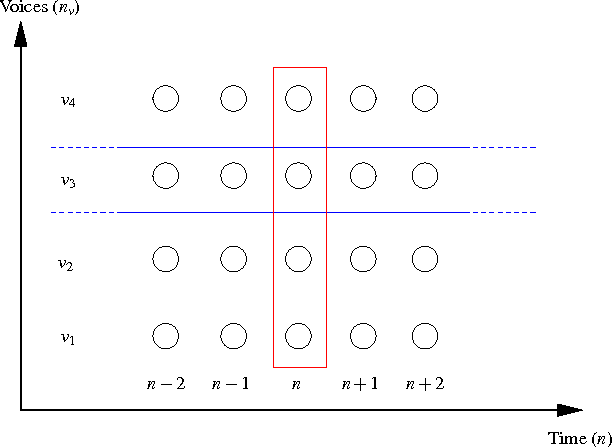
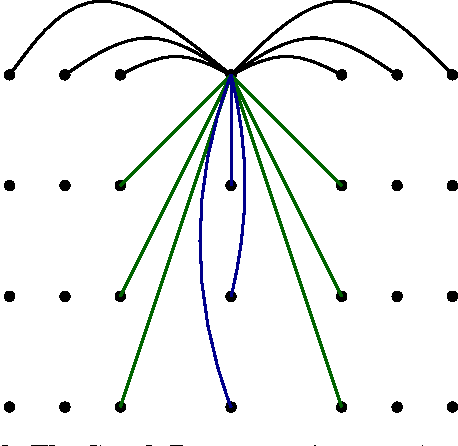
In the context of contemporary monophonic music, expression can be seen as the difference between a musical performance and its symbolic representation, i.e. a musical score. In this paper, we show how Maximum Entropy (MaxEnt) models can be used to generate musical expression in order to mimic a human performance. As a training corpus, we had a professional pianist play about 150 melodies of jazz, pop, and latin jazz. The results show a good predictive power, validating the choice of our model. Additionally, we set up a listening test whose results reveal that on average, people significantly prefer the melodies generated by the MaxEnt model than the ones without any expression, or with fully random expression. Furthermore, in some cases, MaxEnt melodies are almost as popular as the human performed ones.
Maximum entropy models capture melodic styles
Oct 11, 2016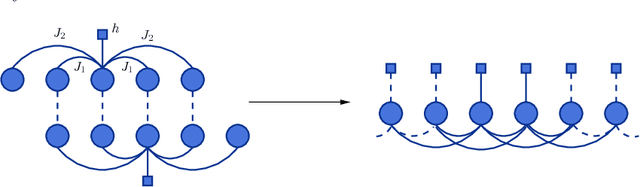
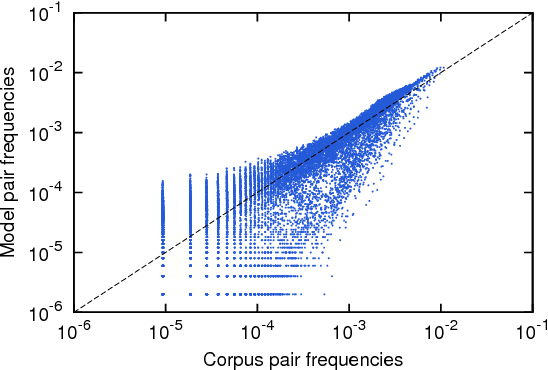
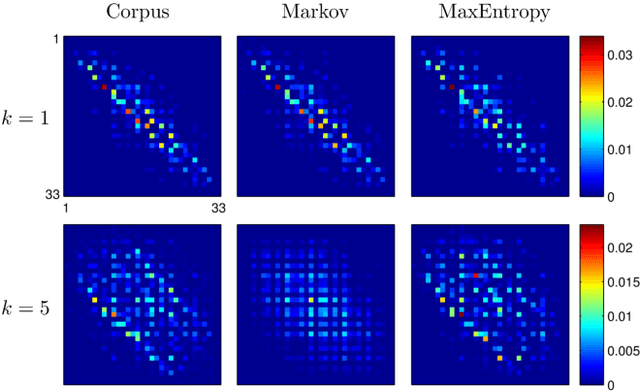
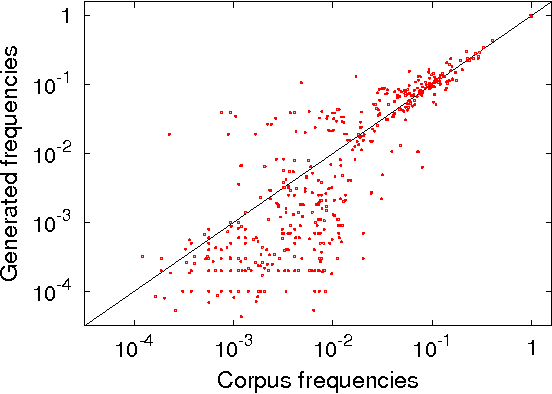
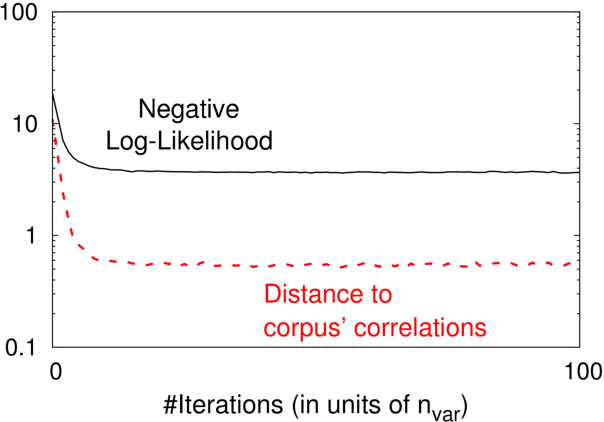
We introduce a Maximum Entropy model able to capture the statistics of melodies in music. The model can be used to generate new melodies that emulate the style of the musical corpus which was used to train it. Instead of using the $n-$body interactions of $(n-1)-$order Markov models, traditionally used in automatic music generation, we use a $k-$nearest neighbour model with pairwise interactions only. In that way, we keep the number of parameters low and avoid over-fitting problems typical of Markov models. We show that long-range musical phrases don't need to be explicitly enforced using high-order Markov interactions, but can instead emerge from multiple, competing, pairwise interactions. We validate our Maximum Entropy model by contrasting how much the generated sequences capture the style of the original corpus without plagiarizing it. To this end we use a data-compression approach to discriminate the levels of borrowing and innovation featured by the artificial sequences. The results show that our modelling scheme outperforms both fixed-order and variable-order Markov models. This shows that, despite being based only on pairwise interactions, this Maximum Entropy scheme opens the possibility to generate musically sensible alterations of the original phrases, providing a way to generate innovation.