 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMaximum entropy models capture melodic styles
Paper and Code
Oct 11, 2016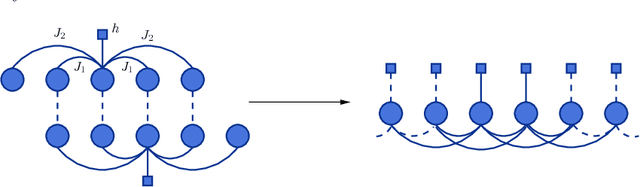
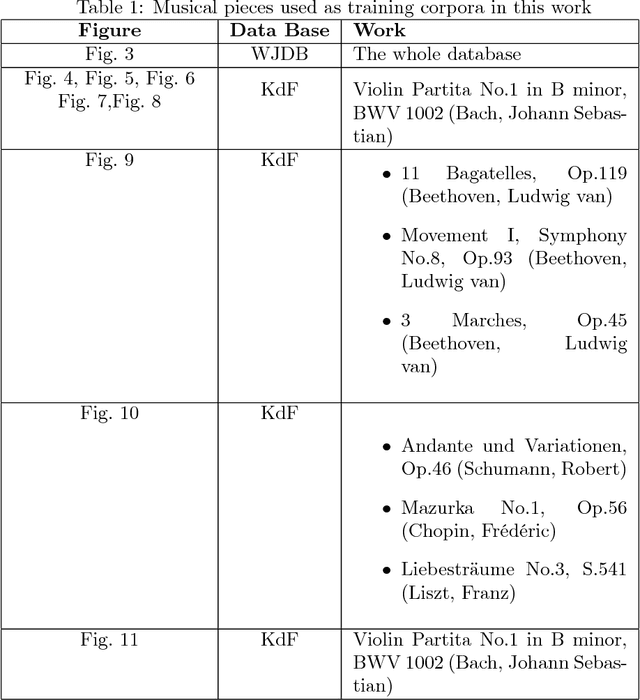
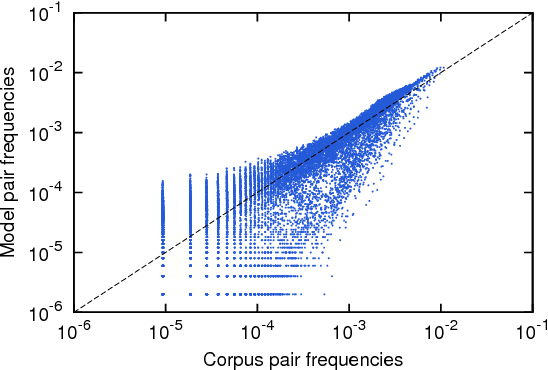
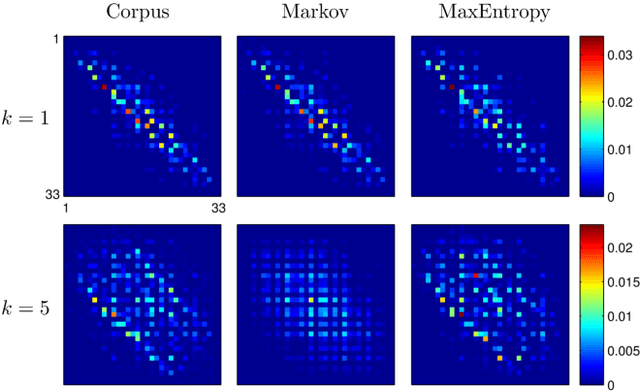
We introduce a Maximum Entropy model able to capture the statistics of melodies in music. The model can be used to generate new melodies that emulate the style of the musical corpus which was used to train it. Instead of using the $n-$body interactions of $(n-1)-$order Markov models, traditionally used in automatic music generation, we use a $k-$nearest neighbour model with pairwise interactions only. In that way, we keep the number of parameters low and avoid over-fitting problems typical of Markov models. We show that long-range musical phrases don't need to be explicitly enforced using high-order Markov interactions, but can instead emerge from multiple, competing, pairwise interactions. We validate our Maximum Entropy model by contrasting how much the generated sequences capture the style of the original corpus without plagiarizing it. To this end we use a data-compression approach to discriminate the levels of borrowing and innovation featured by the artificial sequences. The results show that our modelling scheme outperforms both fixed-order and variable-order Markov models. This shows that, despite being based only on pairwise interactions, this Maximum Entropy scheme opens the possibility to generate musically sensible alterations of the original phrases, providing a way to generate innovation.