 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMaximum entropy models capture melodic styles
Oct 11, 2016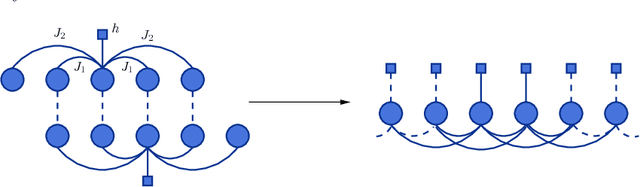
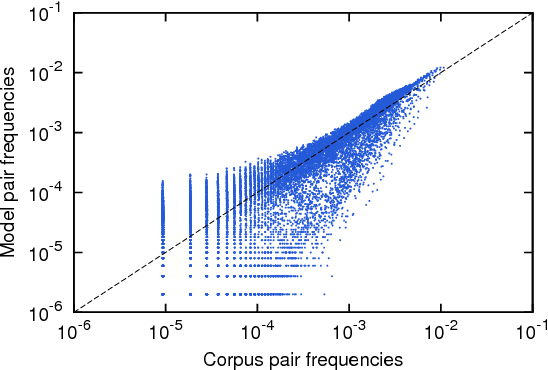
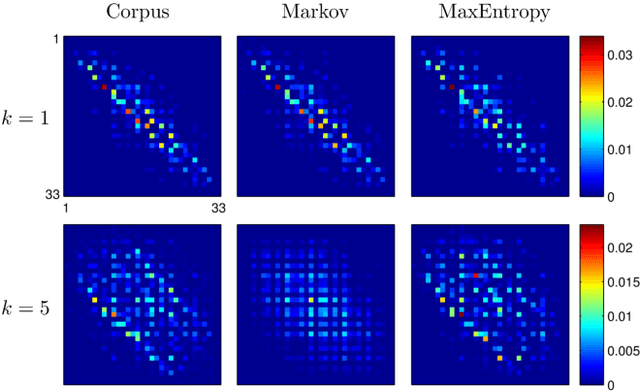
We introduce a Maximum Entropy model able to capture the statistics of melodies in music. The model can be used to generate new melodies that emulate the style of the musical corpus which was used to train it. Instead of using the $n-$body interactions of $(n-1)-$order Markov models, traditionally used in automatic music generation, we use a $k-$nearest neighbour model with pairwise interactions only. In that way, we keep the number of parameters low and avoid over-fitting problems typical of Markov models. We show that long-range musical phrases don't need to be explicitly enforced using high-order Markov interactions, but can instead emerge from multiple, competing, pairwise interactions. We validate our Maximum Entropy model by contrasting how much the generated sequences capture the style of the original corpus without plagiarizing it. To this end we use a data-compression approach to discriminate the levels of borrowing and innovation featured by the artificial sequences. The results show that our modelling scheme outperforms both fixed-order and variable-order Markov models. This shows that, despite being based only on pairwise interactions, this Maximum Entropy scheme opens the possibility to generate musically sensible alterations of the original phrases, providing a way to generate innovation.
On the emergence of syntactic structures: quantifying and modelling duality of patterning
Feb 11, 2016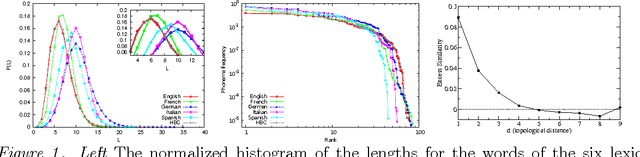
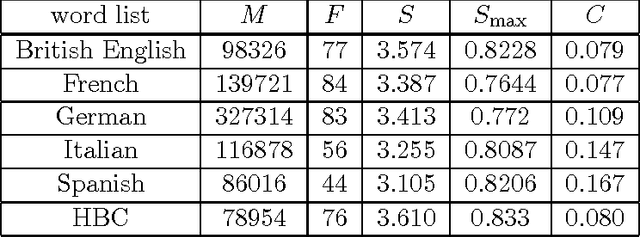
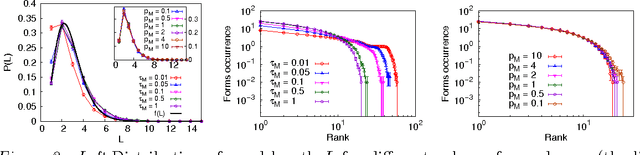

The complex organization of syntax in hierarchical structures is one of the core design features of human language. Duality of patterning refers for instance to the organization of the meaningful elements in a language at two distinct levels: a combinatorial level where meaningless forms are combined into meaningful forms and a compositional level where meaningful forms are composed into larger lexical units. The question remains wide open regarding how such a structure could have emerged. Furthermore a clear mathematical framework to quantify this phenomenon is still lacking. The aim of this paper is that of addressing these two aspects in a self-consistent way. First, we introduce suitable measures to quantify the level of combinatoriality and compositionality in a language, and present a framework to estimate these observables in human natural languages. Second, we show that the theoretical predictions of a multi-agents modeling scheme, namely the Blending Game, are in surprisingly good agreement with empirical data. In the Blending Game a population of individuals plays language games aiming at success in communication. It is remarkable that the two sides of duality of patterning emerge simultaneously as a consequence of a pure cultural dynamics in a simulated environment that contains meaningful relations, provided a simple constraint on message transmission fidelity is also considered.
Internal and external dynamics in language: Evidence from verb regularity in a historical corpus of English
Aug 12, 2014



Human languages are rule governed, but almost invariably these rules have exceptions in the form of irregularities. Since rules in language are efficient and productive, the persistence of irregularity is an anomaly. How does irregularity linger in the face of internal (endogenous) and external (exogenous) pressures to conform to a rule? Here we address this problem by taking a detailed look at simple past tense verbs in the Corpus of Historical American English. The data show that the language is open, with many new verbs entering. At the same time, existing verbs might tend to regularize or irregularize as a consequence of internal dynamics, but overall, the amount of irregularity sustained by the language stays roughly constant over time. Despite continuous vocabulary growth, and presumably, an attendant increase in expressive power, there is no corresponding growth in irregularity. We analyze the set of irregulars, showing they may adhere to a set of minority rules, allowing for increased stability of irregularity over time. These findings contribute to the debate on how language systems become rule governed, and how and why they sustain exceptions to rules, providing insight into the interplay between the emergence and maintenance of rules and exceptions in language.
* 12 page, 4 figures + Supporting Information (18 pages)
On the accuracy of language trees
Mar 21, 2011



Historical linguistics aims at inferring the most likely language phylogenetic tree starting from information concerning the evolutionary relatedness of languages. The available information are typically lists of homologous (lexical, phonological, syntactic) features or characters for many different languages. From this perspective the reconstruction of language trees is an example of inverse problems: starting from present, incomplete and often noisy, information, one aims at inferring the most likely past evolutionary history. A fundamental issue in inverse problems is the evaluation of the inference made. A standard way of dealing with this question is to generate data with artificial models in order to have full access to the evolutionary process one is going to infer. This procedure presents an intrinsic limitation: when dealing with real data sets, one typically does not know which model of evolution is the most suitable for them. A possible way out is to compare algorithmic inference with expert classifications. This is the point of view we take here by conducting a thorough survey of the accuracy of reconstruction methods as compared with the Ethnologue expert classifications. We focus in particular on state-of-the-art distance-based methods for phylogeny reconstruction using worldwide linguistic databases. In order to assess the accuracy of the inferred trees we introduce and characterize two generalizations of standard definitions of distances between trees. Based on these scores we quantify the relative performances of the distance-based algorithms considered. Further we quantify how the completeness and the coverage of the available databases affect the accuracy of the reconstruction. Finally we draw some conclusions about where the accuracy of the reconstructions in historical linguistics stands and about the leading directions to improve it.
Aging in language dynamics
Jan 14, 2011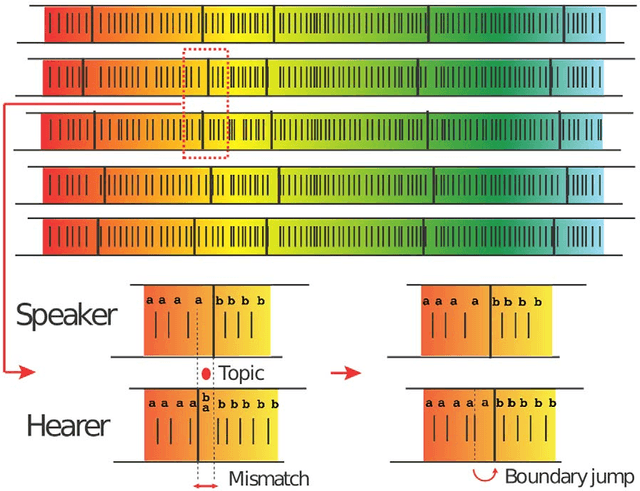
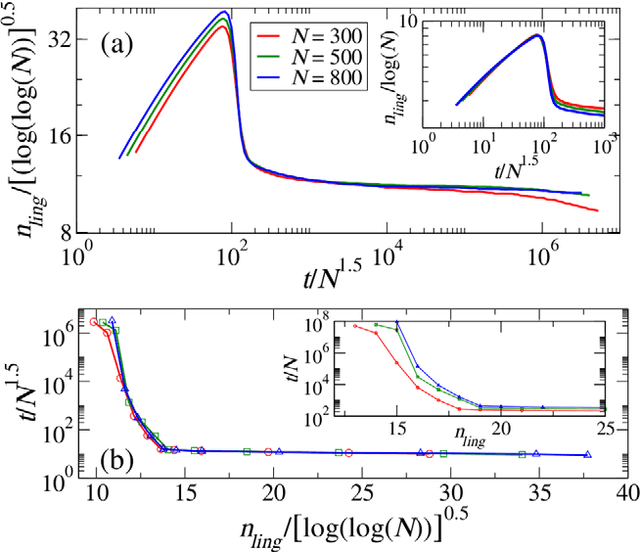
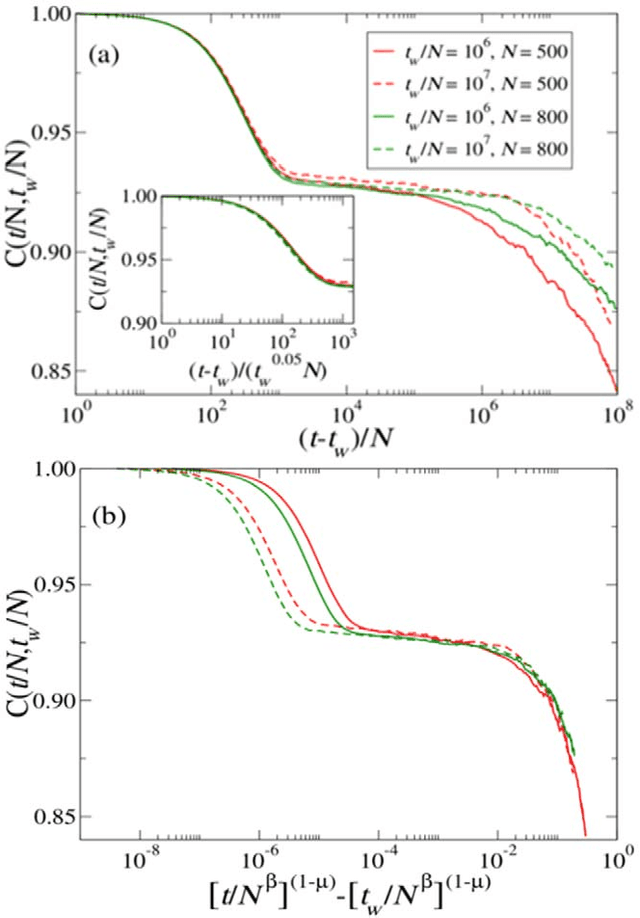

Human languages evolve continuously, and a puzzling problem is how to reconcile the apparent robustness of most of the deep linguistic structures we use with the evidence that they undergo possibly slow, yet ceaseless, changes. Is the state in which we observe languages today closer to what would be a dynamical attractor with statistically stationary properties or rather closer to a non-steady state slowly evolving in time? Here we address this question in the framework of the emergence of shared linguistic categories in a population of individuals interacting through language games. The observed emerging asymptotic categorization, which has been previously tested - with success - against experimental data from human languages, corresponds to a metastable state where global shifts are always possible but progressively more unlikely and the response properties depend on the age of the system. This aging mechanism exhibits striking quantitative analogies to what is observed in the statistical mechanics of glassy systems. We argue that this can be a general scenario in language dynamics where shared linguistic conventions would not emerge as attractors, but rather as metastable states.
* 15 pages, 6 figures. Accepted for publication in PLoS ONE