 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInverting Self-Organizing Maps: A Unified Activation-Based Framework
Jan 20, 2026Self-Organizing Maps provide topology-preserving projections of high-dimensional data and have been widely used for visualization, clustering, and vector quantization. In this work, we show that the activation pattern of a SOM - the squared distances to its prototypes - can be inverted to recover the exact input under mild geometric conditions. This follows from a classical fact in Euclidean distance geometry: a point in $D$ dimensions is uniquely determined by its distances to $D{+}1$ affinely independent references. We derive the corresponding linear system and characterize the conditions under which the inversion is well-posed. Building upon this mechanism, we introduce the Manifold-Aware Unified SOM Inversion and Control (MUSIC) update rule, which enables controlled, semantically meaningful trajectories in latent space. MUSIC modifies squared distances to selected prototypes while preserving others, resulting in a deterministic geometric flow aligned with the SOM's piecewise-linear structure. Tikhonov regularization stabilizes the update rule and ensures smooth motion on high-dimensional datasets. Unlike variational or probabilistic generative models, MUSIC does not rely on sampling, latent priors, or encoder-decoder architectures. If no perturbation is applied, inversion recovers the exact input; when a target cluster or prototype is specified, MUSIC produces coherent semantic variations while remaining on the data manifold. This leads to a new perspective on data augmentation and controllable latent exploration based solely on prototype geometry. We validate the approach using synthetic Gaussian mixtures, the MNIST and the Faces in the Wild dataset. Across all settings, MUSIC produces smooth, interpretable trajectories that reveal the underlying geometry of the learned manifold, illustrating the advantages of SOM-based inversion over unsupervised clustering.
Lyapunov Learning at the Onset of Chaos
Jun 15, 2025Handling regime shifts and non-stationary time series in deep learning systems presents a significant challenge. In the case of online learning, when new information is introduced, it can disrupt previously stored data and alter the model's overall paradigm, especially with non-stationary data sources. Therefore, it is crucial for neural systems to quickly adapt to new paradigms while preserving essential past knowledge relevant to the overall problem. In this paper, we propose a novel training algorithm for neural networks called \textit{Lyapunov Learning}. This approach leverages the properties of nonlinear chaotic dynamical systems to prepare the model for potential regime shifts. Drawing inspiration from Stuart Kauffman's Adjacent Possible theory, we leverage local unexplored regions of the solution space to enable flexible adaptation. The neural network is designed to operate at the edge of chaos, where the maximum Lyapunov exponent, indicative of a system's sensitivity to small perturbations, evolves around zero over time. Our approach demonstrates effective and significant improvements in experiments involving regime shifts in non-stationary systems. In particular, we train a neural network to deal with an abrupt change in Lorenz's chaotic system parameters. The neural network equipped with Lyapunov learning significantly outperforms the regular training, increasing the loss ratio by about $96\%$.
Dreaming Learning
Oct 23, 2024



Incorporating novelties into deep learning systems remains a challenging problem. Introducing new information to a machine learning system can interfere with previously stored data and potentially alter the global model paradigm, especially when dealing with non-stationary sources. In such cases, traditional approaches based on validation error minimization offer limited advantages. To address this, we propose a training algorithm inspired by Stuart Kauffman's notion of the Adjacent Possible. This novel training methodology explores new data spaces during the learning phase. It predisposes the neural network to smoothly accept and integrate data sequences with different statistical characteristics than expected. The maximum distance compatible with such inclusion depends on a specific parameter: the sampling temperature used in the explorative phase of the present method. This algorithm, called Dreaming Learning, anticipates potential regime shifts over time, enhancing the neural network's responsiveness to non-stationary events that alter statistical properties. To assess the advantages of this approach, we apply this methodology to unexpected statistical changes in Markov chains and non-stationary dynamics in textual sequences. We demonstrated its ability to improve the auto-correlation of generated textual sequences by $\sim 29\%$ and enhance the velocity of loss convergence by $\sim 100\%$ in the case of a paradigm shift in Markov chains.
Exploitation and exploration in text evolution. Quantifying planning and translation flows during writing
Feb 08, 2023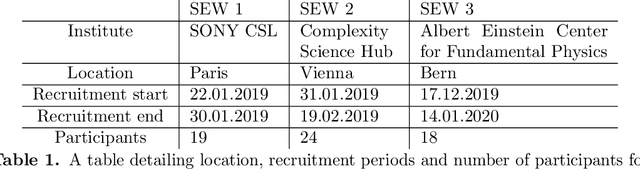
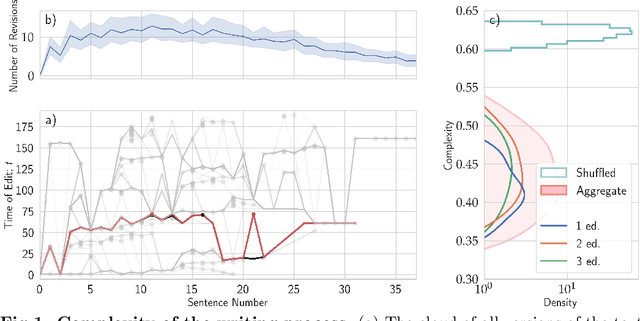
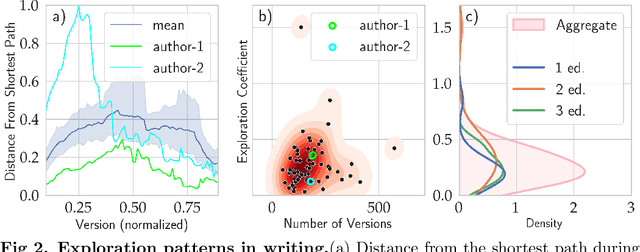
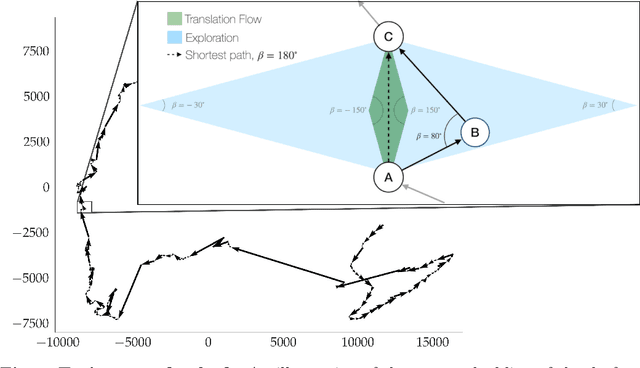
Writing is a complex process at the center of much of modern human activity. Despite it appears to be a linear process, writing conceals many highly non-linear processes. Previous research has focused on three phases of writing: planning, translation and transcription, and revision. While research has shown these are non-linear, they are often treated linearly when measured. Here, we introduce measures to detect and quantify subcycles of planning (exploration) and translation (exploitation) during the writing process. We apply these to a novel dataset that recorded the creation of a text in all its phases, from early attempts to the finishing touches on a final version. This dataset comes from a series of writing workshops in which, through innovative versioning software, we were able to record all the steps in the construction of a text. More than 60 junior researchers in science wrote a scientific essay intended for a general readership. We recorded each essay as a writing cloud, defined as a complex topological structure capturing the history of the essay itself. Through this unique dataset of writing clouds, we expose a representation of the writing process that quantifies its complexity and the writer's efforts throughout the draft and through time. Interestingly, this representation highlights the phases of "translation flow", where authors improve existing ideas, and exploration, where creative deviations appear as the writer returns to the planning phase. These turning points between translation and exploration become rarer as the writing process progresses and the author approaches the final version. Our results and the new measures introduced have the potential to foster the discussion about the non-linear nature of writing and support the development of tools that can support more creative and impactful writing processes.
Unsupervised inference approach to facial attractiveness
Oct 30, 2019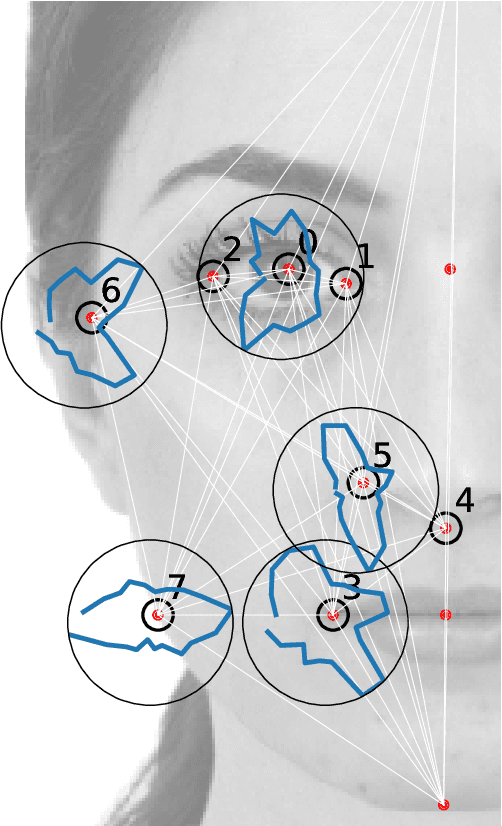
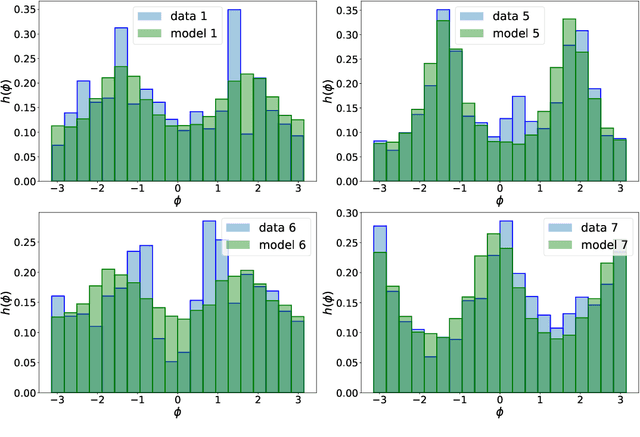
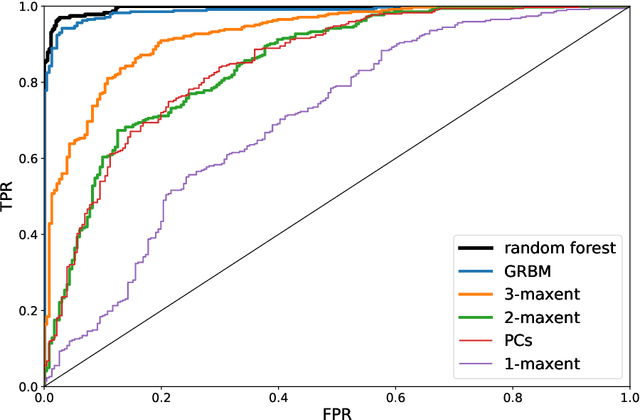

The perception of facial beauty is a complex phenomenon depending on many, detailed and global facial features influencing each other. In the machine learning community this problem is typically tackled as a problem of supervised inference. However, it has been conjectured that this approach does not capture the complexity of the phenomenon. A recent original experiment (Ib\'a\~nez-Berganza et al., Scientific Reports 9, 8364, 2019) allowed different human subjects to navigate the face-space and "sculpt" their preferred modification of a reference facial portrait. Here we present an unsupervised inference study of the set of sculpted facial vectors in that experiment. We first infer minimal, interpretable, and faithful probabilistic models (through Maximum Entropy and artificial neural networks) of the preferred facial variations, that capture the origin of the observed inter-subject diversity in the sculpted faces. The application of such generative models to the supervised classification of the gender of the sculpting subjects, reveals an astonishingly high prediction accuracy. This result suggests that much relevant information regarding the subjects may influence (and be elicited from) her/his facial preference criteria, in agreement with the multiple motive theory of attractiveness proposed in previous works.
Subjectivity and complexity of facial attractiveness
Mar 18, 2019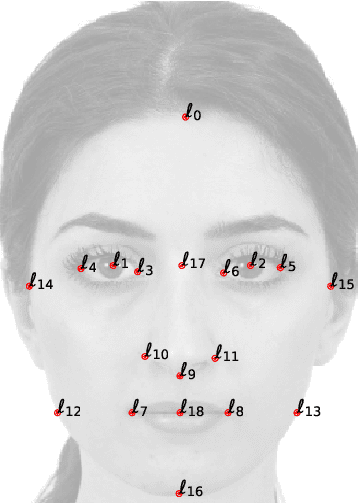



The origin and meaning of facial beauty represent a longstanding puzzle. Despite the profuse literature devoted to facial attractiveness, its very nature, its determinants and the nature of inter-person differences remain controversial issues. Here we tackle such questions proposing a novel experimental approach in which human subjects, instead of rating natural faces, are allowed to efficiently explore the face-space and "sculpt" their favorite variation of a reference facial image. The results reveal that different subjects prefer distinguishable regions of the face-space, highlighting the essential subjectivity of the phenomenon. The different sculpted facial vectors exhibit strong correlations among pairs of facial distances, characterizing the underlying universality and complexity of the cognitive processes, leading to the observed subjectivity.
Complexity Reduction in the Negotiation of New Lexical Conventions
May 17, 2018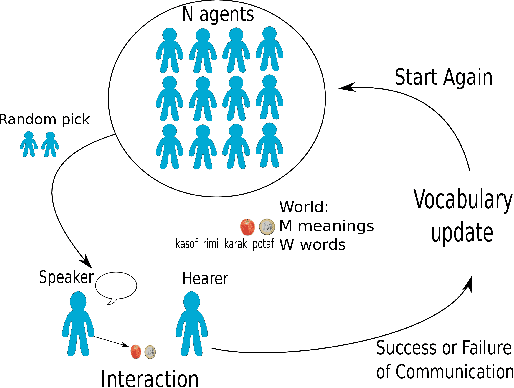
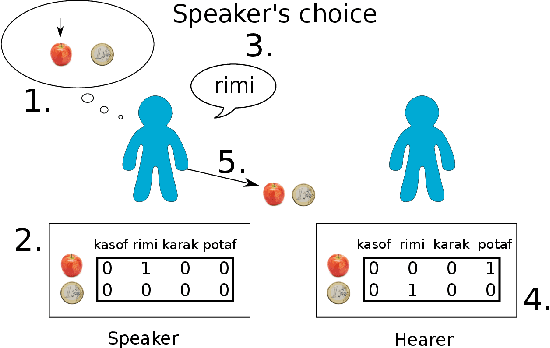
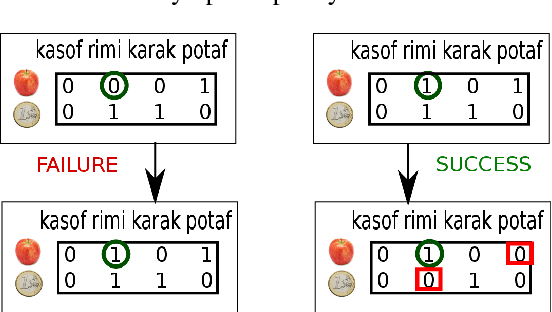

In the process of collectively inventing new words for new concepts in a population, conflicts can quickly become numerous, in the form of synonymy and homonymy. Remembering all of them could cost too much memory, and remembering too few may slow down the overall process. Is there an efficient behavior that could help balance the two? The Naming Game is a multi-agent computational model for the emergence of language, focusing on the negotiation of new lexical conventions, where a common lexicon self-organizes but going through a phase of high complexity. Previous work has been done on the control of complexity growth in this particular model, by allowing agents to actively choose what they talk about. However, those strategies were relying on ad hoc heuristics highly dependent on fine-tuning of parameters. We define here a new principled measure and a new strategy, based on the beliefs of each agent on the global state of the population. The measure does not rely on heavy computation, and is cognitively plausible. The new strategy yields an efficient control of complexity growth, along with a faster agreement process. Also, we show that short-term memory is enough to build relevant beliefs about the global lexicon.
Maximum entropy models capture melodic styles
Oct 11, 2016
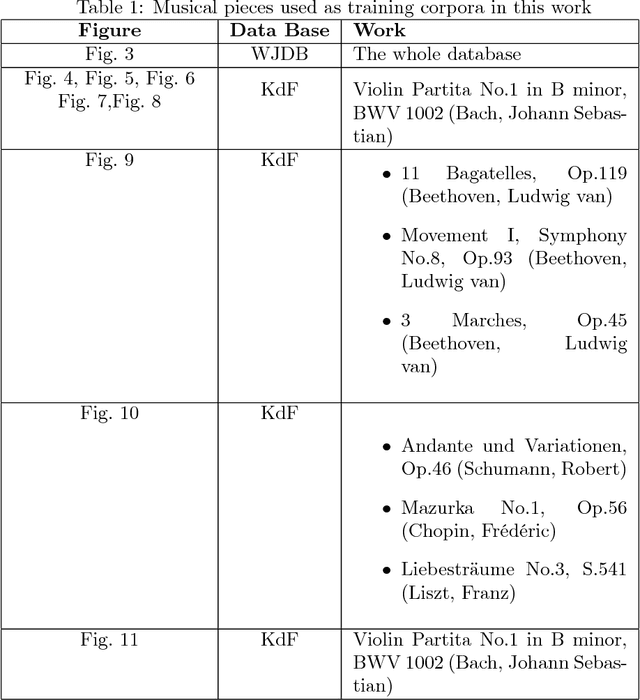
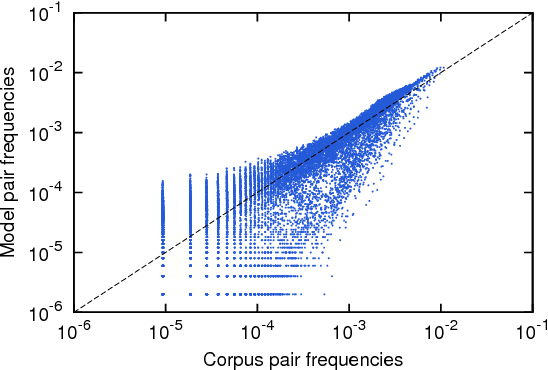
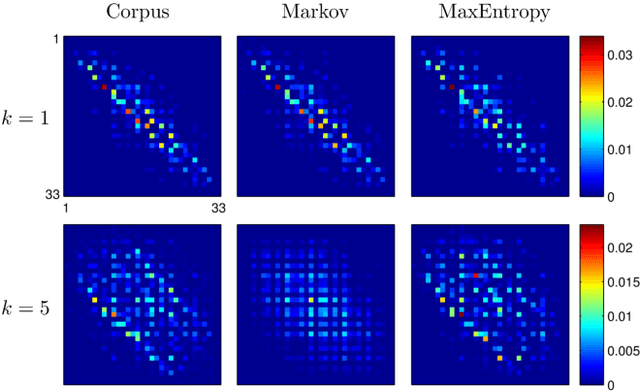
We introduce a Maximum Entropy model able to capture the statistics of melodies in music. The model can be used to generate new melodies that emulate the style of the musical corpus which was used to train it. Instead of using the $n-$body interactions of $(n-1)-$order Markov models, traditionally used in automatic music generation, we use a $k-$nearest neighbour model with pairwise interactions only. In that way, we keep the number of parameters low and avoid over-fitting problems typical of Markov models. We show that long-range musical phrases don't need to be explicitly enforced using high-order Markov interactions, but can instead emerge from multiple, competing, pairwise interactions. We validate our Maximum Entropy model by contrasting how much the generated sequences capture the style of the original corpus without plagiarizing it. To this end we use a data-compression approach to discriminate the levels of borrowing and innovation featured by the artificial sequences. The results show that our modelling scheme outperforms both fixed-order and variable-order Markov models. This shows that, despite being based only on pairwise interactions, this Maximum Entropy scheme opens the possibility to generate musically sensible alterations of the original phrases, providing a way to generate innovation.
On the emergence of syntactic structures: quantifying and modelling duality of patterning
Feb 11, 2016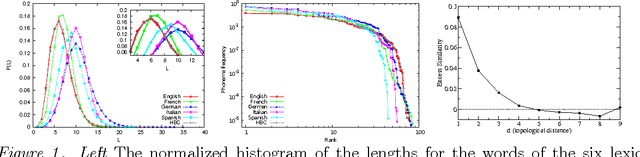
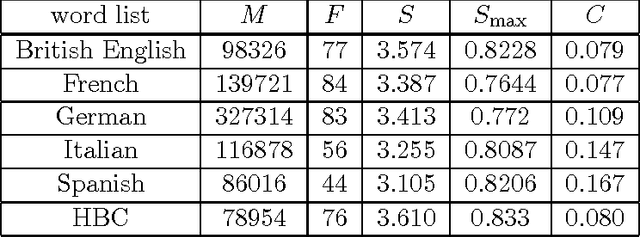
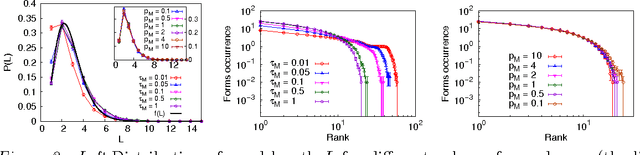

The complex organization of syntax in hierarchical structures is one of the core design features of human language. Duality of patterning refers for instance to the organization of the meaningful elements in a language at two distinct levels: a combinatorial level where meaningless forms are combined into meaningful forms and a compositional level where meaningful forms are composed into larger lexical units. The question remains wide open regarding how such a structure could have emerged. Furthermore a clear mathematical framework to quantify this phenomenon is still lacking. The aim of this paper is that of addressing these two aspects in a self-consistent way. First, we introduce suitable measures to quantify the level of combinatoriality and compositionality in a language, and present a framework to estimate these observables in human natural languages. Second, we show that the theoretical predictions of a multi-agents modeling scheme, namely the Blending Game, are in surprisingly good agreement with empirical data. In the Blending Game a population of individuals plays language games aiming at success in communication. It is remarkable that the two sides of duality of patterning emerge simultaneously as a consequence of a pure cultural dynamics in a simulated environment that contains meaningful relations, provided a simple constraint on message transmission fidelity is also considered.
Individual Biases, Cultural Evolution, and the Statistical Nature of Language Universals: The Case of Colour Naming Systems
Jun 23, 2015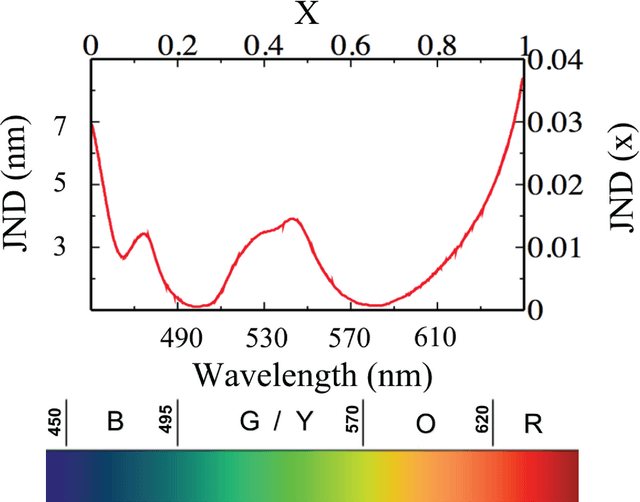



Language universals have long been attributed to an innate Universal Grammar. An alternative explanation states that linguistic universals emerged independently in every language in response to shared cognitive or perceptual biases. A computational model has recently shown how this could be the case, focusing on the paradigmatic example of the universal properties of colour naming patterns, and producing results in quantitative agreement with the experimental data. Here we investigate the role of an individual perceptual bias in the framework of the model. We study how, and to what extent, the structure of the bias influences the corresponding linguistic universal patterns. We show that the cultural history of a group of speakers introduces population-specific constraints that act against the pressure for uniformity arising from the individual bias, and we clarify the interplay between these two forces.