 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExploitation and exploration in text evolution. Quantifying planning and translation flows during writing
Feb 08, 2023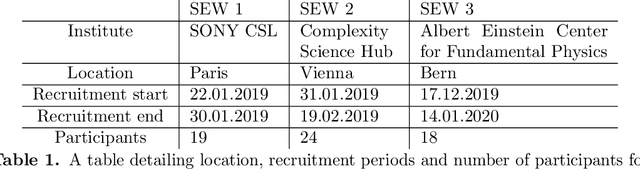
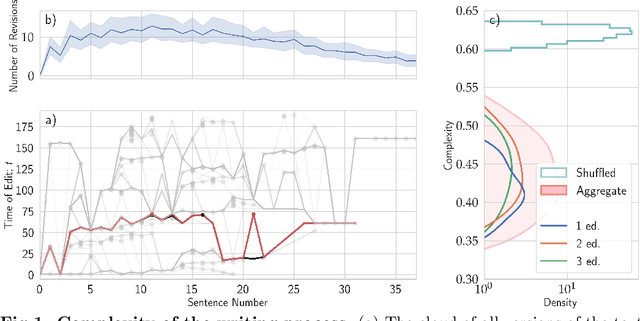
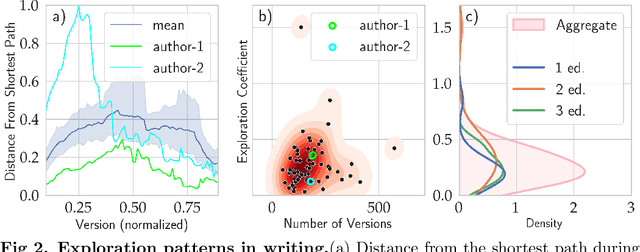
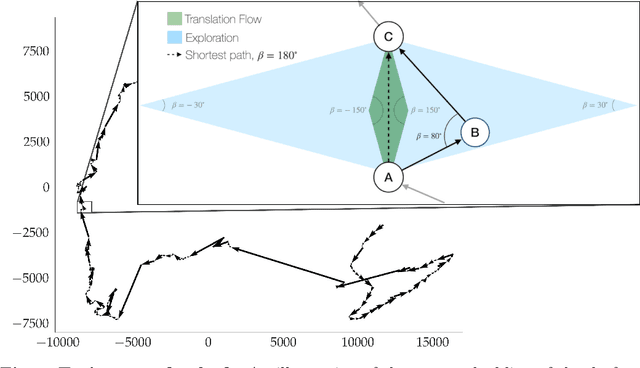
Writing is a complex process at the center of much of modern human activity. Despite it appears to be a linear process, writing conceals many highly non-linear processes. Previous research has focused on three phases of writing: planning, translation and transcription, and revision. While research has shown these are non-linear, they are often treated linearly when measured. Here, we introduce measures to detect and quantify subcycles of planning (exploration) and translation (exploitation) during the writing process. We apply these to a novel dataset that recorded the creation of a text in all its phases, from early attempts to the finishing touches on a final version. This dataset comes from a series of writing workshops in which, through innovative versioning software, we were able to record all the steps in the construction of a text. More than 60 junior researchers in science wrote a scientific essay intended for a general readership. We recorded each essay as a writing cloud, defined as a complex topological structure capturing the history of the essay itself. Through this unique dataset of writing clouds, we expose a representation of the writing process that quantifies its complexity and the writer's efforts throughout the draft and through time. Interestingly, this representation highlights the phases of "translation flow", where authors improve existing ideas, and exploration, where creative deviations appear as the writer returns to the planning phase. These turning points between translation and exploration become rarer as the writing process progresses and the author approaches the final version. Our results and the new measures introduced have the potential to foster the discussion about the non-linear nature of writing and support the development of tools that can support more creative and impactful writing processes.
comp-syn: Perceptually Grounded Word Embeddings with Color
Oct 19, 2020
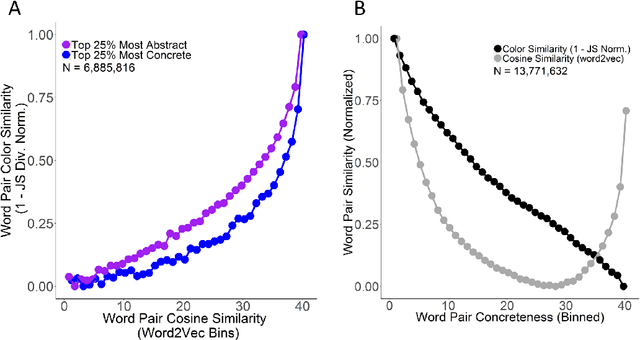
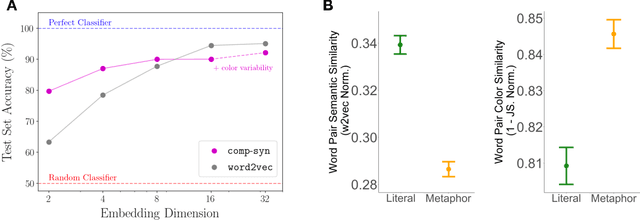

Popular approaches to natural language processing create word embeddings based on textual co-occurrence patterns, but often ignore embodied, sensory aspects of language. Here, we introduce the Python package comp-syn, which provides grounded word embeddings based on the perceptually uniform color distributions of Google Image search results. We demonstrate that comp-syn significantly enriches models of distributional semantics. In particular, we show that (1) comp-syn predicts human judgments of word concreteness with greater accuracy and in a more interpretable fashion than word2vec using low-dimensional word-color embeddings, and (2) comp-syn performs comparably to word2vec on a metaphorical vs. literal word-pair classification task. comp-syn is open-source on PyPi and is compatible with mainstream machine-learning Python packages. Our package release includes word-color embeddings for over 40,000 English words, each associated with crowd-sourced word concreteness judgments.