 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvolving linguistic divergence on polarizing social media
Sep 04, 2023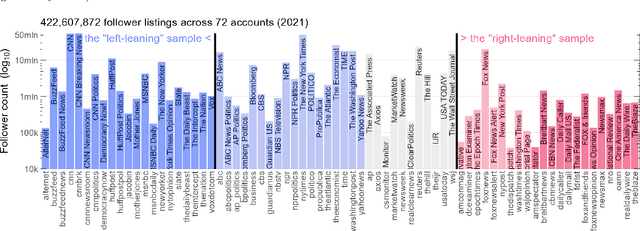
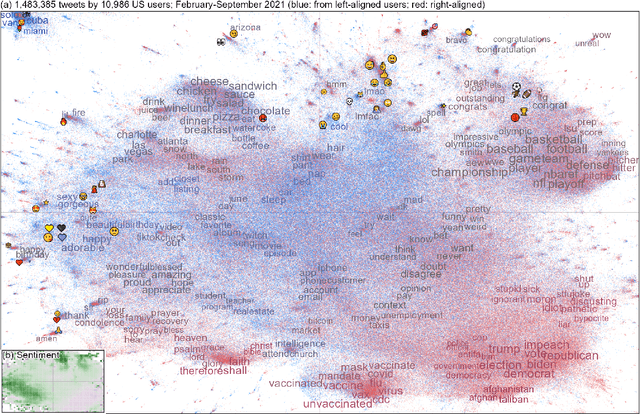
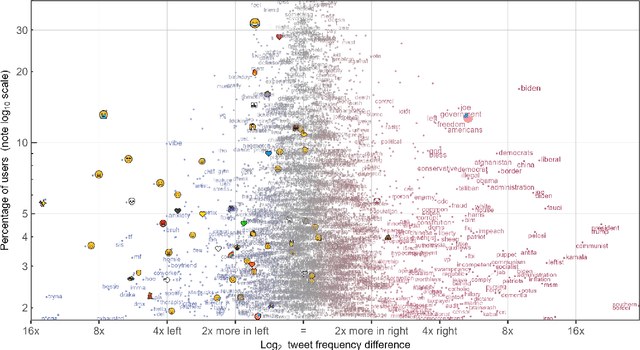
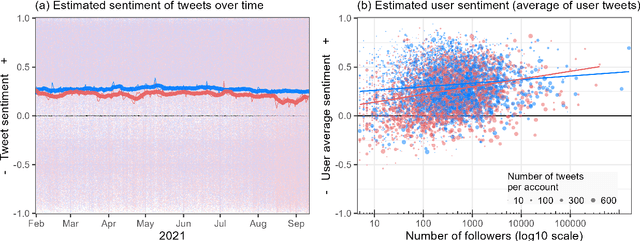
Language change is influenced by many factors, but often starts from synchronic variation, where multiple linguistic patterns or forms coexist, or where different speech communities use language in increasingly different ways. Besides regional or economic reasons, communities may form and segregate based on political alignment. The latter, referred to as political polarization, is of growing societal concern across the world. Here we map and quantify linguistic divergence across the partisan left-right divide in the United States, using social media data. We develop a general methodology to delineate (social) media users by their political preference, based on which (potentially biased) news media accounts they do and do not follow on a given platform. Our data consists of 1.5M short posts by 10k users (about 20M words) from the social media platform Twitter (now "X"). Delineating this sample involved mining the platform for the lists of followers (n=422M) of 72 large news media accounts. We quantify divergence in topics of conversation and word frequencies, messaging sentiment, and lexical semantics of words and emoji. We find signs of linguistic divergence across all these aspects, especially in topics and themes of conversation, in line with previous research. While US American English remains largely intelligible within its large speech community, our findings point at areas where miscommunication may eventually arise given ongoing polarization and therefore potential linguistic divergence. Our methodology - combining data mining, lexicostatistics, machine learning, large language models and a systematic human annotation approach - is largely language and platform agnostic. In other words, while we focus here on US political divides and US English, the same approach is applicable to other countries, languages, and social media platforms.
Exploitation and exploration in text evolution. Quantifying planning and translation flows during writing
Feb 08, 2023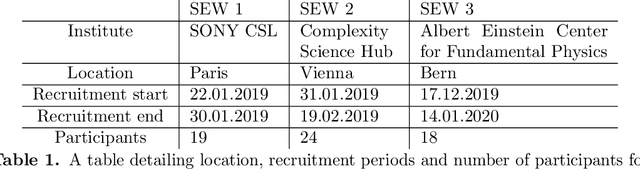
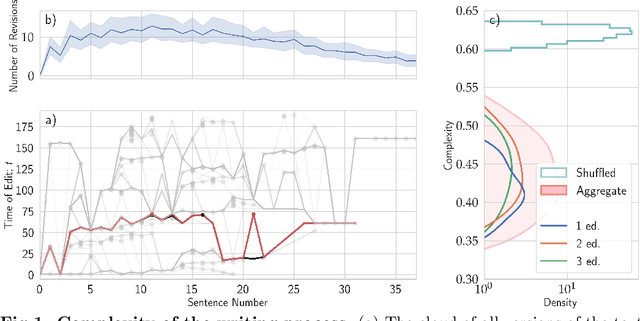
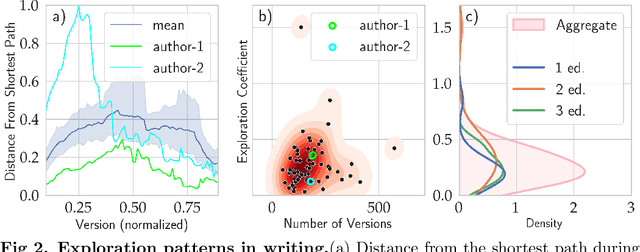
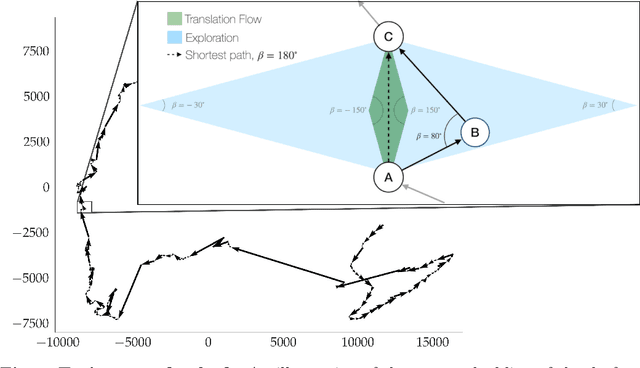
Writing is a complex process at the center of much of modern human activity. Despite it appears to be a linear process, writing conceals many highly non-linear processes. Previous research has focused on three phases of writing: planning, translation and transcription, and revision. While research has shown these are non-linear, they are often treated linearly when measured. Here, we introduce measures to detect and quantify subcycles of planning (exploration) and translation (exploitation) during the writing process. We apply these to a novel dataset that recorded the creation of a text in all its phases, from early attempts to the finishing touches on a final version. This dataset comes from a series of writing workshops in which, through innovative versioning software, we were able to record all the steps in the construction of a text. More than 60 junior researchers in science wrote a scientific essay intended for a general readership. We recorded each essay as a writing cloud, defined as a complex topological structure capturing the history of the essay itself. Through this unique dataset of writing clouds, we expose a representation of the writing process that quantifies its complexity and the writer's efforts throughout the draft and through time. Interestingly, this representation highlights the phases of "translation flow", where authors improve existing ideas, and exploration, where creative deviations appear as the writer returns to the planning phase. These turning points between translation and exploration become rarer as the writing process progresses and the author approaches the final version. Our results and the new measures introduced have the potential to foster the discussion about the non-linear nature of writing and support the development of tools that can support more creative and impactful writing processes.