 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMachine-Assisted Grading of Nationwide School-Leaving Essay Exams with LLMs and Statistical NLP
Jan 22, 2026Large language models (LLMs) enable rapid and consistent automated evaluation of open-ended exam responses, including dimensions of content and argumentation that have traditionally required human judgment. This is particularly important in cases where a large amount of exams need to be graded in a limited time frame, such as nation-wide graduation exams in various countries. Here, we examine the applicability of automated scoring on two large datasets of trial exam essays of two full national cohorts from Estonia. We operationalize the official curriculum-based rubric and compare LLM and statistical natural language processing (NLP) based assessments with human panel scores. The results show that automated scoring can achieve performance comparable to that of human raters and tends to fall within the human scoring range. We also evaluate bias, prompt injection risks, and LLMs as essay writers. These findings demonstrate that a principled, rubric-driven, human-in-the-loop scoring pipeline is viable for high-stakes writing assessment, particularly relevant for digitally advanced societies like Estonia, which is about to adapt a fully electronic examination system. Furthermore, the system produces fine-grained subscore profiles that can be used to generate systematic, personalized feedback for instruction and exam preparation. The study provides evidence that LLM-assisted assessment can be implemented at a national scale, even in a small-language context, while maintaining human oversight and compliance with emerging educational and regulatory standards.
Expertise elevates AI usage: experimental evidence comparing laypeople and professional artists
Jan 21, 2025



Novel capacities of generative AI to analyze and generate cultural artifacts raise inevitable questions about the nature and value of artistic education and human expertise. Has AI already leveled the playing field between professional artists and laypeople, or do trained artistic expressive capacity, curation skills and experience instead enhance the ability to use these new tools? In this pre-registered study, we conduct experimental comparisons between 50 active artists and a demographically matched sample of laypeople. We designed two tasks to approximate artistic practice for testing their capabilities in both faithful and creative image creation: replicating a reference image, and moving as far away as possible from it. We developed a bespoke platform where participants used a modern text-to-image model to complete both tasks. We also collected and compared participants' sentiments towards AI. On average, artists produced more faithful and creative outputs than their lay counterparts, although only by a small margin. While AI may ease content creation, professional expertise is still valuable - even within the confined space of generative AI itself. Finally, we also explored how well an exemplary vision-capable large language model (GPT-4o) would complete the same tasks, if given the role of an image generation agent, and found it performed on par in copying but outperformed even artists in the creative task. The very best results were still produced by humans in both tasks. These outcomes highlight the importance of integrating artistic skills with AI training to prepare artists and other visual professionals for a technologically evolving landscape. We see a potential in collaborative synergy with generative AI, which could reshape creative industries and education in the arts.
fruit-SALAD: A Style Aligned Artwork Dataset to reveal similarity perception in image embeddings
Jun 03, 2024



The notion of visual similarity is essential for computer vision, and in applications and studies revolving around vector embeddings of images. However, the scarcity of benchmark datasets poses a significant hurdle in exploring how these models perceive similarity. Here we introduce Style Aligned Artwork Datasets (SALADs), and an example of fruit-SALAD with 10,000 images of fruit depictions. This combined semantic category and style benchmark comprises 100 instances each of 10 easy-to-recognize fruit categories, across 10 easy distinguishable styles. Leveraging a systematic pipeline of generative image synthesis, this visually diverse yet balanced benchmark demonstrates salient differences in semantic category and style similarity weights across various computational models, including machine learning models, feature extraction algorithms, and complexity measures, as well as conceptual models for reference. This meticulously designed dataset offers a controlled and balanced platform for the comparative analysis of similarity perception. The SALAD framework allows the comparison of how these models perform semantic category and style recognition task to go beyond the level of anecdotal knowledge, making it robustly quantifiable and qualitatively interpretable.
Machine-assisted mixed methods: augmenting humanities and social sciences with artificial intelligence
Sep 24, 2023



The increasing capacities of large language models (LLMs) present an unprecedented opportunity to scale up data analytics in the humanities and social sciences, augmenting and automating qualitative analytic tasks previously typically allocated to human labor. This contribution proposes a systematic mixed methods framework to harness qualitative analytic expertise, machine scalability, and rigorous quantification, with attention to transparency and replicability. 16 machine-assisted case studies are showcased as proof of concept. Tasks include linguistic and discourse analysis, lexical semantic change detection, interview analysis, historical event cause inference and text mining, detection of political stance, text and idea reuse, genre composition in literature and film; social network inference, automated lexicography, missing metadata augmentation, and multimodal visual cultural analytics. In contrast to the focus on English in the emerging LLM applicability literature, many examples here deal with scenarios involving smaller languages and historical texts prone to digitization distortions. In all but the most difficult tasks requiring expert knowledge, generative LLMs can demonstrably serve as viable research instruments. LLM (and human) annotations may contain errors and variation, but the agreement rate can and should be accounted for in subsequent statistical modeling; a bootstrapping approach is discussed. The replications among the case studies illustrate how tasks previously requiring potentially months of team effort and complex computational pipelines, can now be accomplished by an LLM-assisted scholar in a fraction of the time. Importantly, this approach is not intended to replace, but to augment researcher knowledge and skills. With these opportunities in sight, qualitative expertise and the ability to pose insightful questions have arguably never been more critical.
Evolving linguistic divergence on polarizing social media
Sep 04, 2023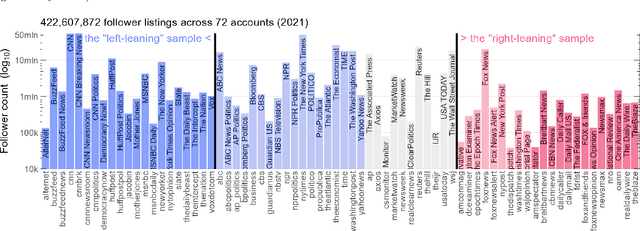
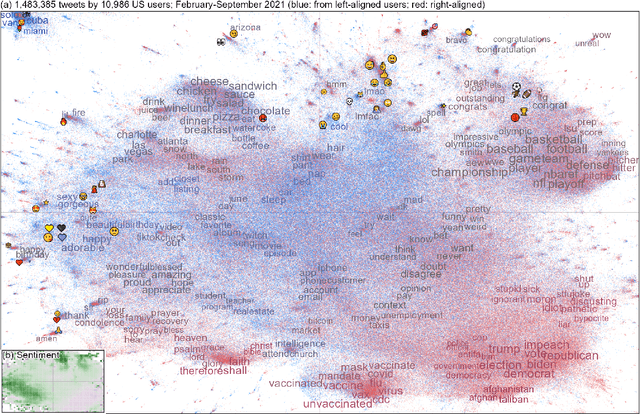
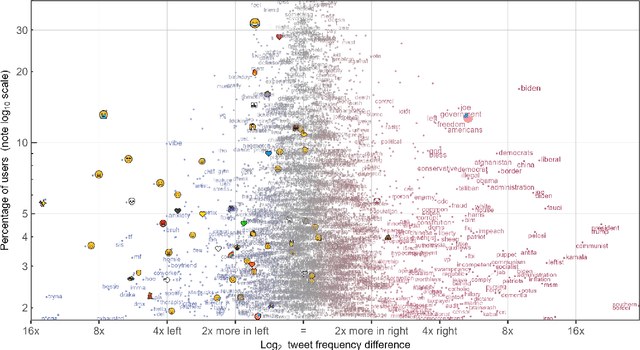
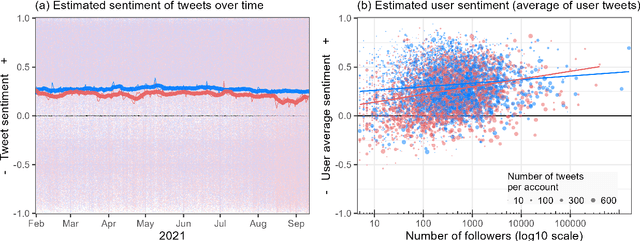
Language change is influenced by many factors, but often starts from synchronic variation, where multiple linguistic patterns or forms coexist, or where different speech communities use language in increasingly different ways. Besides regional or economic reasons, communities may form and segregate based on political alignment. The latter, referred to as political polarization, is of growing societal concern across the world. Here we map and quantify linguistic divergence across the partisan left-right divide in the United States, using social media data. We develop a general methodology to delineate (social) media users by their political preference, based on which (potentially biased) news media accounts they do and do not follow on a given platform. Our data consists of 1.5M short posts by 10k users (about 20M words) from the social media platform Twitter (now "X"). Delineating this sample involved mining the platform for the lists of followers (n=422M) of 72 large news media accounts. We quantify divergence in topics of conversation and word frequencies, messaging sentiment, and lexical semantics of words and emoji. We find signs of linguistic divergence across all these aspects, especially in topics and themes of conversation, in line with previous research. While US American English remains largely intelligible within its large speech community, our findings point at areas where miscommunication may eventually arise given ongoing polarization and therefore potential linguistic divergence. Our methodology - combining data mining, lexicostatistics, machine learning, large language models and a systematic human annotation approach - is largely language and platform agnostic. In other words, while we focus here on US political divides and US English, the same approach is applicable to other countries, languages, and social media platforms.
Reliable identification of selection mechanisms in language change
May 25, 2023
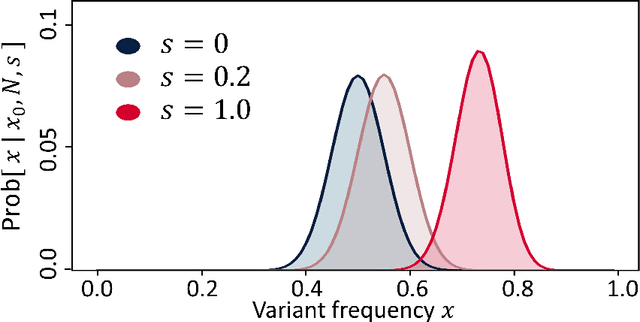

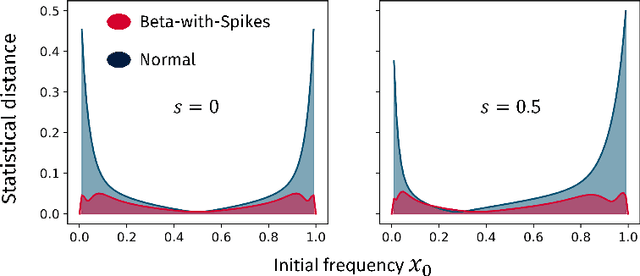
Language change is a cultural evolutionary process in which variants of linguistic variables change in frequency through processes analogous to mutation, selection and genetic drift. In this work, we apply a recently-introduced method to corpus data to quantify the strength of selection in specific instances of historical language change. We first demonstrate, in the context of English irregular verbs, that this method is more reliable and interpretable than similar methods that have previously been applied. We further extend this study to demonstrate that a bias towards phonological simplicity overrides that favouring grammatical simplicity when these are in conflict. Finally, with reference to Spanish spelling reforms, we show that the method can also detect points in time at which selection strengths change, a feature that is generically expected for socially-motivated language change. Together, these results indicate how hypotheses for mechanisms of language change can be tested quantitatively using historical corpus data.
Automated stance detection in complex topics and small languages: the challenging case of immigration in polarizing news media
May 22, 2023

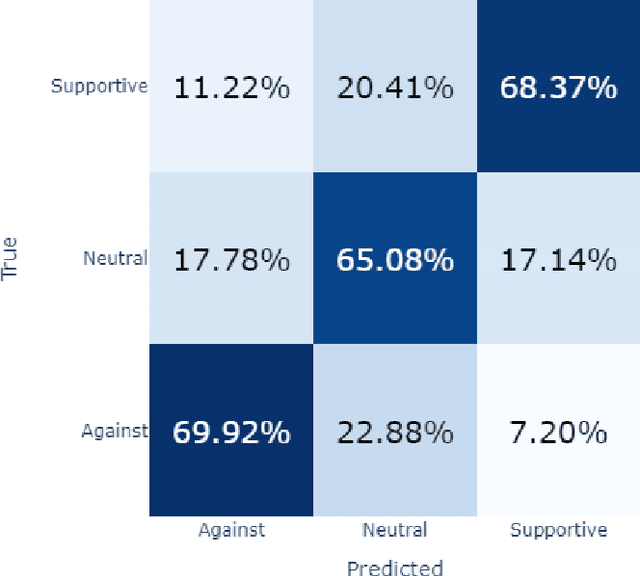
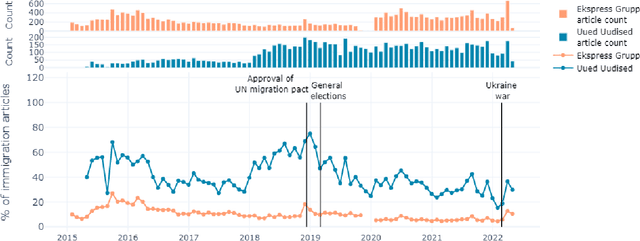
Automated stance detection and related machine learning methods can provide useful insights for media monitoring and academic research. Many of these approaches require annotated training datasets, which limits their applicability for languages where these may not be readily available. This paper explores the applicability of large language models for automated stance detection in a challenging scenario, involving a morphologically complex, lower-resource language, and a socio-culturally complex topic, immigration. If the approach works in this case, it can be expected to perform as well or better in less demanding scenarios. We annotate a large set of pro and anti-immigration examples, and compare the performance of multiple language models as supervised learners. We also probe the usability of ChatGPT as an instructable zero-shot classifier for the same task. Supervised achieves acceptable performance, and ChatGPT yields similar accuracy. This is promising as a potentially simpler and cheaper alternative for text classification tasks, including in lower-resource languages. We further use the best-performing model to investigate diachronic trends over seven years in two corpora of Estonian mainstream and right-wing populist news sources, demonstrating the applicability of the approach for news analytics and media monitoring settings, and discuss correspondences between stance changes and real-world events.
Collection Space Navigator: An Interactive Visualization Interface for Multidimensional Datasets
May 11, 2023


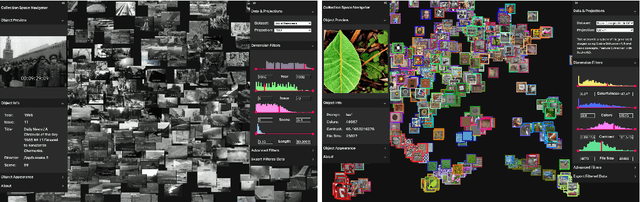
We introduce the Collection Space Navigator (CSN), a browser-based visualization tool to explore, research, and curate large collections of visual digital artifacts that are associated with multidimensional data, such as vector embeddings or tables of metadata. Media objects such as images are often encoded as numerical vectors, for e.g. based on metadata or using machine learning to embed image information. Yet, while such procedures are widespread for a range of applications, it remains a challenge to explore, analyze, and understand the resulting multidimensional spaces in a more comprehensive manner. Dimensionality reduction techniques such as t-SNE or UMAP often serve to project high-dimensional data into low dimensional visualizations, yet require interpretation themselves as the remaining dimensions are typically abstract. Here, the Collection Space Navigator provides a customizable interface that combines two-dimensional projections with a set of configurable multidimensional filters. As a result, the user is able to view and investigate collections, by zooming and scaling, by transforming between projections, by filtering dimensions via range sliders, and advanced text filters. Insights that are gained during the interaction can be fed back into the original data via ad hoc exports of filtered metadata and projections. This paper comes with a functional showcase demo using a large digitized collection of classical Western art. The Collection Space Navigator is open source. Users can reconfigure the interface to fit their own data and research needs, including projections and filter controls. The CSN is ready to serve a broad community.
Compression ensembles quantify aesthetic complexity and the evolution of visual art
May 20, 2022

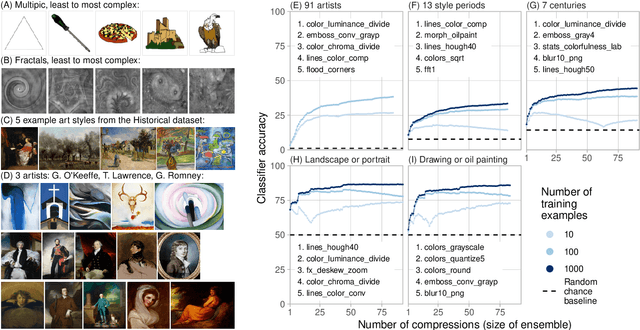
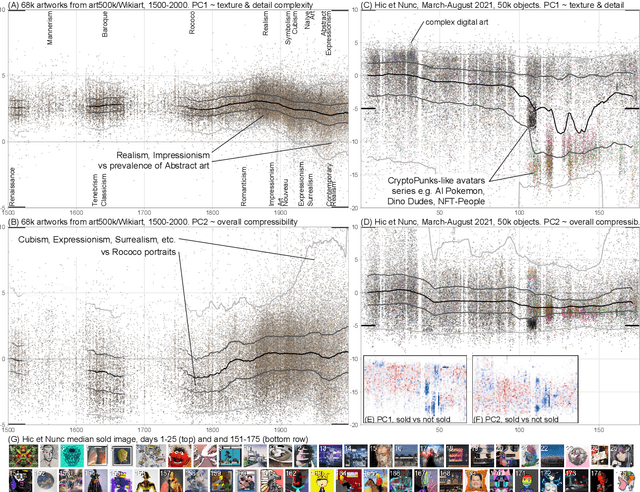
The quantification of visual aesthetics and complexity have a long history, the latter previously operationalized via the application of compression algorithms. Here we generalize and extend the compression approach beyond simple complexity measures to quantify algorithmic distance in historical and contemporary visual media. The proposed "ensemble" approach works by compressing a large number of transformed versions of a given input image, resulting in a vector of associated compression ratios. This approach is more efficient than other compression-based algorithmic distances, and is particularly suited for the quantitative analysis of visual artifacts, because human creative processes can be understood as algorithms in the broadest sense. Unlike comparable image embedding methods using machine learning, our approach is fully explainable through the transformations. We demonstrate that the method is cognitively plausible and fit for purpose by evaluating it against human complexity judgments, and on automated detection tasks of authorship and style. We show how the approach can be used to reveal and quantify trends in art historical data, both on the scale of centuries and in rapidly evolving contemporary NFT art markets. We further quantify temporal resemblance to disambiguate artists outside the documented mainstream from those who are deeply embedded in Zeitgeist. Finally, we note that compression ensembles constitute a quantitative representation of the concept of visual family resemblance, as distinct sets of dimensions correspond to shared visual characteristics otherwise hard to pin down. Our approach provides a new perspective for the study of visual art, algorithmic image analysis, and quantitative aesthetics more generally.
Conceptual similarity and communicative need shape colexification: an experimental study
Mar 19, 2021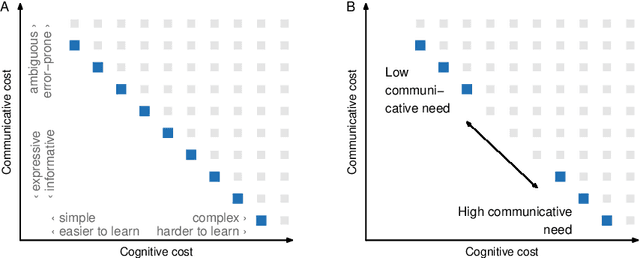
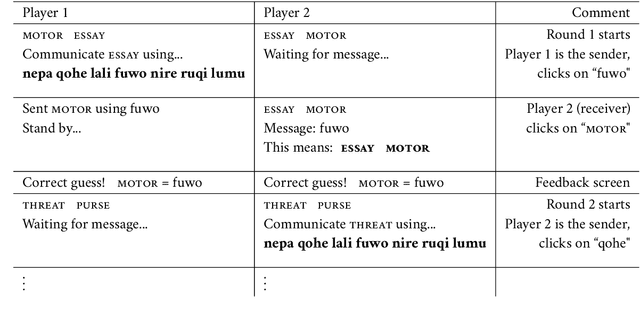
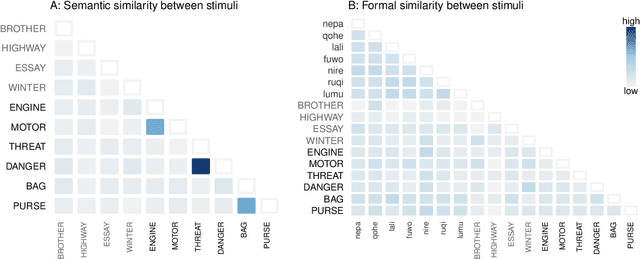

Colexification refers to the phenomenon of multiple meanings sharing one word in a language. Cross-linguistic lexification patterns have been shown to be largely predictable, as similar concepts are often colexified. We test a recent claim that, beyond this general tendency, communicative needs play an important role in shaping colexification patterns. We approach this question by means of a series of human experiments, using an artificial language communication game paradigm. Our results across four experiments match the previous cross-linguistic findings: all other things being equal, speakers do prefer to colexify similar concepts. However, we also find evidence supporting the communicative need hypothesis: when faced with a frequent need to distinguish similar pairs of meanings, speakers adjust their colexification preferences to maintain communicative efficiency, and avoid colexifying those similar meanings which need to be distinguished in communication. This research provides further evidence to support the argument that languages are shaped by the needs and preferences of their speakers.