 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edgefruit-SALAD: A Style Aligned Artwork Dataset to reveal similarity perception in image embeddings
Jun 03, 2024



The notion of visual similarity is essential for computer vision, and in applications and studies revolving around vector embeddings of images. However, the scarcity of benchmark datasets poses a significant hurdle in exploring how these models perceive similarity. Here we introduce Style Aligned Artwork Datasets (SALADs), and an example of fruit-SALAD with 10,000 images of fruit depictions. This combined semantic category and style benchmark comprises 100 instances each of 10 easy-to-recognize fruit categories, across 10 easy distinguishable styles. Leveraging a systematic pipeline of generative image synthesis, this visually diverse yet balanced benchmark demonstrates salient differences in semantic category and style similarity weights across various computational models, including machine learning models, feature extraction algorithms, and complexity measures, as well as conceptual models for reference. This meticulously designed dataset offers a controlled and balanced platform for the comparative analysis of similarity perception. The SALAD framework allows the comparison of how these models perform semantic category and style recognition task to go beyond the level of anecdotal knowledge, making it robustly quantifiable and qualitatively interpretable.
Automated stance detection in complex topics and small languages: the challenging case of immigration in polarizing news media
May 22, 2023Automated stance detection and related machine learning methods can provide useful insights for media monitoring and academic research. Many of these approaches require annotated training datasets, which limits their applicability for languages where these may not be readily available. This paper explores the applicability of large language models for automated stance detection in a challenging scenario, involving a morphologically complex, lower-resource language, and a socio-culturally complex topic, immigration. If the approach works in this case, it can be expected to perform as well or better in less demanding scenarios. We annotate a large set of pro and anti-immigration examples, and compare the performance of multiple language models as supervised learners. We also probe the usability of ChatGPT as an instructable zero-shot classifier for the same task. Supervised achieves acceptable performance, and ChatGPT yields similar accuracy. This is promising as a potentially simpler and cheaper alternative for text classification tasks, including in lower-resource languages. We further use the best-performing model to investigate diachronic trends over seven years in two corpora of Estonian mainstream and right-wing populist news sources, demonstrating the applicability of the approach for news analytics and media monitoring settings, and discuss correspondences between stance changes and real-world events.
Collection Space Navigator: An Interactive Visualization Interface for Multidimensional Datasets
May 11, 2023We introduce the Collection Space Navigator (CSN), a browser-based visualization tool to explore, research, and curate large collections of visual digital artifacts that are associated with multidimensional data, such as vector embeddings or tables of metadata. Media objects such as images are often encoded as numerical vectors, for e.g. based on metadata or using machine learning to embed image information. Yet, while such procedures are widespread for a range of applications, it remains a challenge to explore, analyze, and understand the resulting multidimensional spaces in a more comprehensive manner. Dimensionality reduction techniques such as t-SNE or UMAP often serve to project high-dimensional data into low dimensional visualizations, yet require interpretation themselves as the remaining dimensions are typically abstract. Here, the Collection Space Navigator provides a customizable interface that combines two-dimensional projections with a set of configurable multidimensional filters. As a result, the user is able to view and investigate collections, by zooming and scaling, by transforming between projections, by filtering dimensions via range sliders, and advanced text filters. Insights that are gained during the interaction can be fed back into the original data via ad hoc exports of filtered metadata and projections. This paper comes with a functional showcase demo using a large digitized collection of classical Western art. The Collection Space Navigator is open source. Users can reconfigure the interface to fit their own data and research needs, including projections and filter controls. The CSN is ready to serve a broad community.
Compression ensembles quantify aesthetic complexity and the evolution of visual art
May 20, 2022

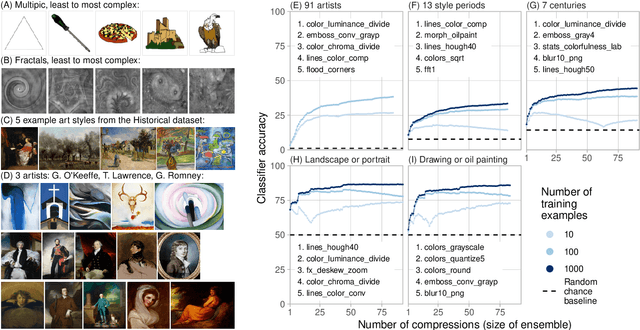
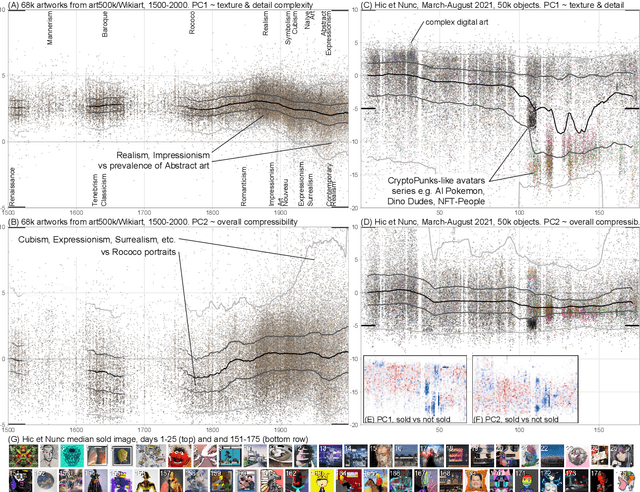
The quantification of visual aesthetics and complexity have a long history, the latter previously operationalized via the application of compression algorithms. Here we generalize and extend the compression approach beyond simple complexity measures to quantify algorithmic distance in historical and contemporary visual media. The proposed "ensemble" approach works by compressing a large number of transformed versions of a given input image, resulting in a vector of associated compression ratios. This approach is more efficient than other compression-based algorithmic distances, and is particularly suited for the quantitative analysis of visual artifacts, because human creative processes can be understood as algorithms in the broadest sense. Unlike comparable image embedding methods using machine learning, our approach is fully explainable through the transformations. We demonstrate that the method is cognitively plausible and fit for purpose by evaluating it against human complexity judgments, and on automated detection tasks of authorship and style. We show how the approach can be used to reveal and quantify trends in art historical data, both on the scale of centuries and in rapidly evolving contemporary NFT art markets. We further quantify temporal resemblance to disambiguate artists outside the documented mainstream from those who are deeply embedded in Zeitgeist. Finally, we note that compression ensembles constitute a quantitative representation of the concept of visual family resemblance, as distinct sets of dimensions correspond to shared visual characteristics otherwise hard to pin down. Our approach provides a new perspective for the study of visual art, algorithmic image analysis, and quantitative aesthetics more generally.