 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvaluating the relationship between regularity and learnability in recursive numeral systems using Reinforcement Learning
Feb 25, 2026Human recursive numeral systems (i.e., counting systems such as English base-10 numerals), like many other grammatical systems, are highly regular. Following prior work that relates cross-linguistic tendencies to biases in learning, we ask whether regular systems are common because regularity facilitates learning. Adopting methods from the Reinforcement Learning literature, we confirm that highly regular human(-like) systems are easier to learn than unattested but possible irregular systems. This asymmetry emerges under the natural assumption that recursive numeral systems are designed for generalisation from limited data to represent all integers exactly. We also find that the influence of regularity on learnability is absent for unnatural, highly irregular systems, whose learnability is influenced instead by signal length, suggesting that different pressures may influence learnability differently in different parts of the space of possible numeral systems. Our results contribute to the body of work linking learnability to cross-linguistic prevalence.
Recursive numeral systems are highly regular and easy to process
Oct 30, 2025Previous work has argued that recursive numeral systems optimise the trade-off between lexicon size and average morphosyntatic complexity (Deni\'c and Szymanik, 2024). However, showing that only natural-language-like systems optimise this tradeoff has proven elusive, and the existing solution has relied on ad-hoc constraints to rule out unnatural systems (Yang and Regier, 2025). Here, we argue that this issue arises because the proposed trade-off has neglected regularity, a crucial aspect of complexity central to human grammars in general. Drawing on the Minimum Description Length (MDL) approach, we propose that recursive numeral systems are better viewed as efficient with regard to their regularity and processing complexity. We show that our MDL-based measures of regularity and processing complexity better capture the key differences between attested, natural systems and unattested but possible ones, including "optimal" recursive numeral systems from previous work, and that the ad-hoc constraints from previous literature naturally follow from regularity. Our approach highlights the need to incorporate regularity across sets of forms in studies that attempt to measure and explain optimality in language.
Representations as Language: An Information-Theoretic Framework for Interpretability
Jun 04, 2024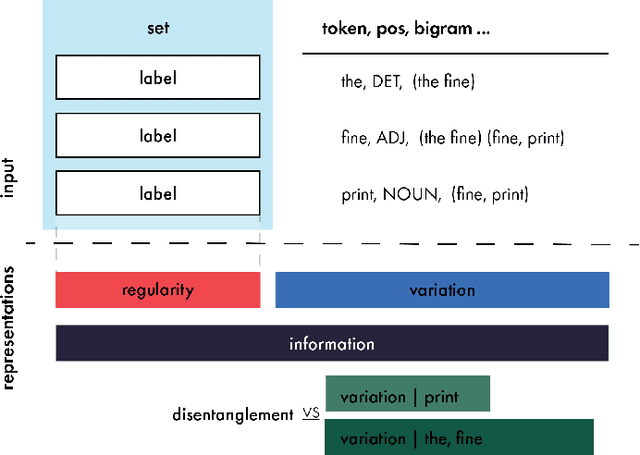



Large scale neural models show impressive performance across a wide array of linguistic tasks. Despite this they remain, largely, black-boxes - inducing vector-representations of their input that prove difficult to interpret. This limits our ability to understand what they learn, and when the learn it, or describe what kinds of representations generalise well out of distribution. To address this we introduce a novel approach to interpretability that looks at the mapping a model learns from sentences to representations as a kind of language in its own right. In doing so we introduce a set of information-theoretic measures that quantify how structured a model's representations are with respect to its input, and when during training that structure arises. Our measures are fast to compute, grounded in linguistic theory, and can predict which models will generalise best based on their representations. We use these measures to describe two distinct phases of training a transformer: an initial phase of in-distribution learning which reduces task loss, then a second stage where representations becoming robust to noise. Generalisation performance begins to increase during this second phase, drawing a link between generalisation and robustness to noise. Finally we look at how model size affects the structure of the representational space, showing that larger models ultimately compress their representations more than their smaller counterparts.
Sample Relationship from Learning Dynamics Matters for Generalisation
Jan 16, 2024



Although much research has been done on proposing new models or loss functions to improve the generalisation of artificial neural networks (ANNs), less attention has been directed to the impact of the training data on generalisation. In this work, we start from approximating the interaction between samples, i.e. how learning one sample would modify the model's prediction on other samples. Through analysing the terms involved in weight updates in supervised learning, we find that labels influence the interaction between samples. Therefore, we propose the labelled pseudo Neural Tangent Kernel (lpNTK) which takes label information into consideration when measuring the interactions between samples. We first prove that lpNTK asymptotically converges to the empirical neural tangent kernel in terms of the Frobenius norm under certain assumptions. Secondly, we illustrate how lpNTK helps to understand learning phenomena identified in previous work, specifically the learning difficulty of samples and forgetting events during learning. Moreover, we also show that using lpNTK to identify and remove poisoning training samples does not hurt the generalisation performance of ANNs.
Reliable identification of selection mechanisms in language change
May 25, 2023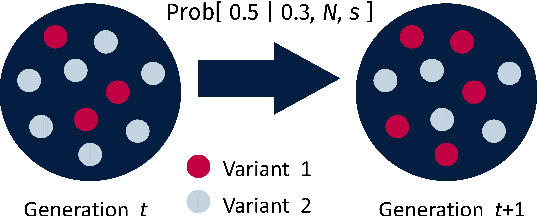
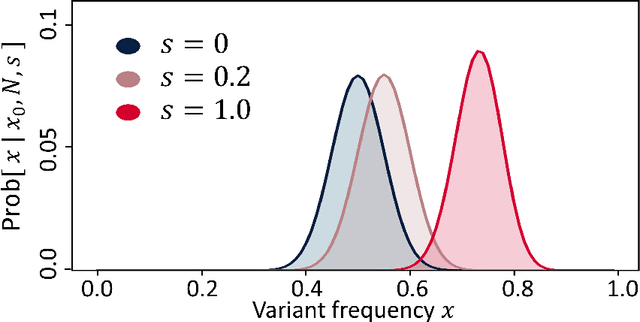

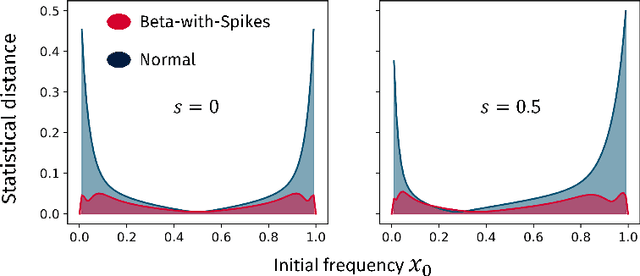
Language change is a cultural evolutionary process in which variants of linguistic variables change in frequency through processes analogous to mutation, selection and genetic drift. In this work, we apply a recently-introduced method to corpus data to quantify the strength of selection in specific instances of historical language change. We first demonstrate, in the context of English irregular verbs, that this method is more reliable and interpretable than similar methods that have previously been applied. We further extend this study to demonstrate that a bias towards phonological simplicity overrides that favouring grammatical simplicity when these are in conflict. Finally, with reference to Spanish spelling reforms, we show that the method can also detect points in time at which selection strengths change, a feature that is generically expected for socially-motivated language change. Together, these results indicate how hypotheses for mechanisms of language change can be tested quantitatively using historical corpus data.
Meta-Learning to Compositionally Generalize
Jun 29, 2021

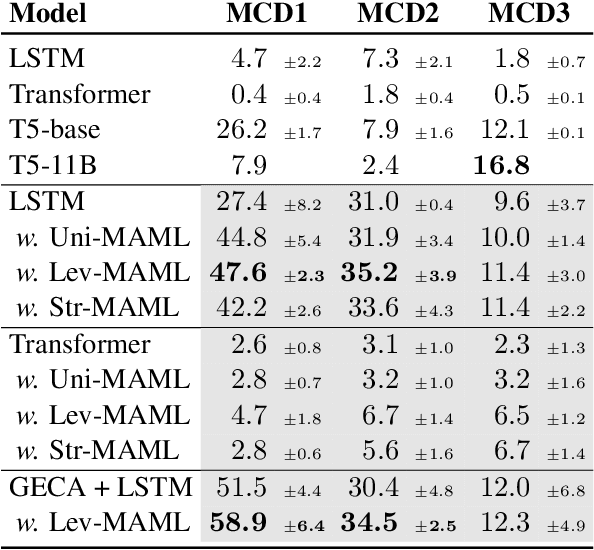
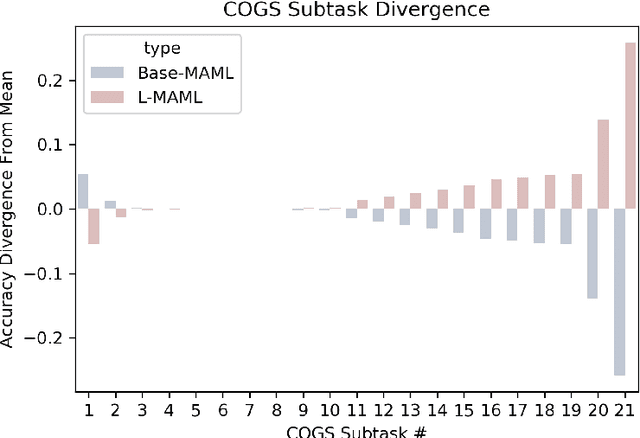
Natural language is compositional; the meaning of a sentence is a function of the meaning of its parts. This property allows humans to create and interpret novel sentences, generalizing robustly outside their prior experience. Neural networks have been shown to struggle with this kind of generalization, in particular performing poorly on tasks designed to assess compositional generalization (i.e. where training and testing distributions differ in ways that would be trivial for a compositional strategy to resolve). Their poor performance on these tasks may in part be due to the nature of supervised learning which assumes training and testing data to be drawn from the same distribution. We implement a meta-learning augmented version of supervised learning whose objective directly optimizes for out-of-distribution generalization. We construct pairs of tasks for meta-learning by sub-sampling existing training data. Each pair of tasks is constructed to contain relevant examples, as determined by a similarity metric, in an effort to inhibit models from memorizing their input. Experimental results on the COGS and SCAN datasets show that our similarity-driven meta-learning can improve generalization performance.
Expressivity of Emergent Language is a Trade-off between Contextual Complexity and Unpredictability
Jun 07, 2021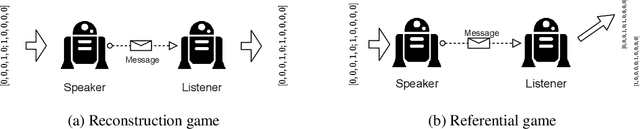

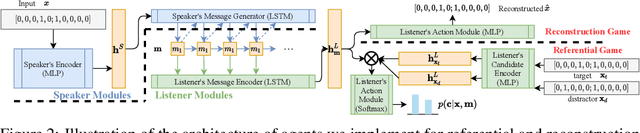

Researchers are now using deep learning models to explore the emergence of language in various language games, where simulated agents interact and develop an emergent language to solve a task. Although it is quite intuitive that different types of language games posing different communicative challenges might require emergent languages which encode different levels of information, there is no existing work exploring the expressivity of the emergent languages. In this work, we propose a definition of partial order between expressivity based on the generalisation performance across different language games. We also validate the hypothesis that expressivity of emergent languages is a trade-off between the complexity and unpredictability of the context those languages are used in. Our second novel contribution is introducing contrastive loss into the implementation of referential games. We show that using our contrastive loss alleviates the collapse of message types seen using standard referential loss functions.
From partners to populations: A hierarchical Bayesian account of coordination and convention
Apr 12, 2021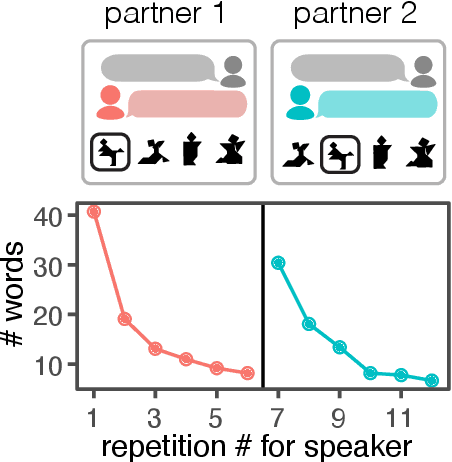
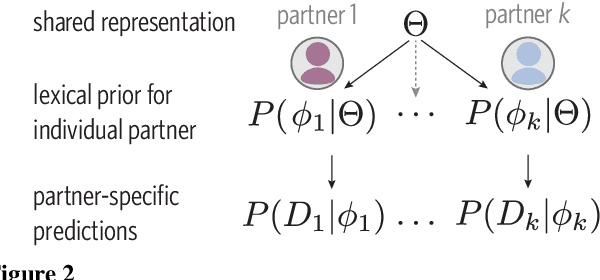
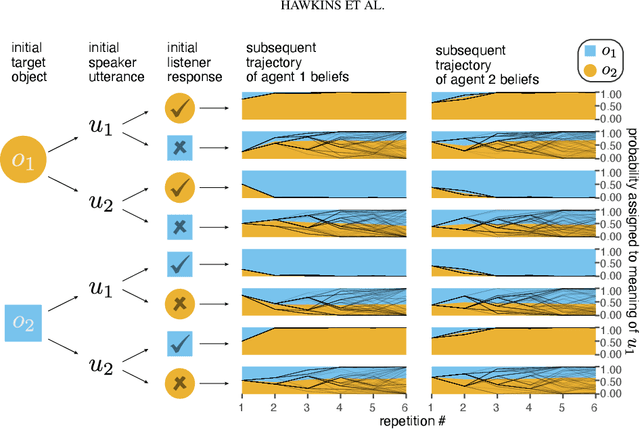
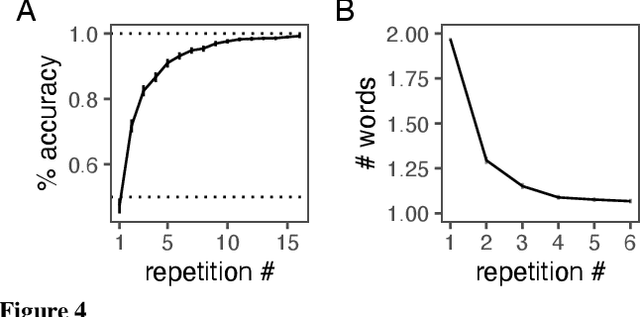
Languages are powerful solutions to coordination problems: they provide stable, shared expectations about how the words we say correspond to the beliefs and intentions in our heads. Yet language use in a variable and non-stationary social environment requires linguistic representations to be flexible: old words acquire new ad hoc or partner-specific meanings on the fly. In this paper, we introduce a hierarchical Bayesian theory of convention formation that aims to reconcile the long-standing tension between these two basic observations. More specifically, we argue that the central computational problem of communication is not simply transmission, as in classical formulations, but learning and adaptation over multiple timescales. Under our account, rapid learning within dyadic interactions allows for coordination on partner-specific common ground, while social conventions are stable priors that have been abstracted away from interactions with multiple partners. We present new empirical data alongside simulations showing how our model provides a cognitive foundation for explaining several phenomena that have posed a challenge for previous accounts: (1) the convergence to more efficient referring expressions across repeated interaction with the same partner, (2) the gradual transfer of partner-specific common ground to novel partners, and (3) the influence of communicative context on which conventions eventually form.
Conceptual similarity and communicative need shape colexification: an experimental study
Mar 19, 2021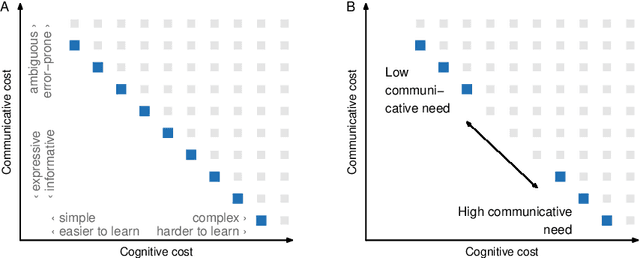
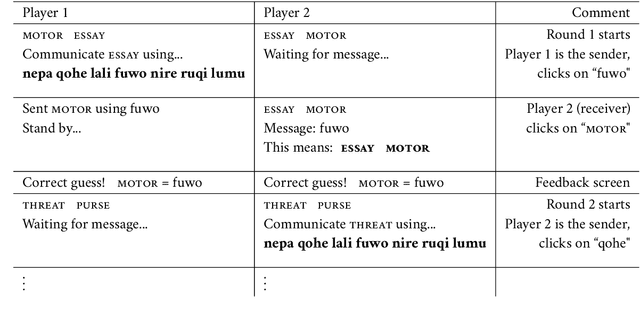
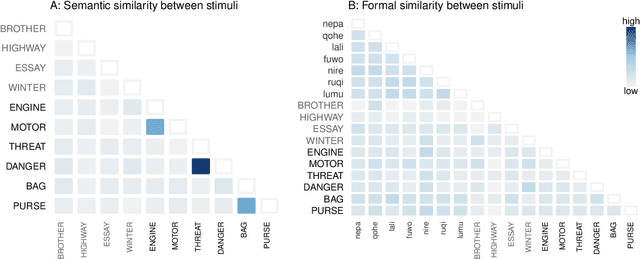

Colexification refers to the phenomenon of multiple meanings sharing one word in a language. Cross-linguistic lexification patterns have been shown to be largely predictable, as similar concepts are often colexified. We test a recent claim that, beyond this general tendency, communicative needs play an important role in shaping colexification patterns. We approach this question by means of a series of human experiments, using an artificial language communication game paradigm. Our results across four experiments match the previous cross-linguistic findings: all other things being equal, speakers do prefer to colexify similar concepts. However, we also find evidence supporting the communicative need hypothesis: when faced with a frequent need to distinguish similar pairs of meanings, speakers adjust their colexification preferences to maintain communicative efficiency, and avoid colexifying those similar meanings which need to be distinguished in communication. This research provides further evidence to support the argument that languages are shaped by the needs and preferences of their speakers.
Communicative need modulates competition in language change
Jun 16, 2020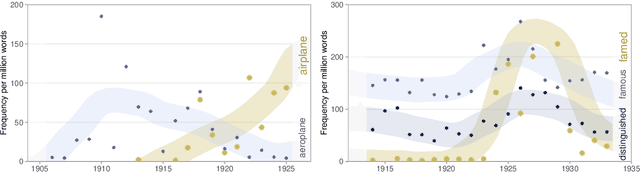
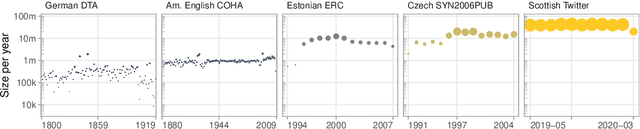
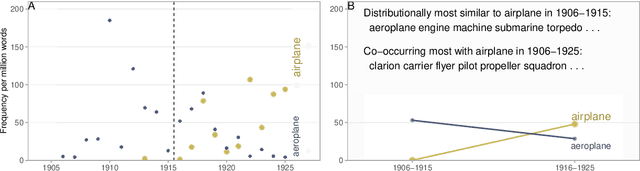
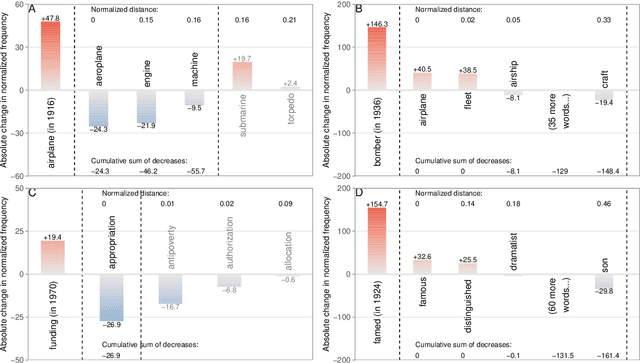
All living languages change over time. The causes for this are many, one being the emergence and borrowing of new linguistic elements. Competition between the new elements and older ones with a similar semantic or grammatical function may lead to speakers preferring one of them, and leaving the other to go out of use. We introduce a general method for quantifying competition between linguistic elements in diachronic corpora which does not require language-specific resources other than a sufficiently large corpus. This approach is readily applicable to a wide range of languages and linguistic subsystems. Here, we apply it to lexical data in five corpora differing in language, type, genre, and time span. We find that changes in communicative need are consistently predictive of lexical competition dynamics. Near-synonymous words are more likely to directly compete if they belong to a topic of conversation whose importance to language users is constant over time, possibly leading to the extinction of one of the competing words. By contrast, in topics which are increasing in importance for language users, near-synonymous words tend not to compete directly and can coexist. This suggests that, in addition to direct competition between words, language change can be driven by competition between topics or semantic subspaces.