 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSerendipity by Design: Evaluating the Impact of Cross-domain Mappings on Human and LLM Creativity
Mar 19, 2026Are large language models (LLMs) creative in the same way humans are, and can the same interventions increase creativity in both? We evaluate a promising but largely untested intervention for creativity: forcing creators to draw an analogy from a random, remote source domain (''cross-domain mapping''). Human participants and LLMs generated novel features for ten daily products (e.g., backpack, TV) under two prompts: (i) cross-domain mapping, which required translating a property from a randomly assigned source (e.g., octopus, cactus, GPS), and (ii) user-need, which required proposing innovations targeting unmet user needs. We show that humans reliably benefit from randomly assigned cross-domain mappings, while LLMs, on average, generate more original ideas than humans and do not show a statistically significant effect of cross-domain mappings. However, in both systems, the impact of cross-domain mapping increases when the inspiration source becomes more semantically distant from the target. Our results highlight both the role of remote association in creative ideation and systematic differences in how humans and LLMs respond to the same intervention for creativity.
Information Structure in Mappings: An Approach to Learning, Representation, and Generalisation
May 29, 2025Despite the remarkable success of large large-scale neural networks, we still lack unified notation for thinking about and describing their representational spaces. We lack methods to reliably describe how their representations are structured, how that structure emerges over training, and what kinds of structures are desirable. This thesis introduces quantitative methods for identifying systematic structure in a mapping between spaces, and leverages them to understand how deep-learning models learn to represent information, what representational structures drive generalisation, and how design decisions condition the structures that emerge. To do this I identify structural primitives present in a mapping, along with information theoretic quantifications of each. These allow us to analyse learning, structure, and generalisation across multi-agent reinforcement learning models, sequence-to-sequence models trained on a single task, and Large Language Models. I also introduce a novel, performant, approach to estimating the entropy of vector space, that allows this analysis to be applied to models ranging in size from 1 million to 12 billion parameters. The experiments here work to shed light on how large-scale distributed models of cognition learn, while allowing us to draw parallels between those systems and their human analogs. They show how the structures of language and the constraints that give rise to them in many ways parallel the kinds of structures that drive performance of contemporary neural networks.
Causal Head Gating: A Framework for Interpreting Roles of Attention Heads in Transformers
May 19, 2025We present causal head gating (CHG), a scalable method for interpreting the functional roles of attention heads in transformer models. CHG learns soft gates over heads and assigns them a causal taxonomy - facilitating, interfering, or irrelevant - based on their impact on task performance. Unlike prior approaches in mechanistic interpretability, which are hypothesis-driven and require prompt templates or target labels, CHG applies directly to any dataset using standard next-token prediction. We evaluate CHG across multiple large language models (LLMs) in the Llama 3 model family and diverse tasks, including syntax, commonsense, and mathematical reasoning, and show that CHG scores yield causal - not merely correlational - insight, validated via ablation and causal mediation analyses. We also introduce contrastive CHG, a variant that isolates sub-circuits for specific task components. Our findings reveal that LLMs contain multiple sparse, sufficient sub-circuits, that individual head roles depend on interactions with others (low modularity), and that instruction following and in-context learning rely on separable mechanisms.
Command A: An Enterprise-Ready Large Language Model
Apr 01, 2025



In this report we describe the development of Command A, a powerful large language model purpose-built to excel at real-world enterprise use cases. Command A is an agent-optimised and multilingual-capable model, with support for 23 languages of global business, and a novel hybrid architecture balancing efficiency with top of the range performance. It offers best-in-class Retrieval Augmented Generation (RAG) capabilities with grounding and tool use to automate sophisticated business processes. These abilities are achieved through a decentralised training approach, including self-refinement algorithms and model merging techniques. We also include results for Command R7B which shares capability and architectural similarities to Command A. Weights for both models have been released for research purposes. This technical report details our original training pipeline and presents an extensive evaluation of our models across a suite of enterprise-relevant tasks and public benchmarks, demonstrating excellent performance and efficiency.
Compositional Generalization Across Distributional Shifts with Sparse Tree Operations
Dec 18, 2024Neural networks continue to struggle with compositional generalization, and this issue is exacerbated by a lack of massive pre-training. One successful approach for developing neural systems which exhibit human-like compositional generalization is \textit{hybrid} neurosymbolic techniques. However, these techniques run into the core issues that plague symbolic approaches to AI: scalability and flexibility. The reason for this failure is that at their core, hybrid neurosymbolic models perform symbolic computation and relegate the scalable and flexible neural computation to parameterizing a symbolic system. We investigate a \textit{unified} neurosymbolic system where transformations in the network can be interpreted simultaneously as both symbolic and neural computation. We extend a unified neurosymbolic architecture called the Differentiable Tree Machine in two central ways. First, we significantly increase the model's efficiency through the use of sparse vector representations of symbolic structures. Second, we enable its application beyond the restricted set of tree2tree problems to the more general class of seq2seq problems. The improved model retains its prior generalization capabilities and, since there is a fully neural path through the network, avoids the pitfalls of other neurosymbolic techniques that elevate symbolic computation over neural computation.
Representations as Language: An Information-Theoretic Framework for Interpretability
Jun 04, 2024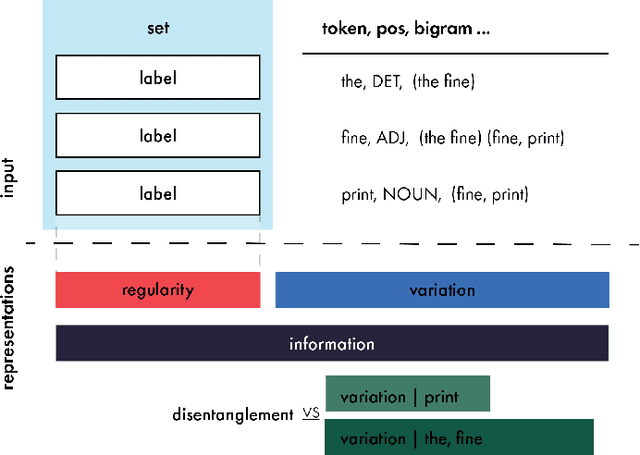



Large scale neural models show impressive performance across a wide array of linguistic tasks. Despite this they remain, largely, black-boxes - inducing vector-representations of their input that prove difficult to interpret. This limits our ability to understand what they learn, and when the learn it, or describe what kinds of representations generalise well out of distribution. To address this we introduce a novel approach to interpretability that looks at the mapping a model learns from sentences to representations as a kind of language in its own right. In doing so we introduce a set of information-theoretic measures that quantify how structured a model's representations are with respect to its input, and when during training that structure arises. Our measures are fast to compute, grounded in linguistic theory, and can predict which models will generalise best based on their representations. We use these measures to describe two distinct phases of training a transformer: an initial phase of in-distribution learning which reduces task loss, then a second stage where representations becoming robust to noise. Generalisation performance begins to increase during this second phase, drawing a link between generalisation and robustness to noise. Finally we look at how model size affects the structure of the representational space, showing that larger models ultimately compress their representations more than their smaller counterparts.
Anaphoric Structure Emerges Between Neural Networks
Aug 15, 2023



Pragmatics is core to natural language, enabling speakers to communicate efficiently with structures like ellipsis and anaphora that can shorten utterances without loss of meaning. These structures require a listener to interpret an ambiguous form - like a pronoun - and infer the speaker's intended meaning - who that pronoun refers to. Despite potential to introduce ambiguity, anaphora is ubiquitous across human language. In an effort to better understand the origins of anaphoric structure in natural language, we look to see if analogous structures can emerge between artificial neural networks trained to solve a communicative task. We show that: first, despite the potential for increased ambiguity, languages with anaphoric structures are learnable by neural models. Second, anaphoric structures emerge between models 'naturally' without need for additional constraints. Finally, introducing an explicit efficiency pressure on the speaker increases the prevalence of these structures. We conclude that certain pragmatic structures straightforwardly emerge between neural networks, without explicit efficiency pressures, but that the competing needs of speakers and listeners conditions the degree and nature of their emergence.
Meta-Learning to Compositionally Generalize
Jun 29, 2021

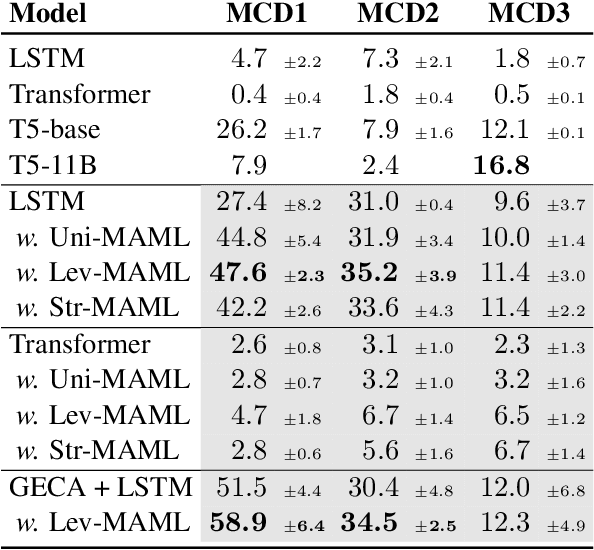
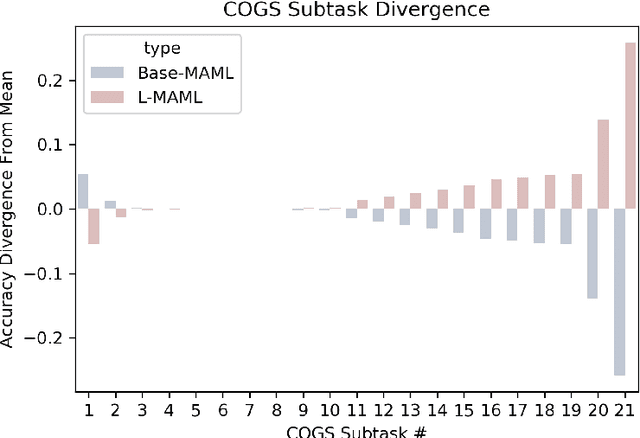
Natural language is compositional; the meaning of a sentence is a function of the meaning of its parts. This property allows humans to create and interpret novel sentences, generalizing robustly outside their prior experience. Neural networks have been shown to struggle with this kind of generalization, in particular performing poorly on tasks designed to assess compositional generalization (i.e. where training and testing distributions differ in ways that would be trivial for a compositional strategy to resolve). Their poor performance on these tasks may in part be due to the nature of supervised learning which assumes training and testing data to be drawn from the same distribution. We implement a meta-learning augmented version of supervised learning whose objective directly optimizes for out-of-distribution generalization. We construct pairs of tasks for meta-learning by sub-sampling existing training data. Each pair of tasks is constructed to contain relevant examples, as determined by a similarity metric, in an effort to inhibit models from memorizing their input. Experimental results on the COGS and SCAN datasets show that our similarity-driven meta-learning can improve generalization performance.