 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCommand A: An Enterprise-Ready Large Language Model
Apr 01, 2025



In this report we describe the development of Command A, a powerful large language model purpose-built to excel at real-world enterprise use cases. Command A is an agent-optimised and multilingual-capable model, with support for 23 languages of global business, and a novel hybrid architecture balancing efficiency with top of the range performance. It offers best-in-class Retrieval Augmented Generation (RAG) capabilities with grounding and tool use to automate sophisticated business processes. These abilities are achieved through a decentralised training approach, including self-refinement algorithms and model merging techniques. We also include results for Command R7B which shares capability and architectural similarities to Command A. Weights for both models have been released for research purposes. This technical report details our original training pipeline and presents an extensive evaluation of our models across a suite of enterprise-relevant tasks and public benchmarks, demonstrating excellent performance and efficiency.
Replacing Judges with Juries: Evaluating LLM Generations with a Panel of Diverse Models
May 01, 2024



As Large Language Models (LLMs) have become more advanced, they have outpaced our abilities to accurately evaluate their quality. Not only is finding data to adequately probe particular model properties difficult, but evaluating the correctness of a model's freeform generation alone is a challenge. To address this, many evaluations now rely on using LLMs themselves as judges to score the quality of outputs from other LLMs. Evaluations most commonly use a single large model like GPT4. While this method has grown in popularity, it is costly, has been shown to introduce intramodel bias, and in this work, we find that very large models are often unnecessary. We propose instead to evaluate models using a Panel of LLm evaluators (PoLL). Across three distinct judge settings and spanning six different datasets, we find that using a PoLL composed of a larger number of smaller models outperforms a single large judge, exhibits less intra-model bias due to its composition of disjoint model families, and does so while being over seven times less expensive.
Two Approaches to Building Collaborative, Task-Oriented Dialog Agents through Self-Play
Sep 20, 2021
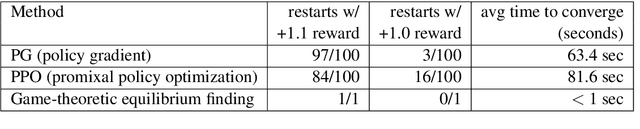
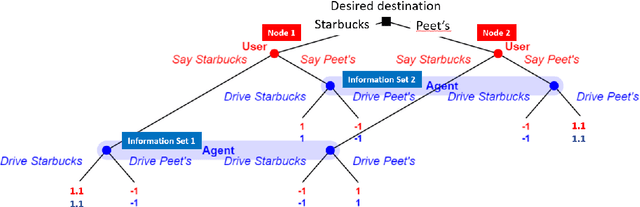
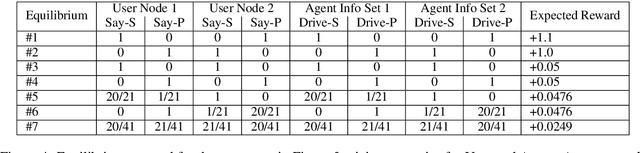
Task-oriented dialog systems are often trained on human/human dialogs, such as collected from Wizard-of-Oz interfaces. However, human/human corpora are frequently too small for supervised training to be effective. This paper investigates two approaches to training agent-bots and user-bots through self-play, in which they autonomously explore an API environment, discovering communication strategies that enable them to solve the task. We give empirical results for both reinforcement learning and game-theoretic equilibrium finding.
MeetDot: Videoconferencing with Live Translation Captions
Sep 20, 2021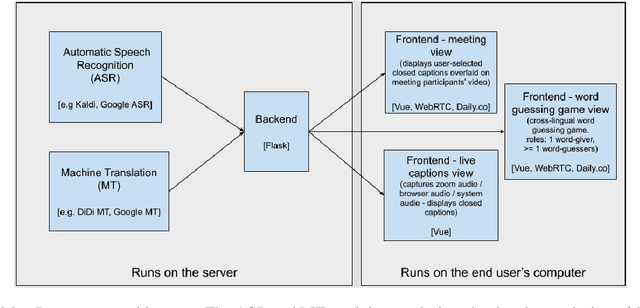

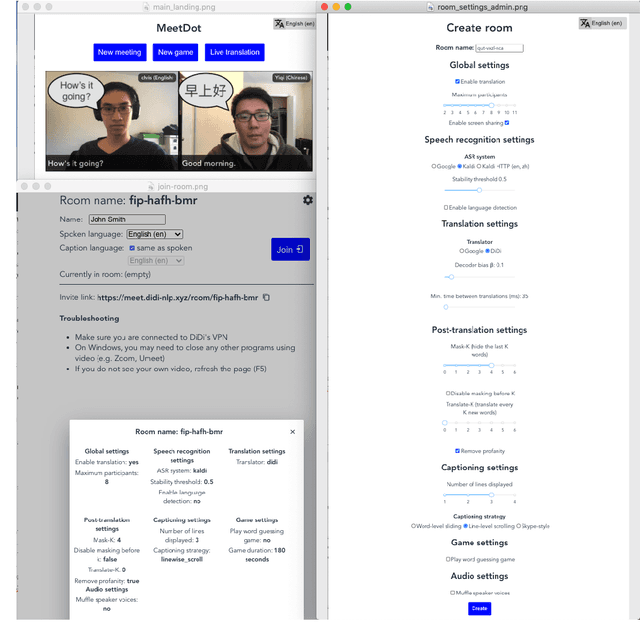
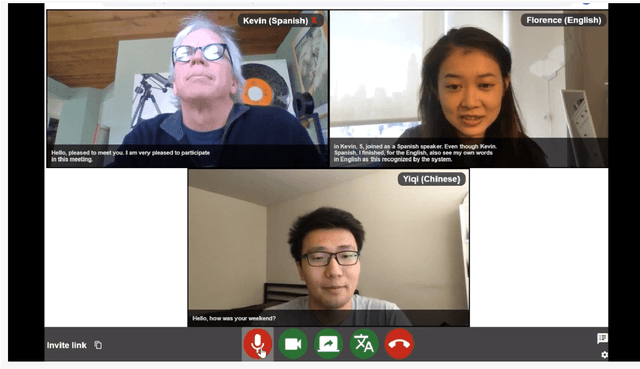
We present MeetDot, a videoconferencing system with live translation captions overlaid on screen. The system aims to facilitate conversation between people who speak different languages, thereby reducing communication barriers between multilingual participants. Currently, our system supports speech and captions in 4 languages and combines automatic speech recognition (ASR) and machine translation (MT) in a cascade. We use the re-translation strategy to translate the streamed speech, resulting in caption flicker. Additionally, our system has very strict latency requirements to have acceptable call quality. We implement several features to enhance user experience and reduce their cognitive load, such as smooth scrolling captions and reducing caption flicker. The modular architecture allows us to integrate different ASR and MT services in our backend. Our system provides an integrated evaluation suite to optimize key intrinsic evaluation metrics such as accuracy, latency and erasure. Finally, we present an innovative cross-lingual word-guessing game as an extrinsic evaluation metric to measure end-to-end system performance. We plan to make our system open-source for research purposes.
MEEP: An Open-Source Platform for Human-Human Dialog Collection and End-to-End Agent Training
Oct 09, 2020
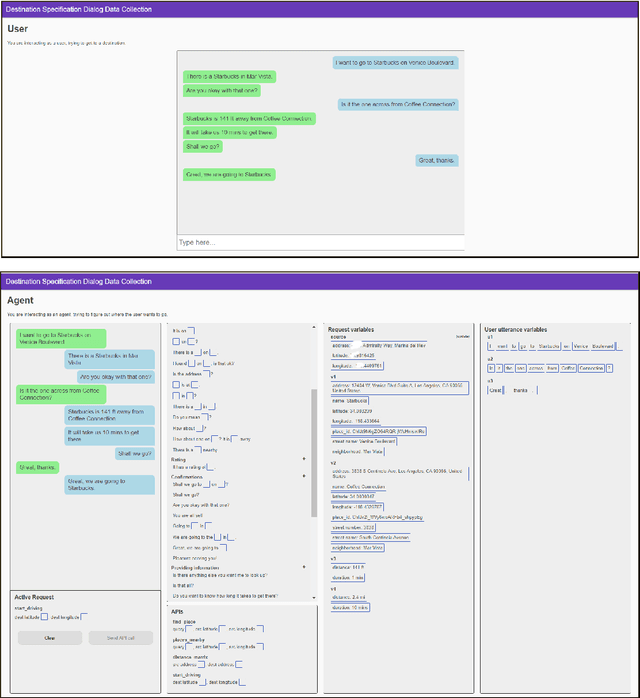


We create a new task-oriented dialog platform (MEEP) where agents are given considerable freedom in terms of utterances and API calls, but are constrained to work within a push-button environment. We include facilities for collecting human-human dialog corpora, and for training automatic agents in an end-to-end fashion. We demonstrate MEEP with a dialog assistant that lets users specify trip destinations.
Zeus: A System Description of the Two-Time Winner of the Collegiate SAE AutoDrive Competition
Apr 19, 2020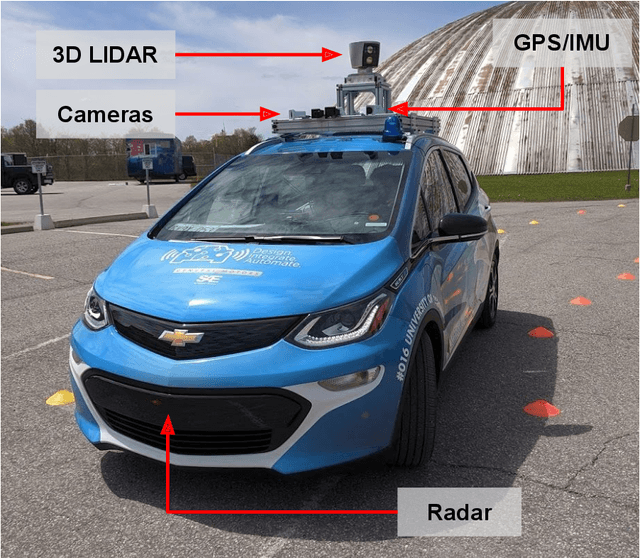


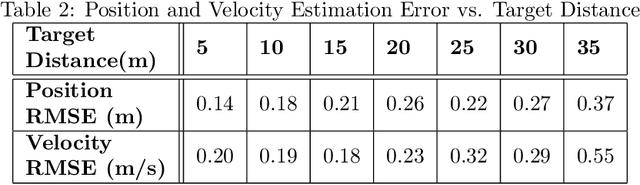
The SAE AutoDrive Challenge is a three-year collegiate competition to develop a self-driving car by 2020. The second year of the competition was held in June 2019 at MCity, a mock town built for self-driving car testing at the University of Michigan. Teams were required to autonomously navigate a series of intersections while handling pedestrians, traffic lights, and traffic signs. Zeus is aUToronto's winning entry in the AutoDrive Challenge. This article describes the system design and development of Zeus as well as many of the lessons learned along the way. This includes details on the team's organizational structure, sensor suite, software components, and performance at the Year 2 competition. With a team of mostly undergraduates and minimal resources, aUToronto has made progress towards a functioning self-driving vehicle, in just two years. This article may prove valuable to researchers looking to develop their own self-driving platform.