 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCommand A: An Enterprise-Ready Large Language Model
Apr 01, 2025



In this report we describe the development of Command A, a powerful large language model purpose-built to excel at real-world enterprise use cases. Command A is an agent-optimised and multilingual-capable model, with support for 23 languages of global business, and a novel hybrid architecture balancing efficiency with top of the range performance. It offers best-in-class Retrieval Augmented Generation (RAG) capabilities with grounding and tool use to automate sophisticated business processes. These abilities are achieved through a decentralised training approach, including self-refinement algorithms and model merging techniques. We also include results for Command R7B which shares capability and architectural similarities to Command A. Weights for both models have been released for research purposes. This technical report details our original training pipeline and presents an extensive evaluation of our models across a suite of enterprise-relevant tasks and public benchmarks, demonstrating excellent performance and efficiency.
Replacing Judges with Juries: Evaluating LLM Generations with a Panel of Diverse Models
May 01, 2024



As Large Language Models (LLMs) have become more advanced, they have outpaced our abilities to accurately evaluate their quality. Not only is finding data to adequately probe particular model properties difficult, but evaluating the correctness of a model's freeform generation alone is a challenge. To address this, many evaluations now rely on using LLMs themselves as judges to score the quality of outputs from other LLMs. Evaluations most commonly use a single large model like GPT4. While this method has grown in popularity, it is costly, has been shown to introduce intramodel bias, and in this work, we find that very large models are often unnecessary. We propose instead to evaluate models using a Panel of LLm evaluators (PoLL). Across three distinct judge settings and spanning six different datasets, we find that using a PoLL composed of a larger number of smaller models outperforms a single large judge, exhibits less intra-model bias due to its composition of disjoint model families, and does so while being over seven times less expensive.
Neural Datalog Through Time: Informed Temporal Modeling via Logical Specification
Jun 30, 2020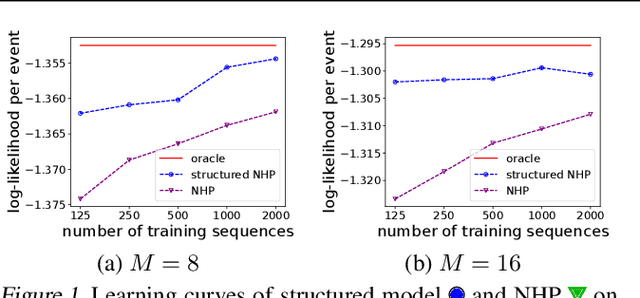
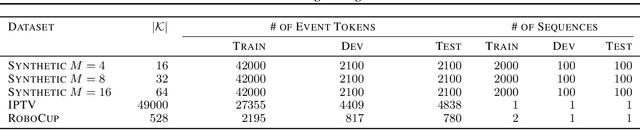
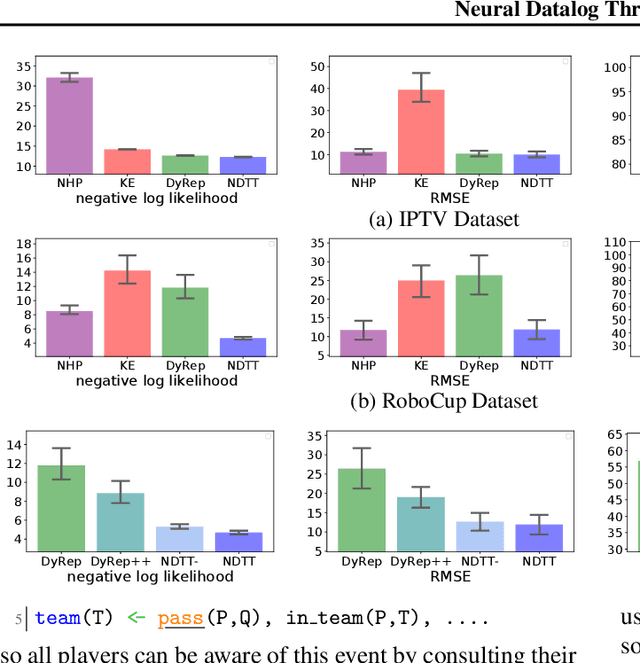
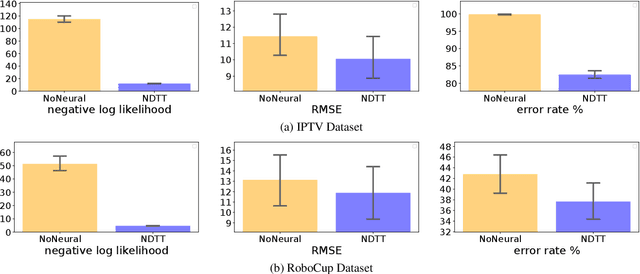
Learning how to predict future events from patterns of past events is difficult when the set of possible event types is large. Training an unrestricted neural model might overfit to spurious patterns. To exploit domain-specific knowledge of how past events might affect an event's present probability, we propose using a temporal deductive database to track structured facts over time. Rules serve to prove facts from other facts and from past events. Each fact has a time-varying state---a vector computed by a neural net whose topology is determined by the fact's provenance, including its experience of past events. The possible event types at any time are given by special facts, whose probabilities are neurally modeled alongside their states. In both synthetic and real-world domains, we show that neural probabilistic models derived from concise Datalog programs improve prediction by encoding appropriate domain knowledge in their architecture.
NSTM: Real-Time Query-Driven News Overview Composition at Bloomberg
Jun 01, 2020

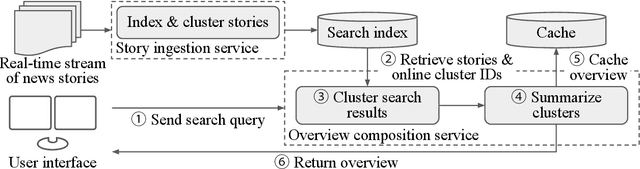

Millions of news articles from hundreds of thousands of sources around the globe appear in news aggregators every day. Consuming such a volume of news presents an almost insurmountable challenge. For example, a reader searching on Bloomberg's system for news about the U.K. would find 10,000 articles on a typical day. Apple Inc., the world's most journalistically covered company, garners around 1,800 news articles a day. We realized that a new kind of summarization engine was needed, one that would condense large volumes of news into short, easy to absorb points. The system would filter out noise and duplicates to identify and summarize key news about companies, countries or markets. When given a user query, Bloomberg's solution, Key News Themes (or NSTM), leverages state-of-the-art semantic clustering techniques and novel summarization methods to produce comprehensive, yet concise, digests to dramatically simplify the news consumption process. NSTM is available to hundreds of thousands of readers around the world and serves thousands of requests daily with sub-second latency. At ACL 2020, we will present a demo of NSTM.
Understanding Goal-Oriented Active Learning via Influence Functions
May 30, 2019
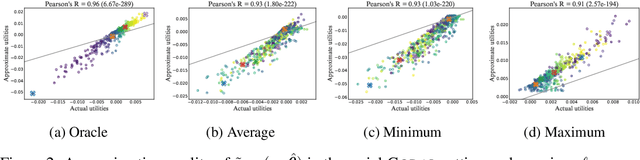
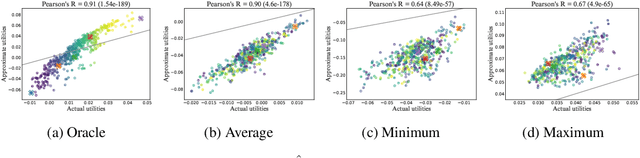
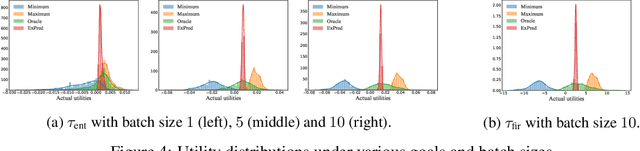
Active learning (AL) concerns itself with learning a model from as few labelled data as possible through actively and iteratively querying an oracle with selected unlabelled samples. In this paper, we focus on a popular type of AL in which the utility of a sample is measured by a specified goal achieved by the retrained model after accounting for the sample's marginal influence. Such AL strategies attract a lot of attention thanks to their intuitive motivations, yet they typically suffer from impractically high computational costs due to their need for many iterations of model retraining. With the help of influence functions, we present an effective approximation that bypasses model retraining altogether, and propose a general efficient implementation that makes such AL strategies applicable in practice, both in the serial and the more challenging batch-mode setting. Additionally, we present theoretical analyses which call into question a common practice widely adopted in the field. Finally, we carry out empirical studies with both synthetic and real-world datasets to validate our discoveries as well as showcase the potentials and issues with such goal-oriented AL strategies.
Fast Parallel SVM using Data Augmentation
Dec 24, 2015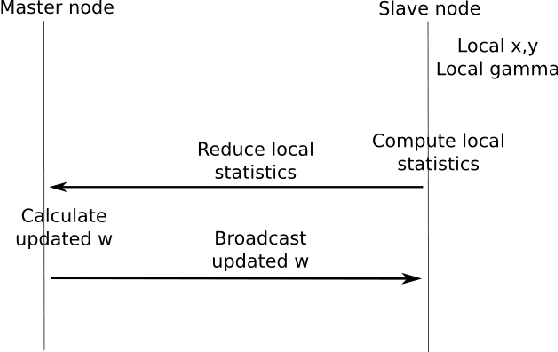
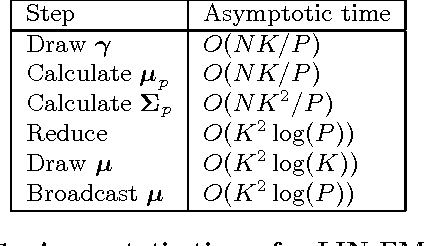

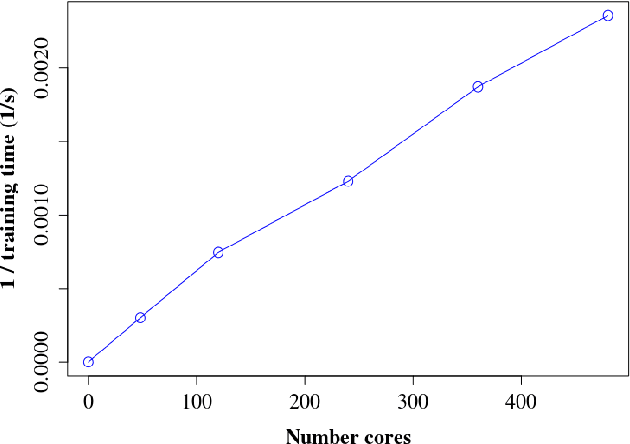
As one of the most popular classifiers, linear SVMs still have challenges in dealing with very large-scale problems, even though linear or sub-linear algorithms have been developed recently on single machines. Parallel computing methods have been developed for learning large-scale SVMs. However, existing methods rely on solving local sub-optimization problems. In this paper, we develop a novel parallel algorithm for learning large-scale linear SVM. Our approach is based on a data augmentation equivalent formulation, which casts the problem of learning SVM as a Bayesian inference problem, for which we can develop very efficient parallel sampling methods. We provide empirical results for this parallel sampling SVM, and provide extensions for SVR, non-linear kernels, and provide a parallel implementation of the Crammer and Singer model. This approach is very promising in its own right, and further is a very useful technique to parallelize a broader family of general maximum-margin models.