 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReplacing Judges with Juries: Evaluating LLM Generations with a Panel of Diverse Models
May 01, 2024



As Large Language Models (LLMs) have become more advanced, they have outpaced our abilities to accurately evaluate their quality. Not only is finding data to adequately probe particular model properties difficult, but evaluating the correctness of a model's freeform generation alone is a challenge. To address this, many evaluations now rely on using LLMs themselves as judges to score the quality of outputs from other LLMs. Evaluations most commonly use a single large model like GPT4. While this method has grown in popularity, it is costly, has been shown to introduce intramodel bias, and in this work, we find that very large models are often unnecessary. We propose instead to evaluate models using a Panel of LLm evaluators (PoLL). Across three distinct judge settings and spanning six different datasets, we find that using a PoLL composed of a larger number of smaller models outperforms a single large judge, exhibits less intra-model bias due to its composition of disjoint model families, and does so while being over seven times less expensive.
Improving Transformer-Kernel Ranking Model Using Conformer and Query Term Independence
Apr 19, 2021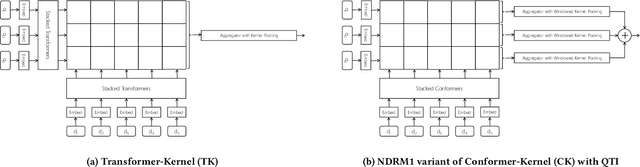
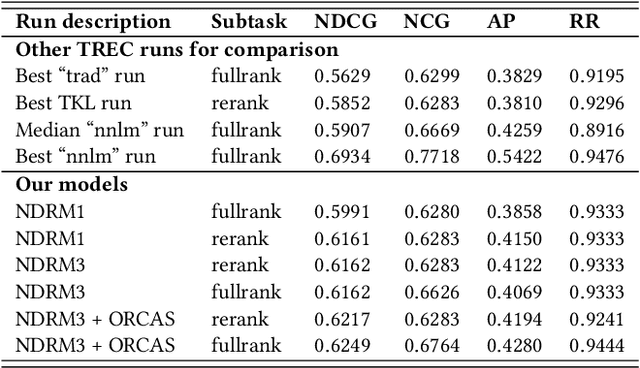


The Transformer-Kernel (TK) model has demonstrated strong reranking performance on the TREC Deep Learning benchmark -- and can be considered to be an efficient (but slightly less effective) alternative to other Transformer-based architectures that employ (i) large-scale pretraining (high training cost), (ii) joint encoding of query and document (high inference cost), and (iii) larger number of Transformer layers (both high training and high inference costs). Since, a variant of the TK model -- called TKL -- has been developed that incorporates local self-attention to efficiently process longer input sequences in the context of document ranking. In this work, we propose a novel Conformer layer as an alternative approach to scale TK to longer input sequences. Furthermore, we incorporate query term independence and explicit term matching to extend the model to the full retrieval setting. We benchmark our models under the strictly blind evaluation setting of the TREC 2020 Deep Learning track and find that our proposed architecture changes lead to improved retrieval quality over TKL. Our best model also outperforms all non-neural runs ("trad") and two-thirds of the pretrained Transformer-based runs ("nnlm") on NDCG@10.
Conformer-Kernel with Query Term Independence at TREC 2020 Deep Learning Track
Nov 14, 2020


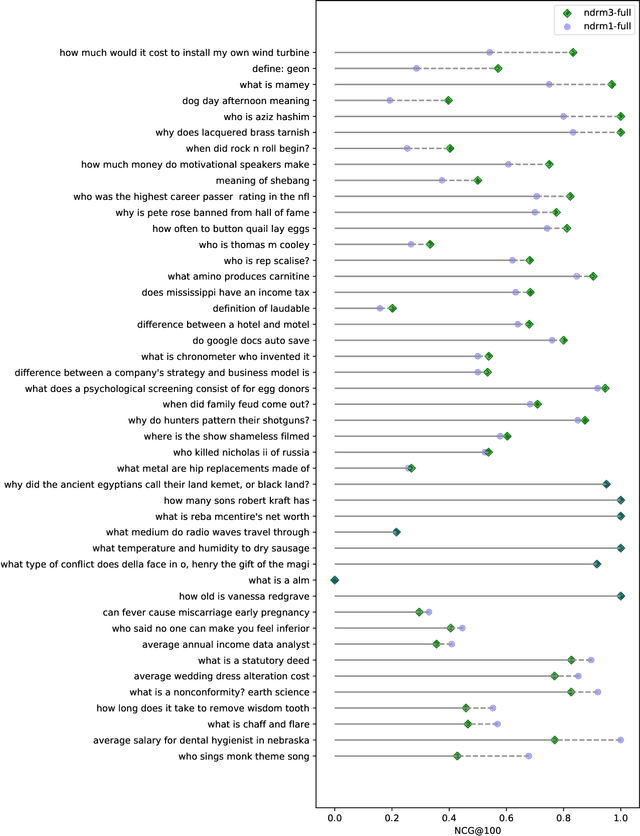
We benchmark Conformer-Kernel models under the strict blind evaluation setting of the TREC 2020 Deep Learning track. In particular, we study the impact of incorporating: (i) Explicit term matching to complement matching based on learned representations (i.e., the "Duet principle"), (ii) query term independence (i.e., the "QTI assumption") to scale the model to the full retrieval setting, and (iii) the ORCAS click data as an additional document description field. We find evidence which supports that all three aforementioned strategies can lead to improved retrieval quality.
Conformer-Kernel with Query Term Independence for Document Retrieval
Jul 20, 2020


The Transformer-Kernel (TK) model has demonstrated strong reranking performance on the TREC Deep Learning benchmark---and can be considered to be an efficient (but slightly less effective) alternative to BERT-based ranking models. In this work, we extend the TK architecture to the full retrieval setting by incorporating the query term independence assumption. Furthermore, to reduce the memory complexity of the Transformer layers with respect to the input sequence length, we propose a new Conformer layer. We show that the Conformer's GPU memory requirement scales linearly with input sequence length, making it a more viable option when ranking long documents. Finally, we demonstrate that incorporating explicit term matching signal into the model can be particularly useful in the full retrieval setting. We present preliminary results from our work in this paper.