 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOnline Nonconvex Bilevel Optimization with Bregman Divergences
Sep 16, 2024Bilevel optimization methods are increasingly relevant within machine learning, especially for tasks such as hyperparameter optimization and meta-learning. Compared to the offline setting, online bilevel optimization (OBO) offers a more dynamic framework by accommodating time-varying functions and sequentially arriving data. This study addresses the online nonconvex-strongly convex bilevel optimization problem. In deterministic settings, we introduce a novel online Bregman bilevel optimizer (OBBO) that utilizes adaptive Bregman divergences. We demonstrate that OBBO enhances the known sublinear rates for bilevel local regret through a novel hypergradient error decomposition that adapts to the underlying geometry of the problem. In stochastic contexts, we introduce the first stochastic online bilevel optimizer (SOBBO), which employs a window averaging method for updating outer-level variables using a weighted average of recent stochastic approximations of hypergradients. This approach not only achieves sublinear rates of bilevel local regret but also serves as an effective variance reduction strategy, obviating the need for additional stochastic gradient samples at each timestep. Experiments on online hyperparameter optimization and online meta-learning highlight the superior performance, efficiency, and adaptability of our Bregman-based algorithms compared to established online and offline bilevel benchmarks.
Understanding Goal-Oriented Active Learning via Influence Functions
May 30, 2019
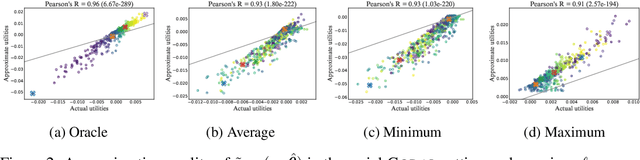
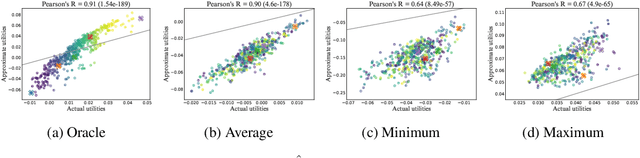
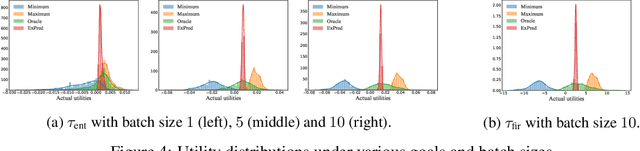
Active learning (AL) concerns itself with learning a model from as few labelled data as possible through actively and iteratively querying an oracle with selected unlabelled samples. In this paper, we focus on a popular type of AL in which the utility of a sample is measured by a specified goal achieved by the retrained model after accounting for the sample's marginal influence. Such AL strategies attract a lot of attention thanks to their intuitive motivations, yet they typically suffer from impractically high computational costs due to their need for many iterations of model retraining. With the help of influence functions, we present an effective approximation that bypasses model retraining altogether, and propose a general efficient implementation that makes such AL strategies applicable in practice, both in the serial and the more challenging batch-mode setting. Additionally, we present theoretical analyses which call into question a common practice widely adopted in the field. Finally, we carry out empirical studies with both synthetic and real-world datasets to validate our discoveries as well as showcase the potentials and issues with such goal-oriented AL strategies.