 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnderstanding Goal-Oriented Active Learning via Influence Functions
Paper and Code

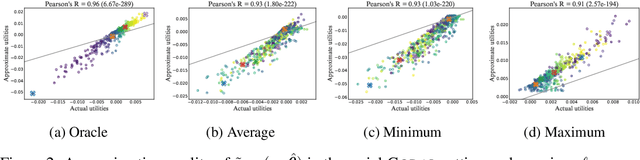
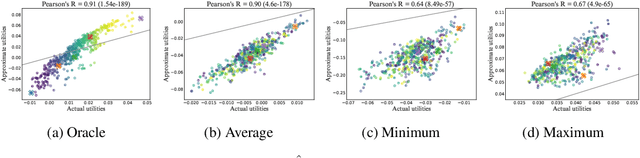
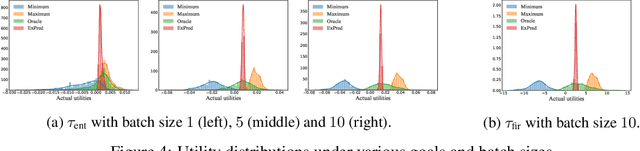
Active learning (AL) concerns itself with learning a model from as few labelled data as possible through actively and iteratively querying an oracle with selected unlabelled samples. In this paper, we focus on a popular type of AL in which the utility of a sample is measured by a specified goal achieved by the retrained model after accounting for the sample's marginal influence. Such AL strategies attract a lot of attention thanks to their intuitive motivations, yet they typically suffer from impractically high computational costs due to their need for many iterations of model retraining. With the help of influence functions, we present an effective approximation that bypasses model retraining altogether, and propose a general efficient implementation that makes such AL strategies applicable in practice, both in the serial and the more challenging batch-mode setting. Additionally, we present theoretical analyses which call into question a common practice widely adopted in the field. Finally, we carry out empirical studies with both synthetic and real-world datasets to validate our discoveries as well as showcase the potentials and issues with such goal-oriented AL strategies.