 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTexRel: a Green Family of Datasets for Emergent Communications on Relations
May 26, 2021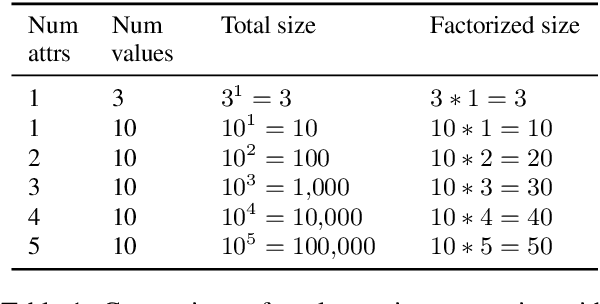

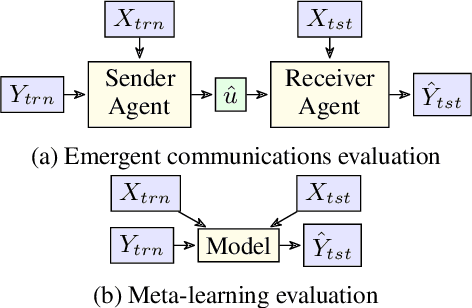
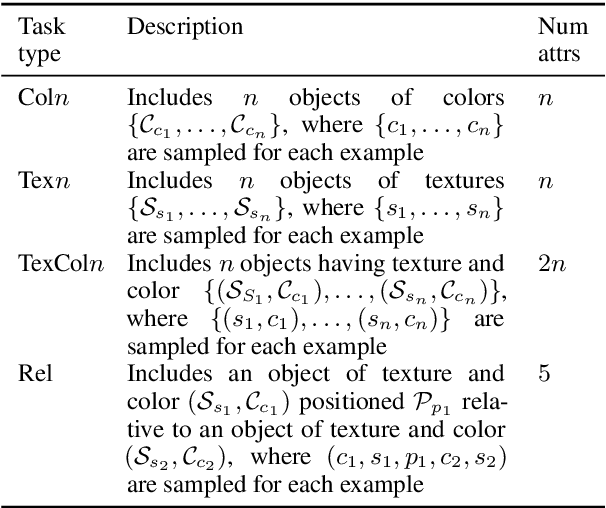
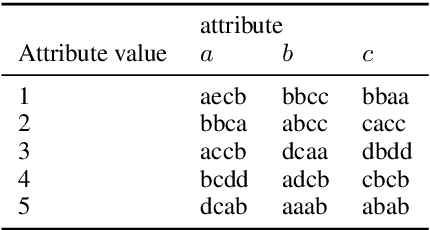
We propose a new dataset TexRel as a playground for the study of emergent communications, in particular for relations. By comparison with other relations datasets, TexRel provides rapid training and experimentation, whilst being sufficiently large to avoid overfitting in the context of emergent communications. By comparison with using symbolic inputs, TexRel provides a more realistic alternative whilst remaining efficient and fast to learn. We compare the performance of TexRel with a related relations dataset Shapeworld. We provide baseline performance results on TexRel for sender architectures, receiver architectures and end-to-end architectures. We examine the effect of multitask learning in the context of shapes, colors and relations on accuracy, topological similarity and clustering precision. We investigate whether increasing the size of the latent meaning space improves metrics of compositionality. We carry out a case-study on using TexRel to reproduce the results of an experiment in a recent paper that used symbolic inputs, but using our own non-symbolic inputs, from TexRel, instead.
A Framework for Measuring Compositional Inductive Bias
Mar 06, 2021
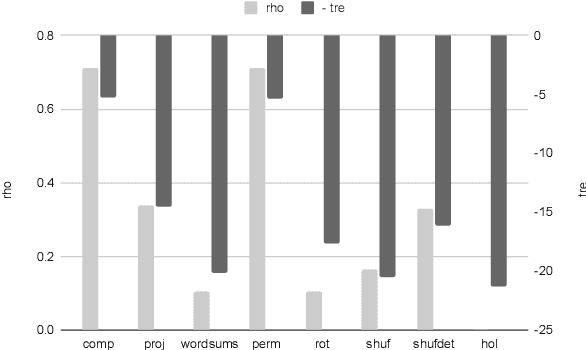
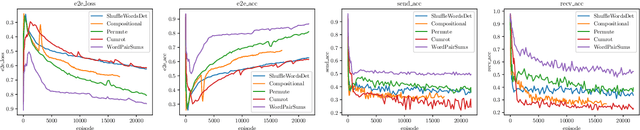
We present a framework for measuring the compositional inductive bias of models in the context of emergent communications. We devise corrupted compositional grammars that probe for limitations in the compositional inductive bias of frequently used models. We use these corrupted compositional grammars to compare and contrast a wide range of models, and to compare the choice of soft, Gumbel, and discrete representations. We propose a hierarchical model which might show an inductive bias towards relocatable atomic groups of tokens, thus potentially encouraging the emergence of words. We experiment with probing for the compositional inductive bias of sender and receiver networks in isolation, and also placed end-to-end, as an auto-encoder.
"This item is a glaxefw, and this is a glaxuzb": Compositionality Through Language Transmission, using Artificial Neural Networks
Jan 27, 2021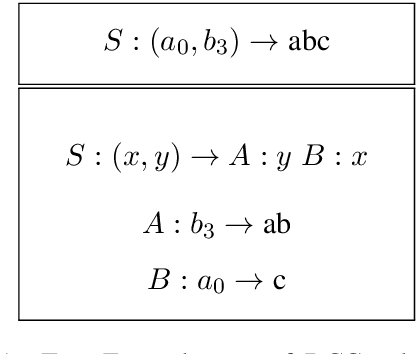

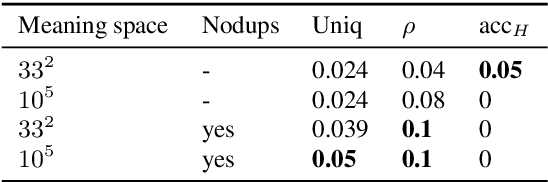
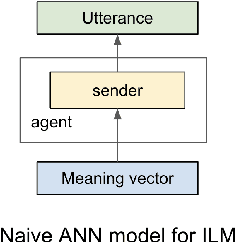
We propose an architecture and process for using the Iterated Learning Model ("ILM") for artificial neural networks. We show that ILM does not lead to the same clear compositionality as observed using DCGs, but does lead to a modest improvement in compositionality, as measured by holdout accuracy and topologic similarity. We show that ILM can lead to an anti-correlation between holdout accuracy and topologic rho. We demonstrate that ILM can increase compositionality when using non-symbolic high-dimensional images as input.
Dialog Intent Induction with Deep Multi-View Clustering
Aug 30, 2019
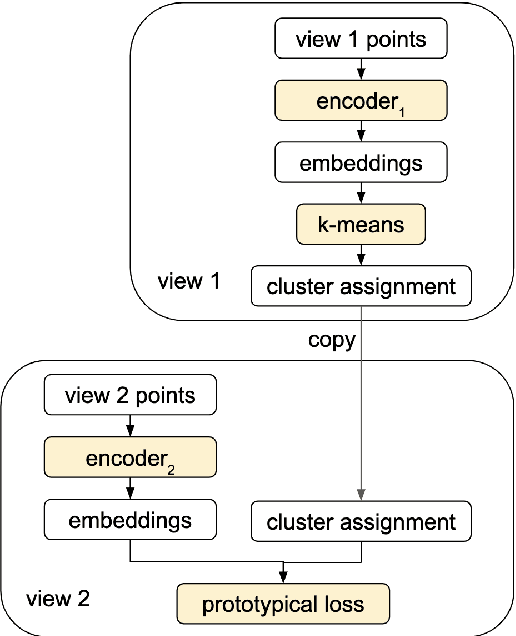
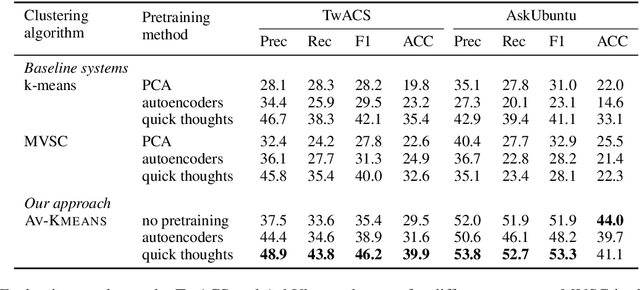
We introduce the dialog intent induction task and present a novel deep multi-view clustering approach to tackle the problem. Dialog intent induction aims at discovering user intents from user query utterances in human-human conversations such as dialogs between customer support agents and customers. Motivated by the intuition that a dialog intent is not only expressed in the user query utterance but also captured in the rest of the dialog, we split a conversation into two independent views and exploit multi-view clustering techniques for inducing the dialog intent. In particular, we propose alternating-view k-means (AV-KMEANS) for joint multi-view representation learning and clustering analysis. The key innovation is that the instance-view representations are updated iteratively by predicting the cluster assignment obtained from the alternative view, so that the multi-view representations of the instances lead to similar cluster assignments. Experiments on two public datasets show that AV-KMEANS can induce better dialog intent clusters than state-of-the-art unsupervised representation learning methods and standard multi-view clustering approaches.
cltorch: a Hardware-Agnostic Backend for the Torch Deep Neural Network Library, Based on OpenCL
Jun 15, 2016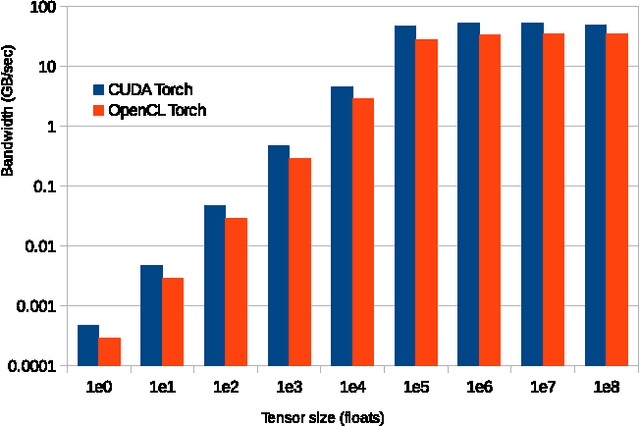
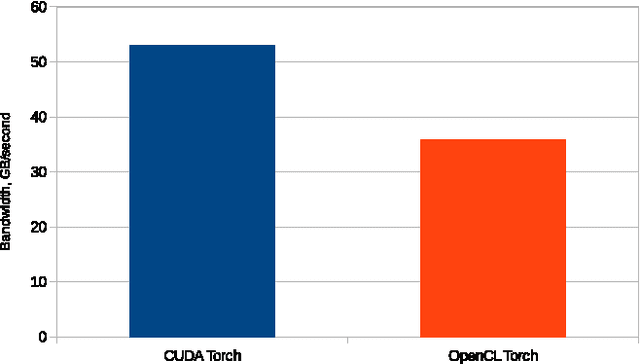

This paper presents cltorch, a hardware-agnostic backend for the Torch neural network framework. cltorch enables training of deep neural networks on GPUs from diverse hardware vendors, including AMD, NVIDIA, and Intel. cltorch contains sufficient implementation to run models such as AlexNet, VGG, Overfeat, and GoogleNet. It is written using the OpenCL language, a portable compute language, governed by the Khronos Group. cltorch is the top-ranked hardware-agnostic machine learning framework on Chintala's convnet-benchmarks page. This paper presents the technical challenges encountered whilst creating the cltorch backend for Torch, and looks in detail at the challenges related to obtaining a fast hardware-agnostic implementation. The convolutional layers are identified as the key area of focus for accelerating hardware-agnostic frameworks. Possible approaches to accelerating the convolutional implementation are identified including: implementation of the convolutions using the implicitgemm or winograd algorithm, using a GEMM implementation adapted to the geometries associated with the convolutional algorithm, or using a pluggable hardware-specific convolutional implementation.
Fast Parallel SVM using Data Augmentation
Dec 24, 2015
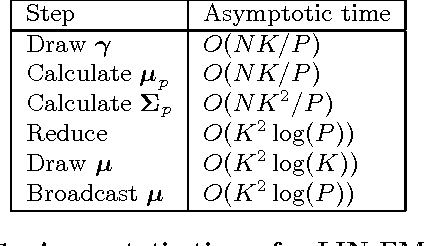

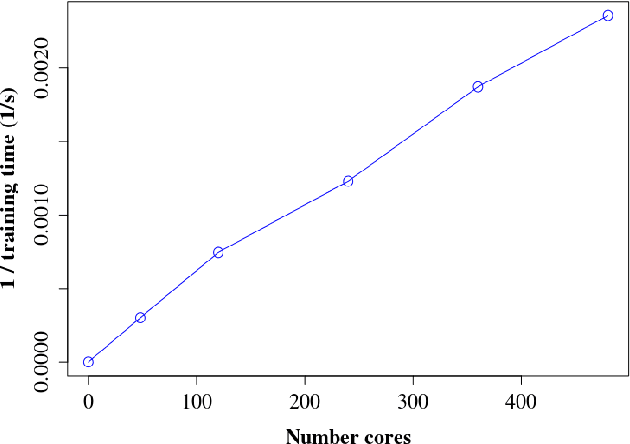
As one of the most popular classifiers, linear SVMs still have challenges in dealing with very large-scale problems, even though linear or sub-linear algorithms have been developed recently on single machines. Parallel computing methods have been developed for learning large-scale SVMs. However, existing methods rely on solving local sub-optimization problems. In this paper, we develop a novel parallel algorithm for learning large-scale linear SVM. Our approach is based on a data augmentation equivalent formulation, which casts the problem of learning SVM as a Bayesian inference problem, for which we can develop very efficient parallel sampling methods. We provide empirical results for this parallel sampling SVM, and provide extensions for SVR, non-linear kernels, and provide a parallel implementation of the Crammer and Singer model. This approach is very promising in its own right, and further is a very useful technique to parallelize a broader family of general maximum-margin models.
Gibbs Max-margin Topic Models with Data Augmentation
Oct 10, 2013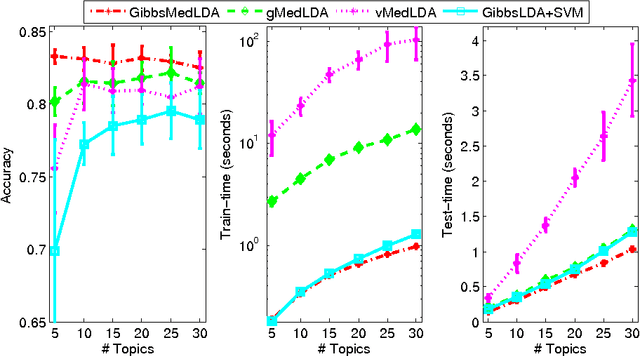
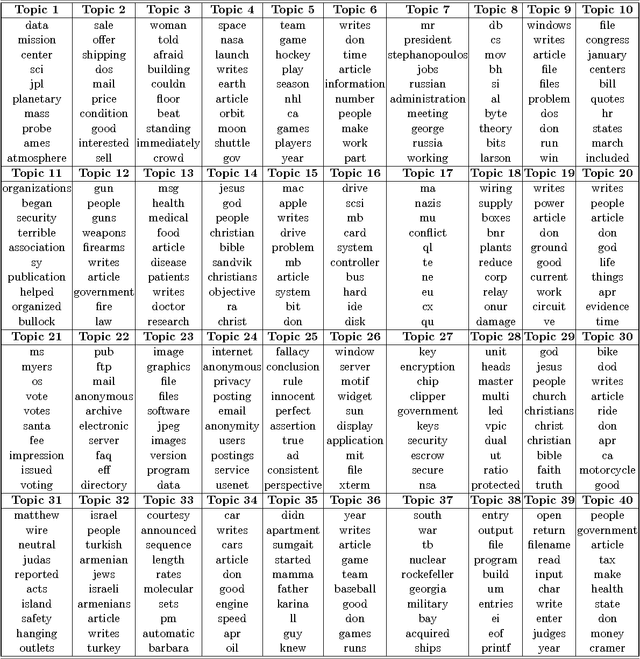
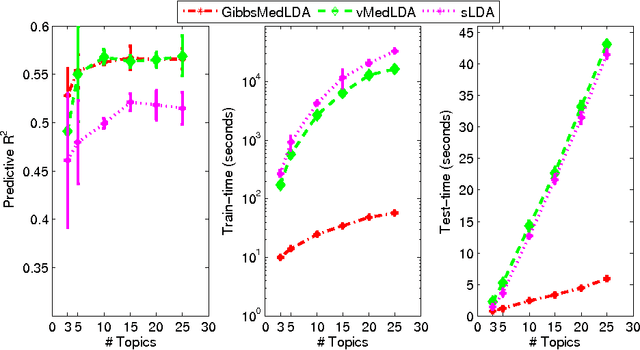
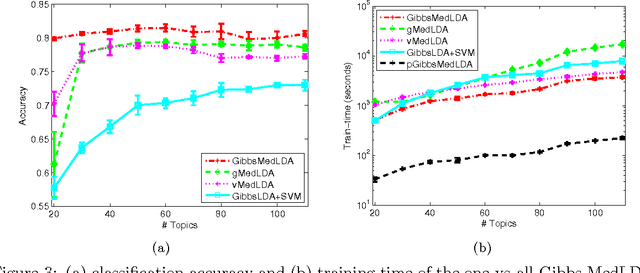
Max-margin learning is a powerful approach to building classifiers and structured output predictors. Recent work on max-margin supervised topic models has successfully integrated it with Bayesian topic models to discover discriminative latent semantic structures and make accurate predictions for unseen testing data. However, the resulting learning problems are usually hard to solve because of the non-smoothness of the margin loss. Existing approaches to building max-margin supervised topic models rely on an iterative procedure to solve multiple latent SVM subproblems with additional mean-field assumptions on the desired posterior distributions. This paper presents an alternative approach by defining a new max-margin loss. Namely, we present Gibbs max-margin supervised topic models, a latent variable Gibbs classifier to discover hidden topic representations for various tasks, including classification, regression and multi-task learning. Gibbs max-margin supervised topic models minimize an expected margin loss, which is an upper bound of the existing margin loss derived from an expected prediction rule. By introducing augmented variables and integrating out the Dirichlet variables analytically by conjugacy, we develop simple Gibbs sampling algorithms with no restricting assumptions and no need to solve SVM subproblems. Furthermore, each step of the "augment-and-collapse" Gibbs sampling algorithms has an analytical conditional distribution, from which samples can be easily drawn. Experimental results demonstrate significant improvements on time efficiency. The classification performance is also significantly improved over competitors on binary, multi-class and multi-label classification tasks.