 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edgecltorch: a Hardware-Agnostic Backend for the Torch Deep Neural Network Library, Based on OpenCL
Paper and Code
Jun 15, 2016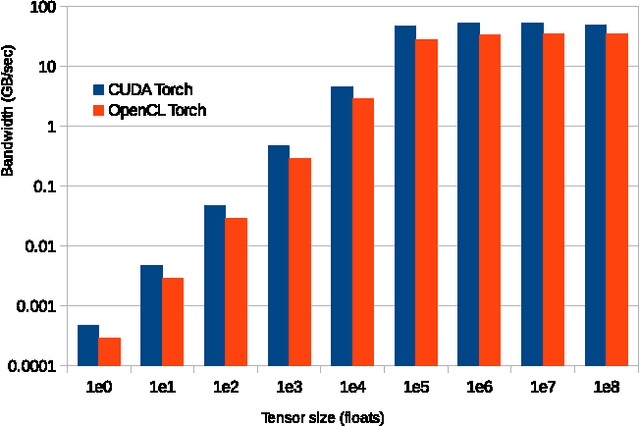
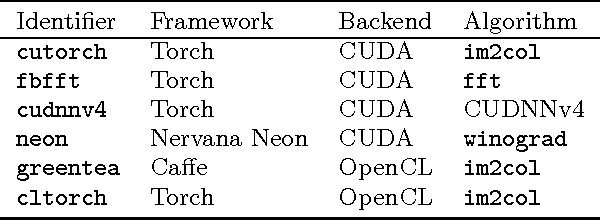
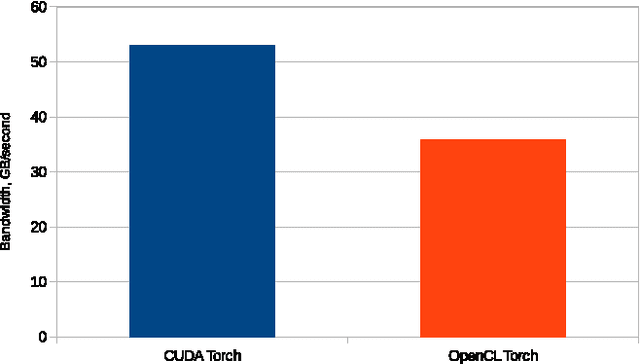

This paper presents cltorch, a hardware-agnostic backend for the Torch neural network framework. cltorch enables training of deep neural networks on GPUs from diverse hardware vendors, including AMD, NVIDIA, and Intel. cltorch contains sufficient implementation to run models such as AlexNet, VGG, Overfeat, and GoogleNet. It is written using the OpenCL language, a portable compute language, governed by the Khronos Group. cltorch is the top-ranked hardware-agnostic machine learning framework on Chintala's convnet-benchmarks page. This paper presents the technical challenges encountered whilst creating the cltorch backend for Torch, and looks in detail at the challenges related to obtaining a fast hardware-agnostic implementation. The convolutional layers are identified as the key area of focus for accelerating hardware-agnostic frameworks. Possible approaches to accelerating the convolutional implementation are identified including: implementation of the convolutions using the implicitgemm or winograd algorithm, using a GEMM implementation adapted to the geometries associated with the convolutional algorithm, or using a pluggable hardware-specific convolutional implementation.