 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn Alternative to FLOPS Regularization to Effectively Productionize SPLADE-Doc
May 21, 2025

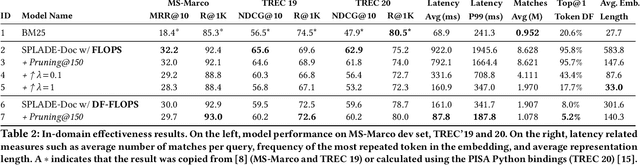

Learned Sparse Retrieval (LSR) models encode text as weighted term vectors, which need to be sparse to leverage inverted index structures during retrieval. SPLADE, the most popular LSR model, uses FLOPS regularization to encourage vector sparsity during training. However, FLOPS regularization does not ensure sparsity among terms - only within a given query or document. Terms with very high Document Frequencies (DFs) substantially increase latency in production retrieval engines, such as Apache Solr, due to their lengthy posting lists. To address the issue of high DFs, we present a new variant of FLOPS regularization: DF-FLOPS. This new regularization technique penalizes the usage of high-DF terms, thereby shortening posting lists and reducing retrieval latency. Unlike other inference-time sparsification methods, such as stopword removal, DF-FLOPS regularization allows for the selective inclusion of high-frequency terms in cases where the terms are truly salient. We find that DF-FLOPS successfully reduces the prevalence of high-DF terms and lowers retrieval latency (around 10x faster) in a production-grade engine while maintaining effectiveness both in-domain (only a 2.2-point drop in MRR@10) and cross-domain (improved performance in 12 out of 13 tasks on which we tested). With retrieval latencies on par with BM25, this work provides an important step towards making LSR practical for deployment in production-grade search engines.
Weakly Supervised Headline Dependency Parsing
Jan 25, 2023



English news headlines form a register with unique syntactic properties that have been documented in linguistics literature since the 1930s. However, headlines have received surprisingly little attention from the NLP syntactic parsing community. We aim to bridge this gap by providing the first news headline corpus of Universal Dependencies annotated syntactic dependency trees, which enables us to evaluate existing state-of-the-art dependency parsers on news headlines. To improve English news headline parsing accuracies, we develop a projection method to bootstrap silver training data from unlabeled news headline-article lead sentence pairs. Models trained on silver headline parses demonstrate significant improvements in performance over models trained solely on gold-annotated long-form texts. Ultimately, we find that, although projected silver training data improves parser performance across different news outlets, the improvement is moderated by constructions idiosyncratic to outlet.
* Findings of EMNLP 2022
Cross-Register Projection for Headline Part of Speech Tagging
Sep 15, 2021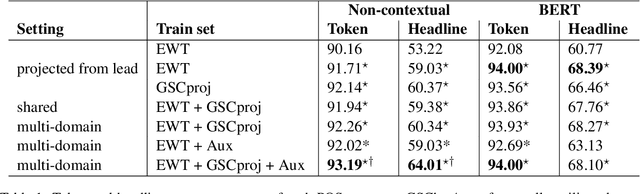
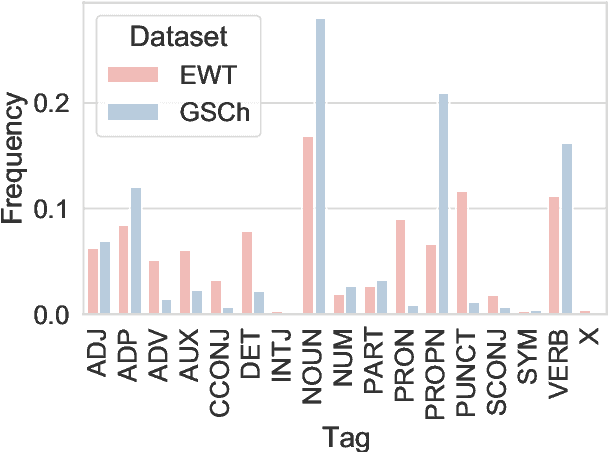

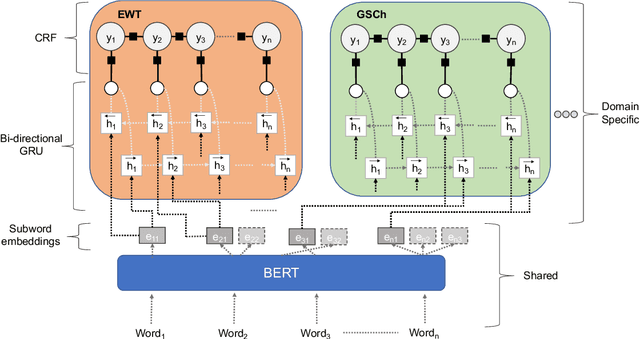
Part of speech (POS) tagging is a familiar NLP task. State of the art taggers routinely achieve token-level accuracies of over 97% on news body text, evidence that the problem is well understood. However, the register of English news headlines, "headlinese", is very different from the register of long-form text, causing POS tagging models to underperform on headlines. In this work, we automatically annotate news headlines with POS tags by projecting predicted tags from corresponding sentences in news bodies. We train a multi-domain POS tagger on both long-form and headline text and show that joint training on both registers improves over training on just one or naively concatenating training sets. We evaluate on a newly-annotated corpus of over 5,248 English news headlines from the Google sentence compression corpus, and show that our model yields a 23% relative error reduction per token and 19% per headline. In addition, we demonstrate that better headline POS tags can improve the performance of a syntax-based open information extraction system. We make POSH, the POS-tagged Headline corpus, available to encourage research in improved NLP models for news headlines.
Diversity-Aware Batch Active Learning for Dependency Parsing
Apr 28, 2021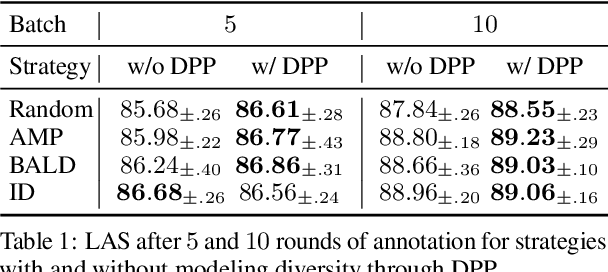
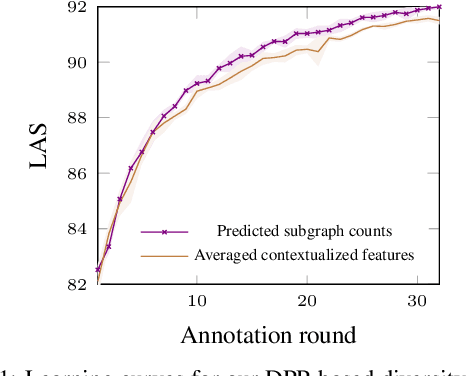
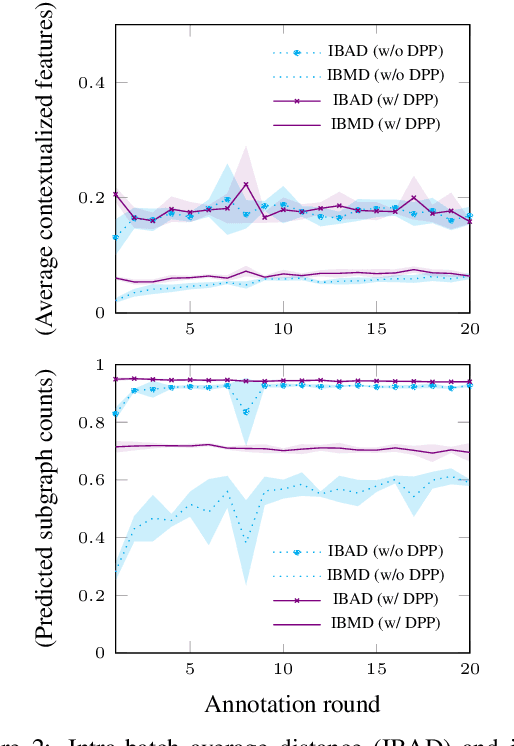
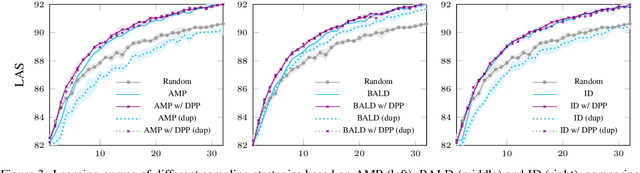
While the predictive performance of modern statistical dependency parsers relies heavily on the availability of expensive expert-annotated treebank data, not all annotations contribute equally to the training of the parsers. In this paper, we attempt to reduce the number of labeled examples needed to train a strong dependency parser using batch active learning (AL). In particular, we investigate whether enforcing diversity in the sampled batches, using determinantal point processes (DPPs), can improve over their diversity-agnostic counterparts. Simulation experiments on an English newswire corpus show that selecting diverse batches with DPPs is superior to strong selection strategies that do not enforce batch diversity, especially during the initial stages of the learning process. Additionally, our diversityaware strategy is robust under a corpus duplication setting, where diversity-agnostic sampling strategies exhibit significant degradation.
* NAACL 2021
Learning Syntax from Naturally-Occurring Bracketings
Apr 28, 2021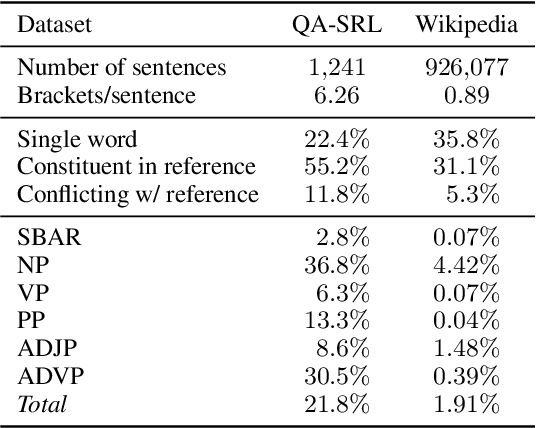
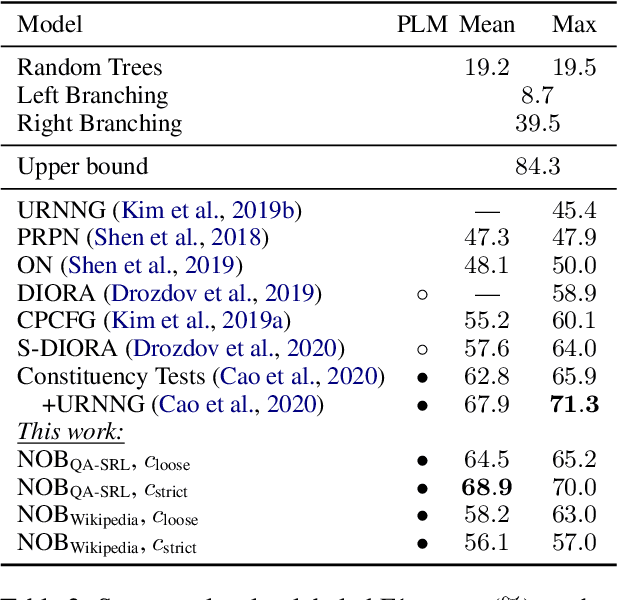
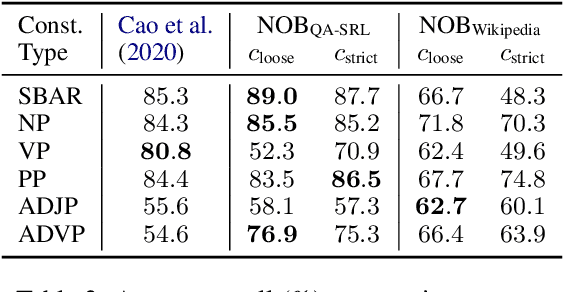
Naturally-occurring bracketings, such as answer fragments to natural language questions and hyperlinks on webpages, can reflect human syntactic intuition regarding phrasal boundaries. Their availability and approximate correspondence to syntax make them appealing as distant information sources to incorporate into unsupervised constituency parsing. But they are noisy and incomplete; to address this challenge, we develop a partial-brackets-aware structured ramp loss in learning. Experiments demonstrate that our distantly-supervised models trained on naturally-occurring bracketing data are more accurate in inducing syntactic structures than competing unsupervised systems. On the English WSJ corpus, our models achieve an unlabeled F1 score of 68.9 for constituency parsing.
* NAACL 2021
Semantic Role Labeling as Syntactic Dependency Parsing
Oct 21, 2020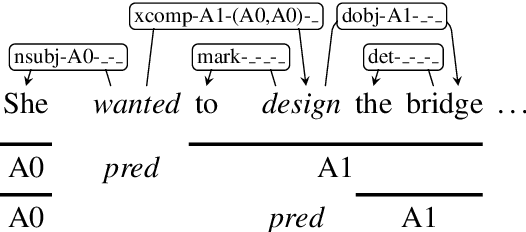
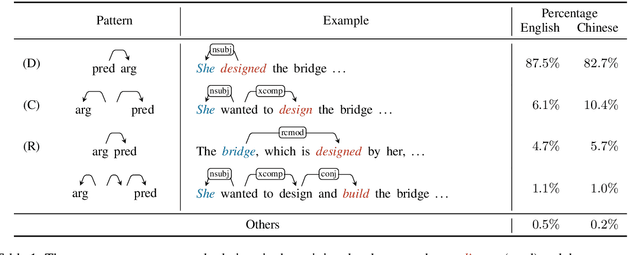
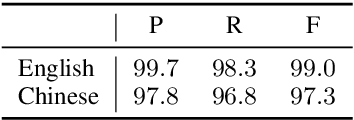
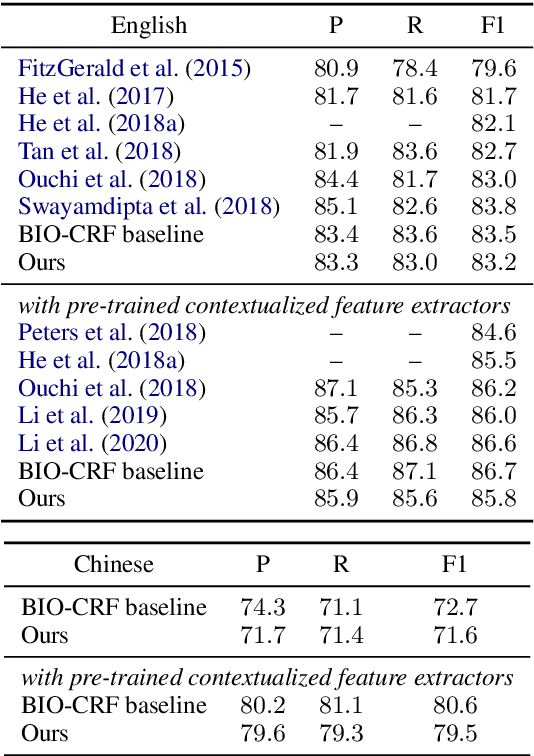
We reduce the task of (span-based) PropBank-style semantic role labeling (SRL) to syntactic dependency parsing. Our approach is motivated by our empirical analysis that shows three common syntactic patterns account for over 98% of the SRL annotations for both English and Chinese data. Based on this observation, we present a conversion scheme that packs SRL annotations into dependency tree representations through joint labels that permit highly accurate recovery back to the original format. This representation allows us to train statistical dependency parsers to tackle SRL and achieve competitive performance with the current state of the art. Our findings show the promise of syntactic dependency trees in encoding semantic role relations within their syntactic domain of locality, and point to potential further integration of syntactic methods into semantic role labeling in the future.
NSTM: Real-Time Query-Driven News Overview Composition at Bloomberg
Jun 01, 2020

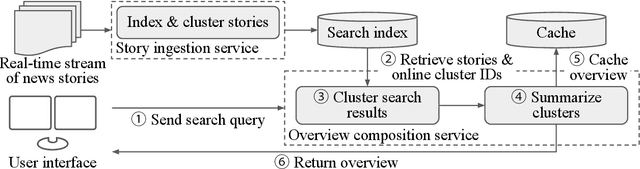

Millions of news articles from hundreds of thousands of sources around the globe appear in news aggregators every day. Consuming such a volume of news presents an almost insurmountable challenge. For example, a reader searching on Bloomberg's system for news about the U.K. would find 10,000 articles on a typical day. Apple Inc., the world's most journalistically covered company, garners around 1,800 news articles a day. We realized that a new kind of summarization engine was needed, one that would condense large volumes of news into short, easy to absorb points. The system would filter out noise and duplicates to identify and summarize key news about companies, countries or markets. When given a user query, Bloomberg's solution, Key News Themes (or NSTM), leverages state-of-the-art semantic clustering techniques and novel summarization methods to produce comprehensive, yet concise, digests to dramatically simplify the news consumption process. NSTM is available to hundreds of thousands of readers around the world and serves thousands of requests daily with sub-second latency. At ACL 2020, we will present a demo of NSTM.