 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHanging in the Balance: Pivotal Moments in Crisis Counseling Conversations
Jun 04, 2025During a conversation, there can come certain moments where its outcome hangs in the balance. In these pivotal moments, how one responds can put the conversation on substantially different trajectories leading to significantly different outcomes. Systems that can detect when such moments arise could assist conversationalists in domains with highly consequential outcomes, such as mental health crisis counseling. In this work, we introduce an unsupervised computational method for detecting such pivotal moments as they happen, in an online fashion. Our approach relies on the intuition that a moment is pivotal if our expectation of the outcome varies widely depending on what might be said next. By applying our method to crisis counseling conversations, we first validate it by showing that it aligns with human perception -- counselors take significantly longer to respond during moments detected by our method -- and with the eventual conversational trajectory -- which is more likely to change course at these times. We then use our framework to explore the relation of the counselor's response during pivotal moments with the eventual outcome of the session.
Taking a turn for the better: Conversation redirection throughout the course of mental-health therapy
Oct 09, 2024



Mental-health therapy involves a complex conversation flow in which patients and therapists continuously negotiate what should be talked about next. For example, therapists might try to shift the conversation's direction to keep the therapeutic process on track and avoid stagnation, or patients might push the discussion towards issues they want to focus on. How do such patient and therapist redirections relate to the development and quality of their relationship? To answer this question, we introduce a probabilistic measure of the extent to which a certain utterance immediately redirects the flow of the conversation, accounting for both the intention and the actual realization of such a change. We apply this new measure to characterize the development of patient-therapist relationships over multiple sessions in a very large, widely-used online therapy platform. Our analysis reveals that (1) patient control of the conversation's direction generally increases relative to that of the therapist as their relationship progresses; and (2) patients who have less control in the first few sessions are significantly more likely to eventually express dissatisfaction with their therapist and terminate the relationship.
Do Androids Laugh at Electric Sheep? Humor "Understanding" Benchmarks from The New Yorker Caption Contest
Sep 13, 2022

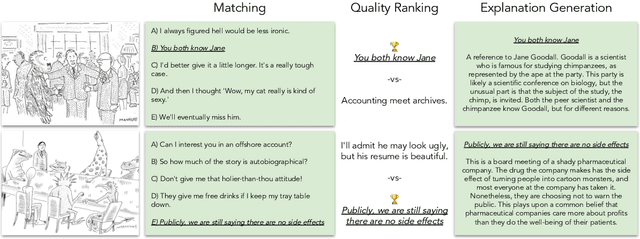
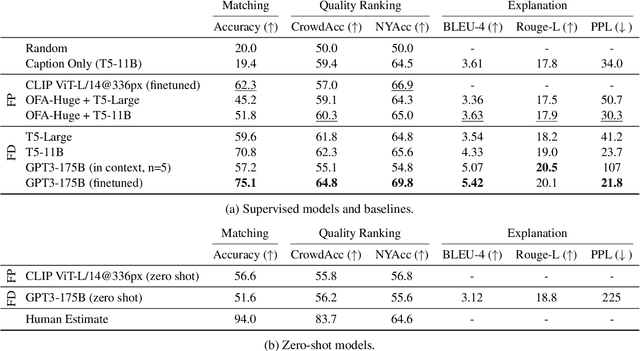
We challenge AI models to "demonstrate understanding" of the sophisticated multimodal humor of The New Yorker Caption Contest. Concretely, we develop three carefully circumscribed tasks for which it suffices (but is not necessary) to grasp potentially complex and unexpected relationships between image and caption, and similarly complex and unexpected allusions to the wide varieties of human experience; these are the hallmarks of a New Yorker-caliber cartoon. We investigate vision-and-language models that take as input the cartoon pixels and caption directly, as well as language-only models for which we circumvent image-processing by providing textual descriptions of the image. Even with the rich multifaceted annotations we provide for the cartoon images, we identify performance gaps between high-quality machine learning models (e.g., a fine-tuned, 175B parameter language model) and humans. We publicly release our corpora including annotations describing the image's locations/entities, what's unusual about the scene, and an explanation of the joke.
TGIF: Tree-Graph Integrated-Format Parser for Enhanced UD with Two-Stage Generic- to Individual-Language Finetuning
Jul 14, 2021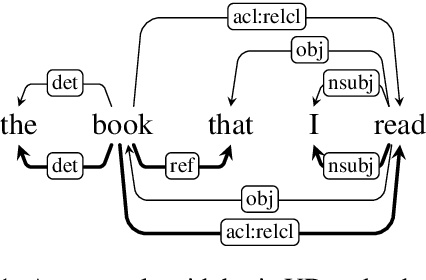
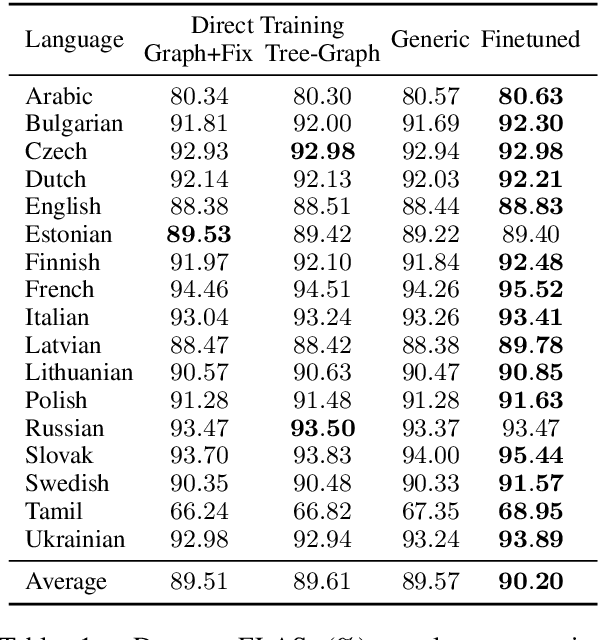
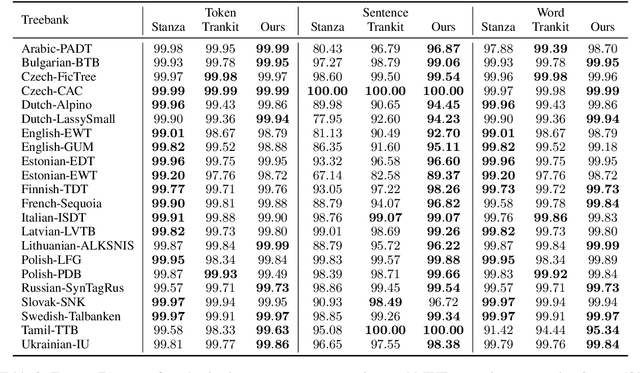
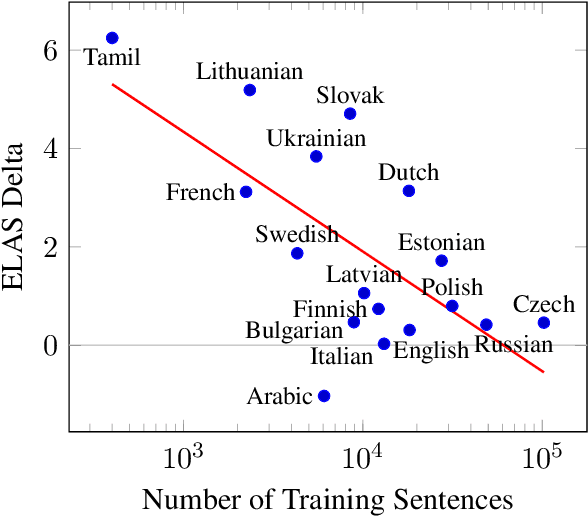
We present our contribution to the IWPT 2021 shared task on parsing into enhanced Universal Dependencies. Our main system component is a hybrid tree-graph parser that integrates (a) predictions of spanning trees for the enhanced graphs with (b) additional graph edges not present in the spanning trees. We also adopt a finetuning strategy where we first train a language-generic parser on the concatenation of data from all available languages, and then, in a second step, finetune on each individual language separately. Additionally, we develop our own complete set of pre-processing modules relevant to the shared task, including tokenization, sentence segmentation, and multiword token expansion, based on pre-trained XLM-R models and our own pre-training of character-level language models. Our submission reaches a macro-average ELAS of 89.24 on the test set. It ranks top among all teams, with a margin of more than 2 absolute ELAS over the next best-performing submission, and best score on 16 out of 17 languages.
* IWPT 2021 Shared Task
Transition-based Bubble Parsing: Improvements on Coordination Structure Prediction
Jul 14, 2021



We propose a transition-based bubble parser to perform coordination structure identification and dependency-based syntactic analysis simultaneously. Bubble representations were proposed in the formal linguistics literature decades ago; they enhance dependency trees by encoding coordination boundaries and internal relationships within coordination structures explicitly. In this paper, we introduce a transition system and neural models for parsing these bubble-enhanced structures. Experimental results on the English Penn Treebank and the English GENIA corpus show that our parsers beat previous state-of-the-art approaches on the task of coordination structure prediction, especially for the subset of sentences with complex coordination structures.
* ACL 2021
Learning Syntax from Naturally-Occurring Bracketings
Apr 28, 2021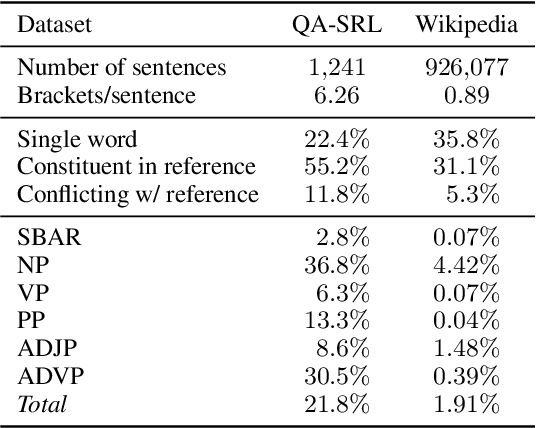
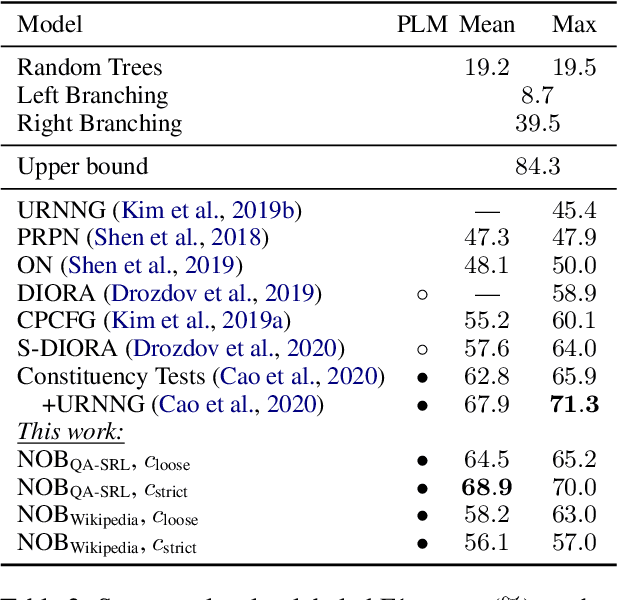
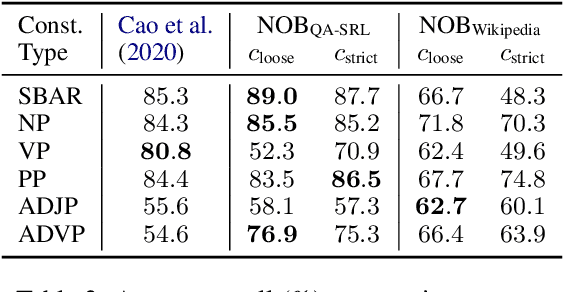
Naturally-occurring bracketings, such as answer fragments to natural language questions and hyperlinks on webpages, can reflect human syntactic intuition regarding phrasal boundaries. Their availability and approximate correspondence to syntax make them appealing as distant information sources to incorporate into unsupervised constituency parsing. But they are noisy and incomplete; to address this challenge, we develop a partial-brackets-aware structured ramp loss in learning. Experiments demonstrate that our distantly-supervised models trained on naturally-occurring bracketing data are more accurate in inducing syntactic structures than competing unsupervised systems. On the English WSJ corpus, our models achieve an unlabeled F1 score of 68.9 for constituency parsing.
* NAACL 2021
On the Potential of Lexico-logical Alignments for Semantic Parsing to SQL Queries
Oct 21, 2020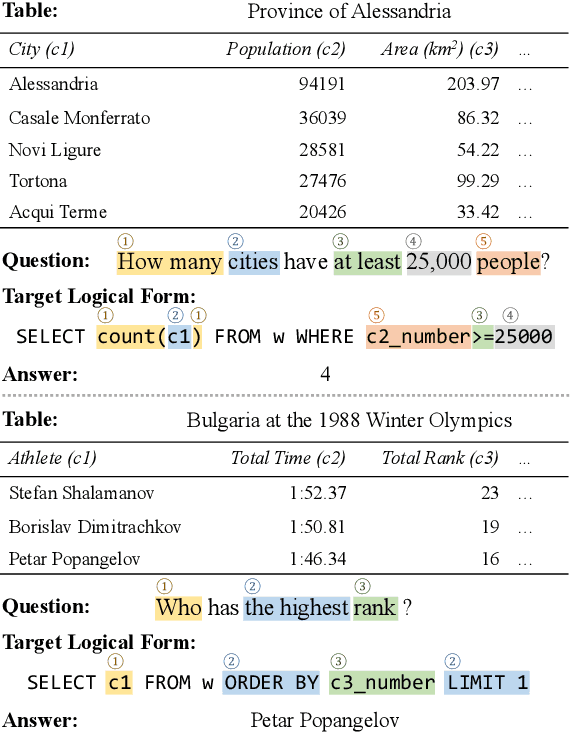
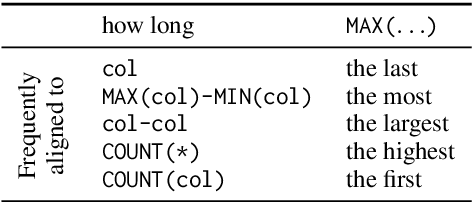
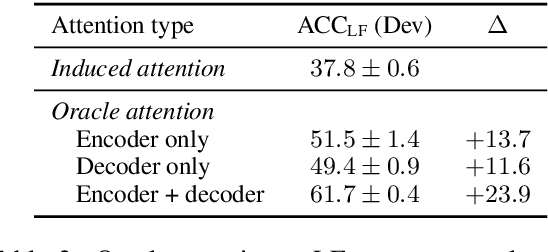
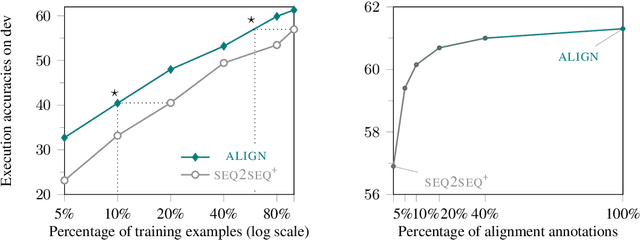
Large-scale semantic parsing datasets annotated with logical forms have enabled major advances in supervised approaches. But can richer supervision help even more? To explore the utility of fine-grained, lexical-level supervision, we introduce Squall, a dataset that enriches 11,276 WikiTableQuestions English-language questions with manually created SQL equivalents plus alignments between SQL and question fragments. Our annotation enables new training possibilities for encoder-decoder models, including approaches from machine translation previously precluded by the absence of alignments. We propose and test two methods: (1) supervised attention; (2) adopting an auxiliary objective of disambiguating references in the input queries to table columns. In 5-fold cross validation, these strategies improve over strong baselines by 4.4% execution accuracy. Oracle experiments suggest that annotated alignments can support further accuracy gains of up to 23.9%.
* Findings of ACL: EMNLP 2020
Does my multimodal model learn cross-modal interactions? It's harder to tell than you might think!
Oct 13, 2020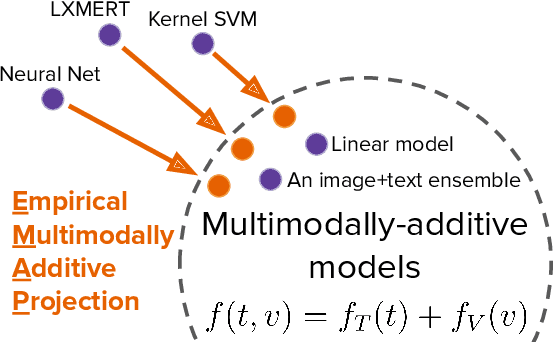



Modeling expressive cross-modal interactions seems crucial in multimodal tasks, such as visual question answering. However, sometimes high-performing black-box algorithms turn out to be mostly exploiting unimodal signals in the data. We propose a new diagnostic tool, empirical multimodally-additive function projection (EMAP), for isolating whether or not cross-modal interactions improve performance for a given model on a given task. This function projection modifies model predictions so that cross-modal interactions are eliminated, isolating the additive, unimodal structure. For seven image+text classification tasks (on each of which we set new state-of-the-art benchmarks), we find that, in many cases, removing cross-modal interactions results in little to no performance degradation. Surprisingly, this holds even when expressive models, with capacity to consider interactions, otherwise outperform less expressive models; thus, performance improvements, even when present, often cannot be attributed to consideration of cross-modal feature interactions. We hence recommend that researchers in multimodal machine learning report the performance not only of unimodal baselines, but also the EMAP of their best-performing model.
Extracting Headless MWEs from Dependency Parse Trees: Parsing, Tagging, and Joint Modeling Approaches
May 06, 2020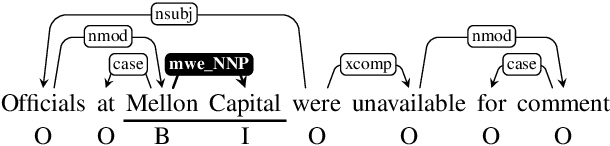
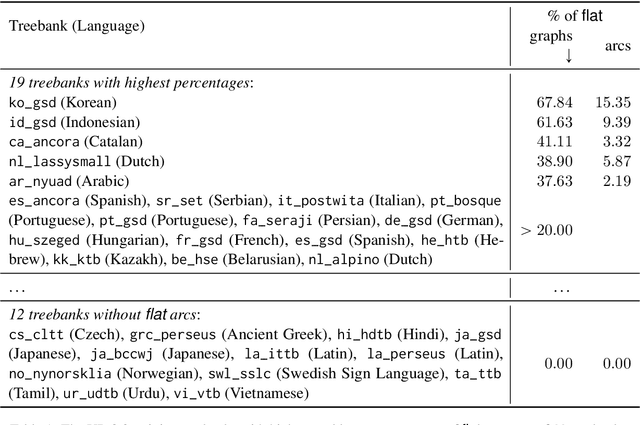
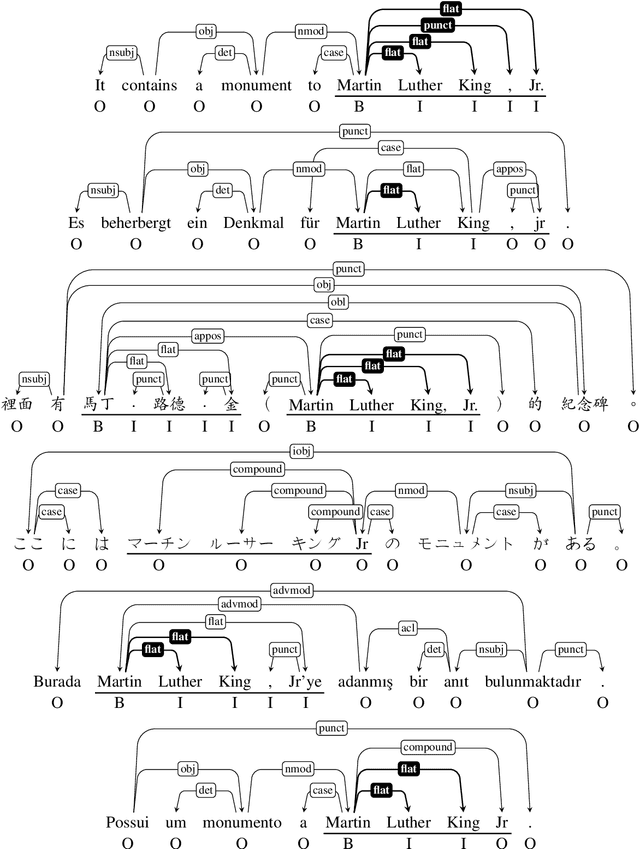
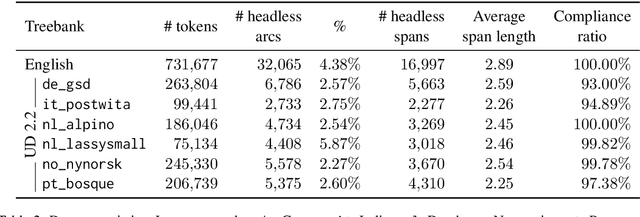
An interesting and frequent type of multi-word expression (MWE) is the headless MWE, for which there are no true internal syntactic dominance relations; examples include many named entities ("Wells Fargo") and dates ("July 5, 2020") as well as certain productive constructions ("blow for blow", "day after day"). Despite their special status and prevalence, current dependency-annotation schemes require treating such flat structures as if they had internal syntactic heads, and most current parsers handle them in the same fashion as headed constructions. Meanwhile, outside the context of parsing, taggers are typically used for identifying MWEs, but taggers might benefit from structural information. We empirically compare these two common strategies--parsing and tagging--for predicting flat MWEs. Additionally, we propose an efficient joint decoding algorithm that combines scores from both strategies. Experimental results on the MWE-Aware English Dependency Corpus and on six non-English dependency treebanks with frequent flat structures show that: (1) tagging is more accurate than parsing for identifying flat-structure MWEs, (2) our joint decoder reconciles the two different views and, for non-BERT features, leads to higher accuracies, and (3) most of the gains result from feature sharing between the parsers and taggers.
* Proceedings of ACL, 2020
Content Removal as a Moderation Strategy: Compliance and Other Outcomes in the ChangeMyView Community
Oct 21, 2019

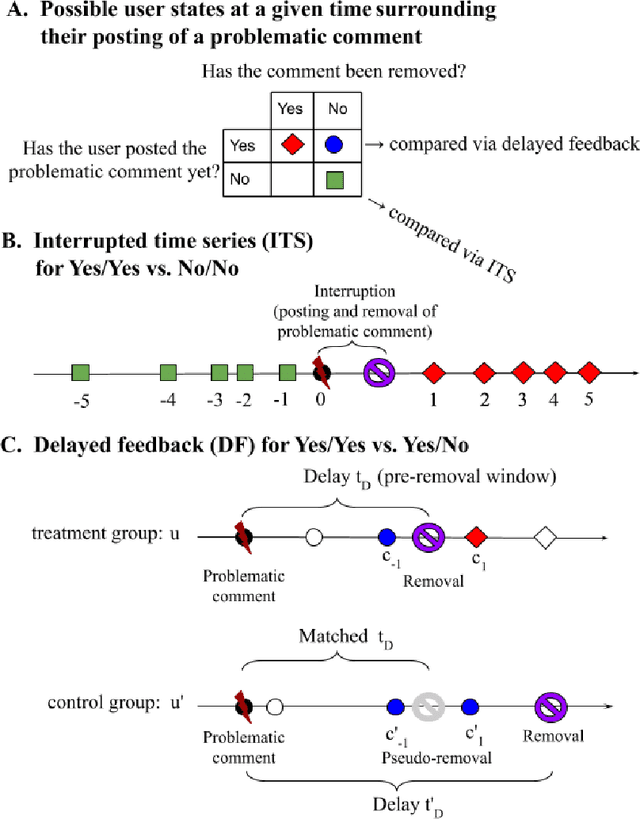
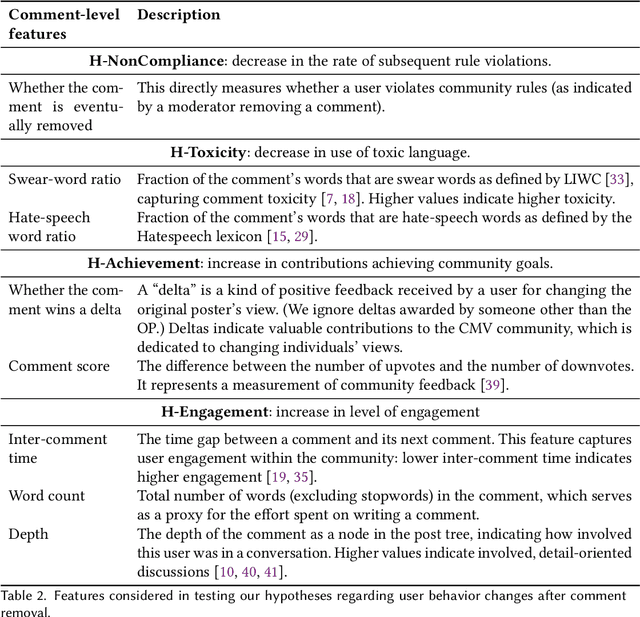
Moderators of online communities often employ comment deletion as a tool. We ask here whether, beyond the positive effects of shielding a community from undesirable content, does comment removal actually cause the behavior of the comment's author to improve? We examine this question in a particularly well-moderated community, the ChangeMyView subreddit. The standard analytic approach of interrupted time-series analysis unfortunately cannot answer this question of causality because it fails to distinguish the effect of having made a non-compliant comment from the effect of being subjected to moderator removal of that comment. We therefore leverage a "delayed feedback" approach based on the observation that some users may remain active between the time when they posted the non-compliant comment and the time when that comment is deleted. Applying this approach to such users, we reveal the causal role of comment deletion in reducing immediate noncompliance rates, although we do not find evidence of it having a causal role in inducing other behavior improvements. Our work thus empirically demonstrates both the promise and some potential limits of content removal as a positive moderation strategy, and points to future directions for identifying causal effects from observational data.