 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHumor in AI: Massive Scale Crowd-Sourced Preferences and Benchmarks for Cartoon Captioning
Jun 15, 2024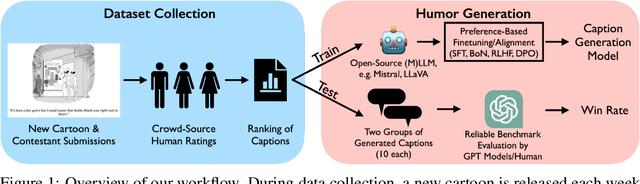

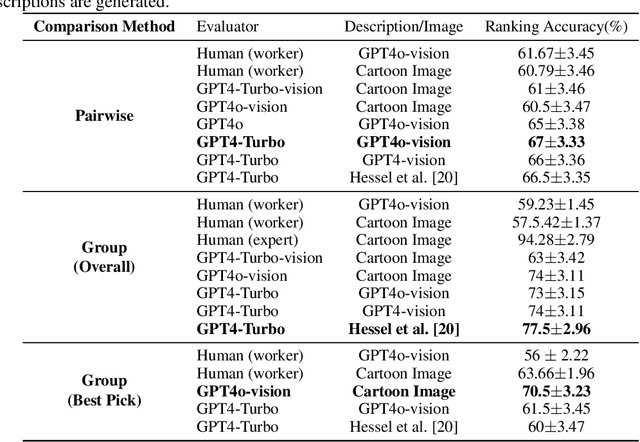
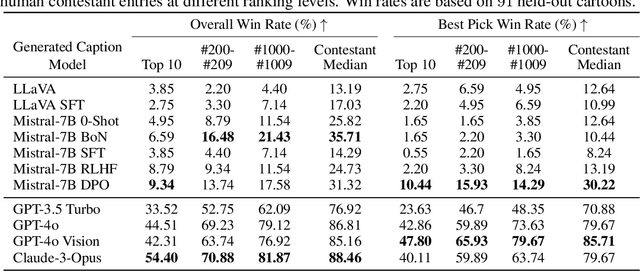
We present a novel multimodal preference dataset for creative tasks, consisting of over 250 million human ratings on more than 2.2 million captions, collected through crowdsourcing rating data for The New Yorker's weekly cartoon caption contest over the past eight years. This unique dataset supports the development and evaluation of multimodal large language models and preference-based fine-tuning algorithms for humorous caption generation. We propose novel benchmarks for judging the quality of model-generated captions, utilizing both GPT4 and human judgments to establish ranking-based evaluation strategies. Our experimental results highlight the limitations of current fine-tuning methods, such as RLHF and DPO, when applied to creative tasks. Furthermore, we demonstrate that even state-of-the-art models like GPT4 and Claude currently underperform top human contestants in generating humorous captions. As we conclude this extensive data collection effort, we release the entire preference dataset to the research community, fostering further advancements in AI humor generation and evaluation.
Do Androids Laugh at Electric Sheep? Humor "Understanding" Benchmarks from The New Yorker Caption Contest
Sep 13, 2022

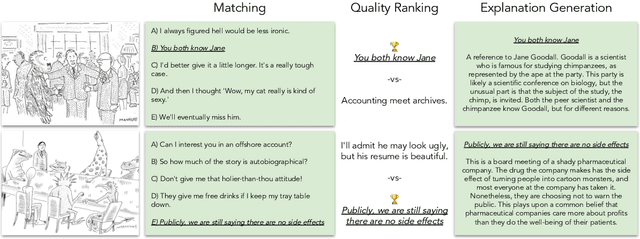
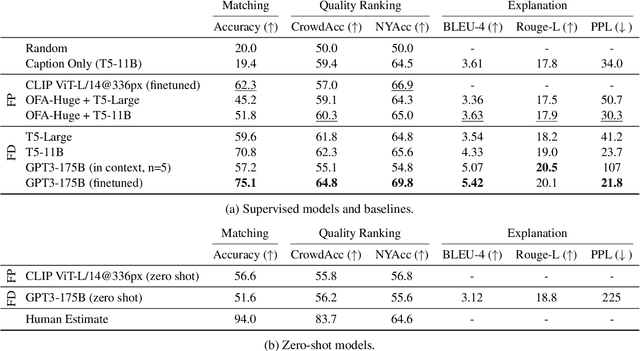
We challenge AI models to "demonstrate understanding" of the sophisticated multimodal humor of The New Yorker Caption Contest. Concretely, we develop three carefully circumscribed tasks for which it suffices (but is not necessary) to grasp potentially complex and unexpected relationships between image and caption, and similarly complex and unexpected allusions to the wide varieties of human experience; these are the hallmarks of a New Yorker-caliber cartoon. We investigate vision-and-language models that take as input the cartoon pixels and caption directly, as well as language-only models for which we circumvent image-processing by providing textual descriptions of the image. Even with the rich multifaceted annotations we provide for the cartoon images, we identify performance gaps between high-quality machine learning models (e.g., a fine-tuned, 175B parameter language model) and humans. We publicly release our corpora including annotations describing the image's locations/entities, what's unusual about the scene, and an explanation of the joke.